注意 ! 注意力就是你所需要的!是不是目光馬上被「注意」兩個字吸引過來?這就是我們要的,讓模型注意每個當下的精采片段!今天的 Attention 和 Transformer 可以說是目前大放異彩的 GPT-3 的基石,雖然今天內容比較偏向理論,但精采度與重要性不變,明天會接著介紹實際的應用。
如同字面上解釋,幫助模型找出值得注意的地方,讓輸出的結果更精確。最早是活用在 Seq2Seq 的改善,之後也延伸到圖像領域。
前一篇講的 Seq2Seq 有個最大的問題是,編碼器最後的隱藏狀態是以固定長度的向量傳遞給解碼器,因此句子越長越難傳達必要的訊息。

ーー句子越長,各單詞的訊息占比就越小。出處:Illustrated Guide to Recurrent Neural Networks
而 Attention 可以透過時間的權重來注意每個單詞當下應注意的部分。
Seq2Seq 的 Attention 架構如下:
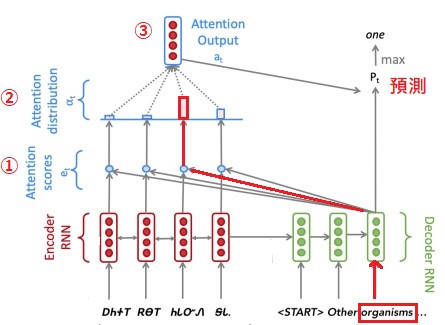
ーー原圖出處:CS 224n: Assignment #4
簡單來說就是解碼器當下的輸出預測,會根據權重知道要特別注意編碼器的哪個輸入部分。以上圖為例,第二個單字的「Organisms」會因為權重,知道要注意輸入的第三個字來預測下一個字。至於 Attention 實際上怎麼運作的,步驟如下:
最後使用 context vector 和 解碼器當下的狀態一起作預測。
讓當下的時間步驟可以注意到和自己最相關的輸入部分。
可以更直觀地透過 Attention 的權重來看機器翻譯的視覺化,下圖是英文翻法文,每個單詞相關性的權重,越黑越接近0表示相關性越低,反之,越白越接近1則相關性較高。

ーー出處:Neural Machine Translation by Jointly Learning to Align and Translate
在 Day 5 介紹過的歷屆 ILSVRC 冠軍中,2017年的 SENet 就是採用了 ResNet + SE Block(Attention,下圖右邊多出來的部分) 的架構。
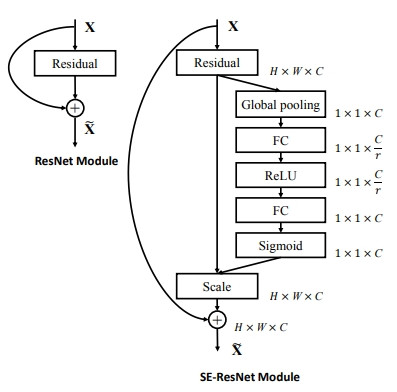
ーー出處:SENet 論文
透過了對通道(Channel)的注意,篩選出有力的特徵。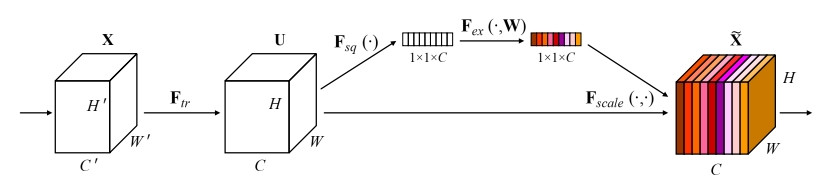
ーー出處:SENet 論文
凸顯出圖片應注意的部分。
ーー原圖出處:Channel Attention and Squeeze-and-Excitation Networks (SENet)
2017 年發表的一篇論文「注意力就是你所需要的」(Attention Is All You Need),捨棄 RNN 架構,採用兩種 Attention 架構解決了 RNN 的兩個問題:
不同的時間步驟 以 NLP 來看就是不同的單詞。
Transformer 架構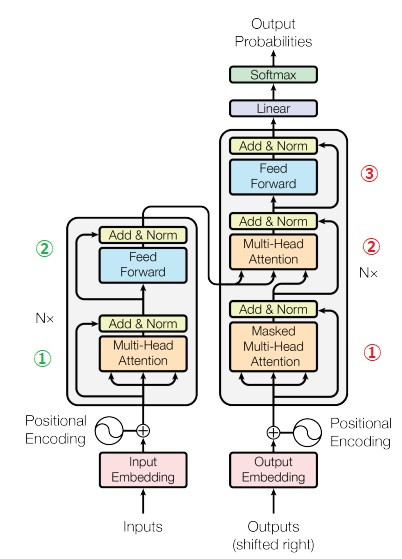
ーー原圖出處:Transformer 論文
看起來有點複雜,我們先簡化構造再逐項說明,如圖所示,左邊編碼器,右邊解碼器。
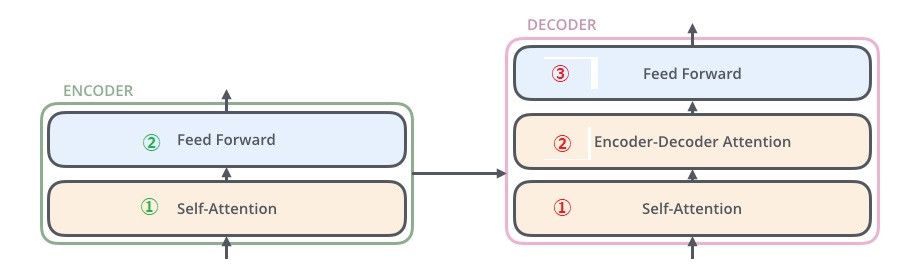
ーー原圖出處:illustrated-transformer
Masked Multi-Header Attention 做 自注意
計算 輸出它自己每個單詞之間的關聯度。無關順序可以同時處理加快速度。
由於解碼器是照順序預測,所以預測時不需計算該單詞和它之後的單詞(未來資料)之間的關聯度。因此多了遮罩(Mask)來蓋掉該位置之後的情報。
Multi-Header Attention 做 編碼器-解碼器注意
計算 輸出 和 輸入 之間單詞的關聯度。
類似 Seq2Seq 的 Attention,注意輸出和輸入的哪個部分有關聯。
Feed Forward
兩層的前饋神經網路,激勵函數用 ReLU 做學習。
上述編碼器和解碼器的步驟會 × N次。
Positional Encoding
編碼器和解碼器的自注意,由於只計算自己單詞之間的關係,沒有照順序處理,會失去單詞所在位置的情報,所以一開始會透過 位置編碼(Positional Encoding) 把位置的順序情報也編碼進去。
Add & Norm
每一步之後會做 Add & Norm, Add 是之前介紹過的 Residual(跳接兩個子層)。Norm 是 正規化(Normalization)
了解了大步驟之後,接下來再更細部地解釋各個注意是怎麼計算的。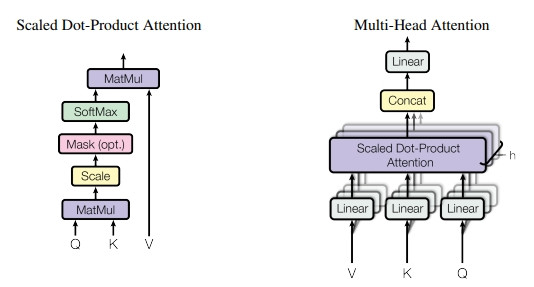
ーー出處:Transformer 論文
主要是透過 Scaled Dot-Product(內積)Attention 計算,和一般的 attention 差不多。只是細分成 Query,Key,Value(Q,K,V)。
Q = 某個時間步驟(單詞)
K = Q 作 attention 的對象,用來和 Q 做計算。
V = Q 作 attention 的對象,K 的原始值。
例如我們有個輸入:
The animal didn't cross the street because it was too tired.
(那個動物無法過馬路因為牠太累了)
可以透過自注意去確認 牠(it) 是指這句的哪個部分,比如說動物(animal)。
而多頭(Multi-Header)則透過隨機初始的 Linear 層的訓練,多去注意其他不同的東西。可以看出 牠(it) 不只注意到動物,還連結到累(tire)這個字。
ーー上述圖片均出自:illustrated-transformer
Transformer 的架構介紹就到這邊,之後又衍生出只用編碼器或只用解碼器的各種變形。
最後要注意的是,解碼器是照順序輸出預測,所以解碼器作預測時無法做同時處理。


 iThome鐵人賽
iThome鐵人賽