其主要優勢為架構內具有記憶神經元,可用於處理具有時間序列特性的數據,如進行文字處理,與先前提及的前饋神經網路相比,傳入RNN的訊號可在網路內反覆傳遞。RNN架構如下圖所示: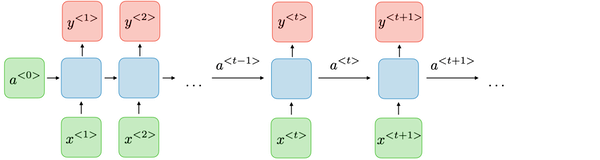
圖片來源:連結
其計算過程如下:
x為時間點t的輸入值
a為時間點t的hidden state,意即類神經網路內的架構。通常時間點0的hidden state會被設定為0,後續的hidden state計算時會使用tanh或Sigmoid等激勵函數進行轉換,增加其非線性程度。
y則為時間點t的輸出值
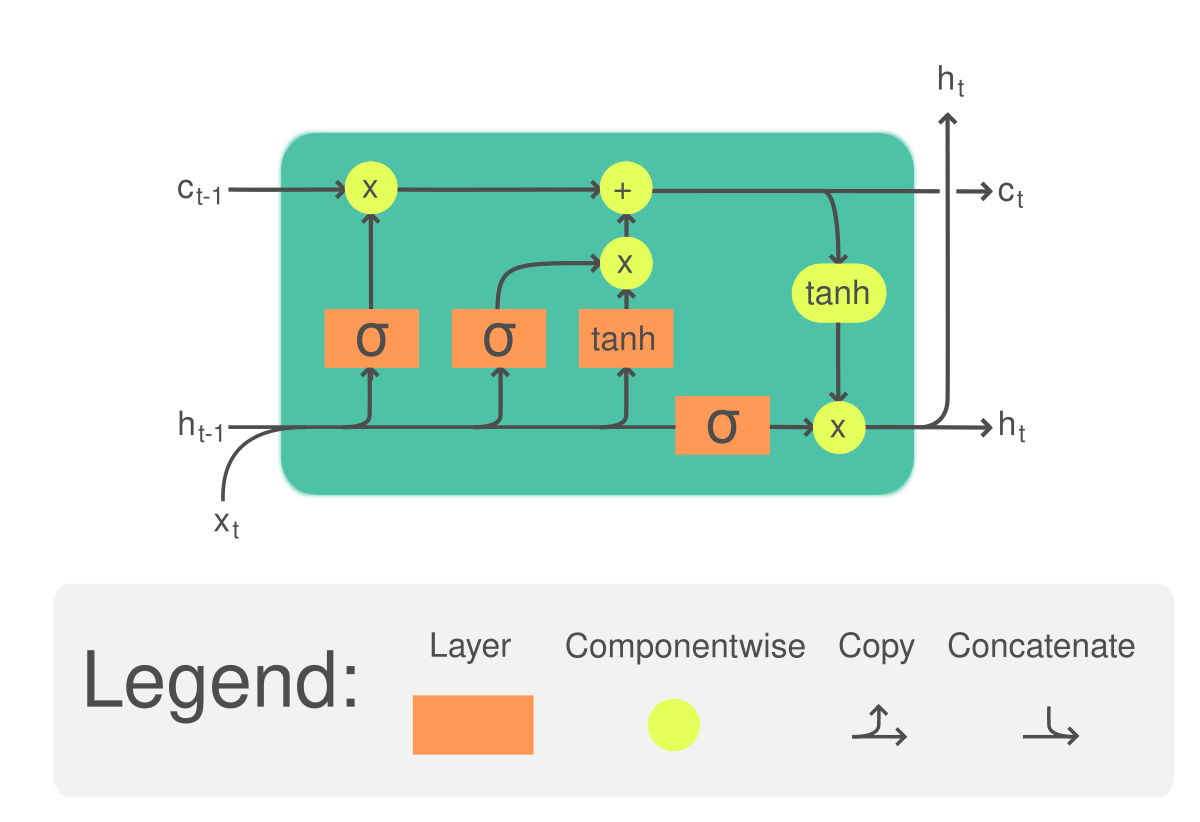
RNN具有梯度消失的缺點,為解決此問題,便誕生了RNN的變化型態 - LSTM,LSTM透過架構內的遺忘門(forget gate)選擇要保留或遺忘部分的資訊,使其可順利的進行梯度下降。與RNN僅能記憶前一個循環的運算結果相比,LSTM也可記憶兩個或更多循環以前的運算結果,使得預測的結果更加合理。LSTM架構圖如下所示:
圖片來源:連結

圖片來源:連結
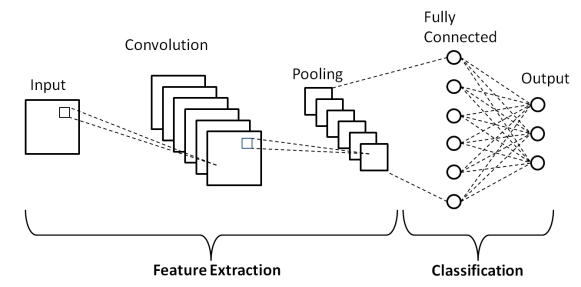
相較於RNN利用記憶前一個循環的運算結果來協助下一步的預測,CNN則是使用卷積(Convolution)的方式,架構內有過濾器(Filter)在資料內進行擷取,每進行一次新的擷取,過濾器便會移動一個步長(Stride)後進行擷取,產生一個特徵地圖(Feature Map),這樣的方式可以避免離群值過度影響預測結果。在特徵地圖產生後,可透過激勵函數對特徵地圖內的值進行篩選,例如使用ReLU將負值進行去除。
池化(Pooling)為減少資料量但同時保存特徵地圖中重要資訊的方法,常見的池化法包含最大池化法(Max Pooling)或平均池化法(Average Pooling),其作法顧名思義,便是取一特徵地圖特定範圍內的最大值或平均值,成為新的特徵矩陣,作法如下所示: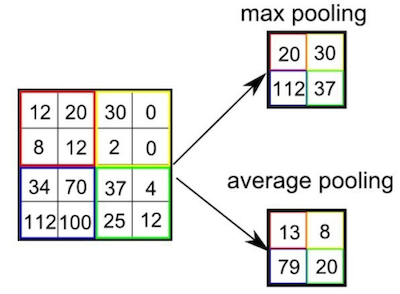
圖片來源:連結
CNN架構內可進行多次卷積與池化,最後經過全連接層後進行對資料分類或預測。


 iThome鐵人賽
iThome鐵人賽
{kind=link}
{kind=link}
{kind=link}
{kind=link}