今天讓我們從以下這篇文章的角度出發,藉由閱讀以及實際操作的過程,一起思考有什麼方式可以達成目的。
文章出處:https://towardsdatascience.com/machine-learning-with-datetime-feature-engineering-predicting-healthcare-appointment-no-shows-5e4ca3a85f96
由於五分之一的病人會在預定的時間缺席,不論對於病人自身、其他病人或是醫療服務提供者來說,都是一個不樂見的情形。
給定日期以及時間,預測病人是否會遲到或缺席。
例如小明預定上週五 17:00 預定這週二要洗牙,那麼 ScheduledDay 就是上週五的 17:00,而週一就是 AppointmentDay。
其餘部分在接下來的實作中,如有必要會特別提出說明。
讓我們回到先前的實作中,讀者們的資料夾內,目前應該是這個樣子: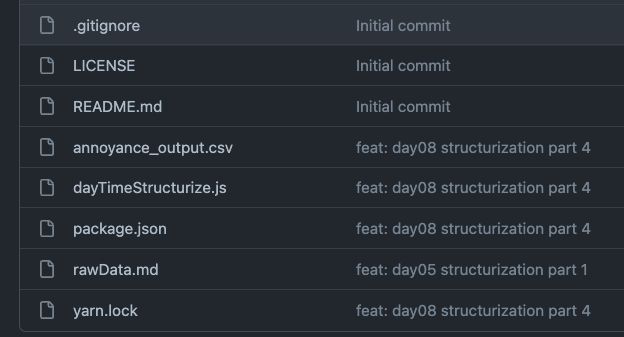
我們預計仍會在同一個專案中處理,不過為了更好區分結構化的部分以及預測的部分,讓我們建立兩個資料夾:
prediction
structurization
並且將除了 .gitignore、README.md、README.md 以外的檔案,搬移到 structurization中。
同時,讓我們在 prediction 從 structurization 複製一份 annoyance_output_manual.csv 過來,並命名為 annoyance_output_manual_for_predict.csv。
筆者對於 Python 較不熟悉,加上開始學習 Python 至今使用的這台電腦是 Apple M1 的 CPU,一開始在虛擬環境(印象中是這個環節)上碰到了一些問題(現在可能這些問題都已有解法)。最終是使用 Anaconda 來達到環境設置以及虛擬環境的效果。
為了方便,目前都還是使用 Anaconda 設置 Python 的環境。取捨就是 Anaconda 佔的空間較大,現在佔了大概 6 GB 左右的容量(兩個虛擬環境都是安裝訓練模型用的套件)。

如果容量有限的讀者不妨先研究選擇 venv 或是 virtualenv 等虛擬環境。
讓我們建置環境,在 Terminal 輸入:
conda create --name annoyance python=3.8
使用 python 3.8 是因為先前預測驗證碼的專案也同樣是使用 3.8,預期使用的套件差不多,所以仍選擇之。目前 3.8 安裝的是 3.8.13。
建置完成後啟動,在 Terminal 輸入:
conda activate annoyance
讓我們在 prediction 底下開一個 predict.py 檔。
最終的檔案結構長這樣: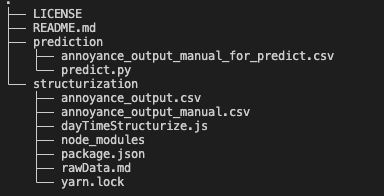
今天收工!

