在上篇文章提到Unity在train model使用的是Unity ML-Agents Toolkit,但我們之後會棄用,因為該Toolkit對於ML model與套件的選用有些限制。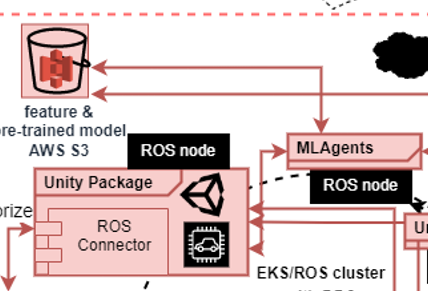
未來會以python來控制Unity Model的環境設定與action,
並使用socket or gRPC寫Unity Model training資料的匯出與python溝通。
等於我們自己create一個Agent取代mlagents:
class Agent():
def __init__(self, q_lr, pi_lr, gamma, rho, server, action_space, input_dims=17, n_actions=4, layer1_size=400, layer2_size=300, batch_size=100, chpt_dir='Model/DDPG'):
def update_network_parameters(self, rho=None):
def choose_actions(self, observation, init=0):
def learn(self):
def save_models(self, tag):
def load_models(self, tag):
以下我們使用Reinforcement Learning做為案例。
new_target = {'title': 'new target', 'content': {
'pos': {'x': self.target_pos[0], 'y': 0, 'z': self.target_pos[1]}}}
actions_msg = {'title': 'action', 'content': {'voltage': actions_}}
以上的過程透過一個socket thread(之後會改成grpc protobuf)將在Unity執行的結果訊息取出來,在Python中處理。程式碼如下:
obs = None
for i in range(100):
init = env.restart_episode(obs)
if init:
t = CustomThread(s) # socket thread
t.start()
t.join()
obs = t.message
obs = processFeature(obs, env.target_pos)
done = False
score = 0
while (not done):
actions = agent.choose_actions(obs)
reward, new_state, done = env.step(obs)
score += reward
obs = new_state.copy()
(以上為成大學生嘉軒提供)

