歡迎來到眼見未必為真的世界!最近新聞熱烈報導的 AI 繪圖「Midjourney」以人類名字參加美術展而且還獲獎!AI 自己產生的繪圖作品打敗了人類的繪圖作品。「Midjourney」怎麼辦到的?先來看看「Midjourney」是怎麼產生圖片的。

—— 獲獎的「太空歌劇院」,出處:獲獎者 Jason Allen 在 Discord的貼文
Midjourney 是掛在 Discord 聊天室上的機器人,只要輸入 /imagine 後面接想要生成的圖片敘述(英文),機器人約 1 分鐘內就會生成 4 張圖片符合你敘述的圖片。
下圖是我們隨手輸入 heaven (天堂)的結果。

—— 出處:Midjourney 生成
同樣類似的服務有「Hugging Face」,這邊不用註冊,不過生成圖片的速度比較慢,試著輸入 fireworks(煙火) 的話是出現這四張圖。
—— 出處:Huggin Face 生成
這邊在註記圖片出處的時候猶豫了一下,用我們的關鍵字隨機生成的圖片,著作權算誰的呢?
之後在 AI×社會 篇章我們再來探討。
另外還有最近日本漫畫家們人心惶惶的「mimic」,只要給15~30張你想要模仿的漫畫家圖片,就可以生成該漫畫家風格的圖。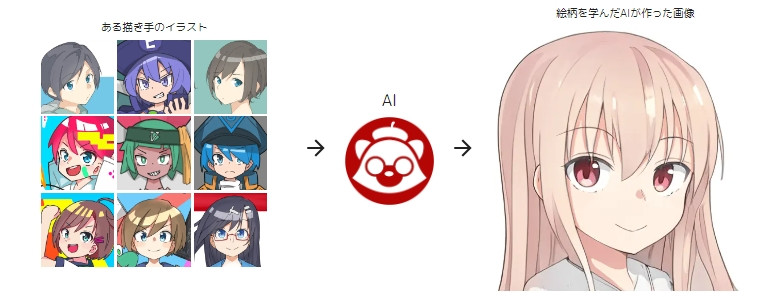
—— 出處:mimic 官網
難道漫畫家要失業了嗎?在這種恐慌下, mimic 2022/8/29 Release 之後隨即被漫畫家們在網路上集體抵制,目前官方提出避免被濫用的對策並暫時關閉服務,而正式服務什麼時候再開始還是未定。
上面運用的技術就是我們今天要介紹的生成模型,其中 Midjourney 採用的技術之一就是最熱門的 GAN。
能夠推斷圖片的資料分布,然後根據該分布去生成出和原本圖片類似的圖片資料稱作生成模型。今天介紹其中最廣為人知的兩個:
這兩個模型是透過不同的方法去取得圖片的潛在空間(latent space),然後再對這個空間的潛在變數(latent variable)做隨機取樣去生成新的圖片。
聽起來有點抽象對吧?這邊的潛在變數可以理解為圖片特徵的參數。如果有玩過遊戲的捏人臉系統就知道,遊戲的角色外貌可以透過各種參數做改變,如眼睛的大小,鼻子的高低,頭髮的顏色等等。
比如說這張圖片的笑容為其中一個特徵,笑的很開心參數接近 1。把這個笑容的數值水平滑動到接近-1就會變成比較生氣的臉,以此類推。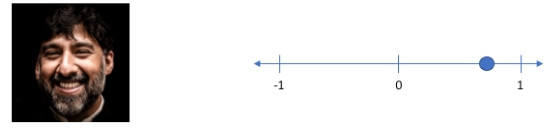
—— 出處:Variational autoencoders.
VAE 使用 Day 12 介紹過的自動編碼器,同樣有編碼器和解碼器,只是這次不是做壓縮和解壓縮資料。
編碼器
將原本的特徵資料變換成常態分布(平均和方差)。
以潛在變數來說,笑容的參數分布會變成這個樣子: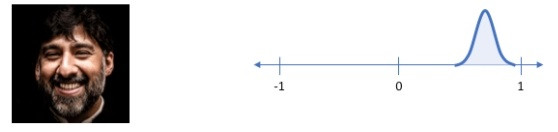
—— 出處:Variational autoencoders.
解碼器
針對常態分佈隨機取一點資料(Sampling)做為參數生成圖片。
透過這兩個過程來生成和原本不一樣但類似的新資料。
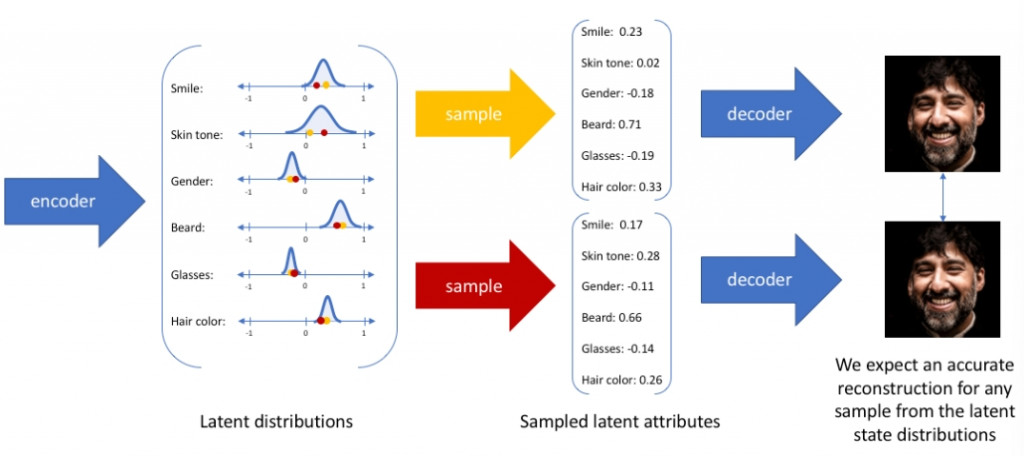
—— 出處:Variational autoencoders.
為了方便理解中間省略了統計學比較深入的東西,有興趣的人可以看看補充資料的論文。
GAN 主要由兩個獨立的神經網路做互相對抗,由一個生成器(Generator)生成新的圖片,另外一個鑑別器(Discriminator)來鑑別新的圖片是否為偽造的,所以叫生成對抗網路。
一個要騙人,一個要想辦法抓出破綻。
實際上的運作是這樣: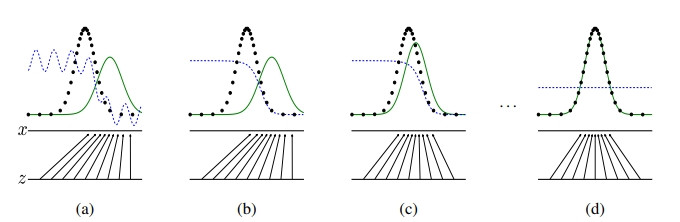
—— 出處:GAN 論文
黑點是真實資料分布,生成器從雜訊(黑箭頭)生成資料(綠線),藍點則是鑑別器的鑑別分布。
一開始需要鑑別器先做訓練,才能先提供有用的回饋給生成器生成資料。
將神經網路改用 CNN 實做 GAN 的模型叫做 DCGAN(Deep Convolutional GAN)。
生成的圖像更細緻,以下是透過 DCGAN 程式試著生成人臉的訓練過程視覺化:

—— 程式參考出處:Pytorch - DCGAN Face tutorial
一開始很明顯都是雜訊,然後逐一變成像真人的臉孔。
Pix2Pix是一種有條件的GAN,一開始會給GAN一個條件圖像和一個真實圖像。生成器不是用隨機雜訊而是透過條件圖像生成新的圖像。鑑別器則是辨別新圖像是否是真實的。

—— 出處:Pix2Pix 論文
缺點是必須準備一組成對的條件圖像(Input)和真實圖像(Ground truth)。
各種轉換成果:
—— 出處:Pix2Pix 論文
CycleGAN 是 pix2pix 的雙向版本。有兩個生成器和兩個鑑別器。比如說根據馬的圖片生成斑馬圖片和根據斑馬圖片生成馬的圖片,彼此循環鑑別所以叫 CycleGAN 。

—— 出處:CycleGAN 論文
CycleGAN 的好處是不需要準備成對的條件圖像和真實圖像。只需要很多馬的圖像和很多斑馬的圖像,就可以循環生成辨識真偽。



 iThome鐵人賽
iThome鐵人賽