昨天我們認識 Pinterest 使用 PinSage 演算法,將每個 pin 和 board 轉成 embedding。不過,只是轉成 embedding 還不足以構築推薦系統,今天來介紹 Pinterest 的推薦系統 PinnerSage 吧!
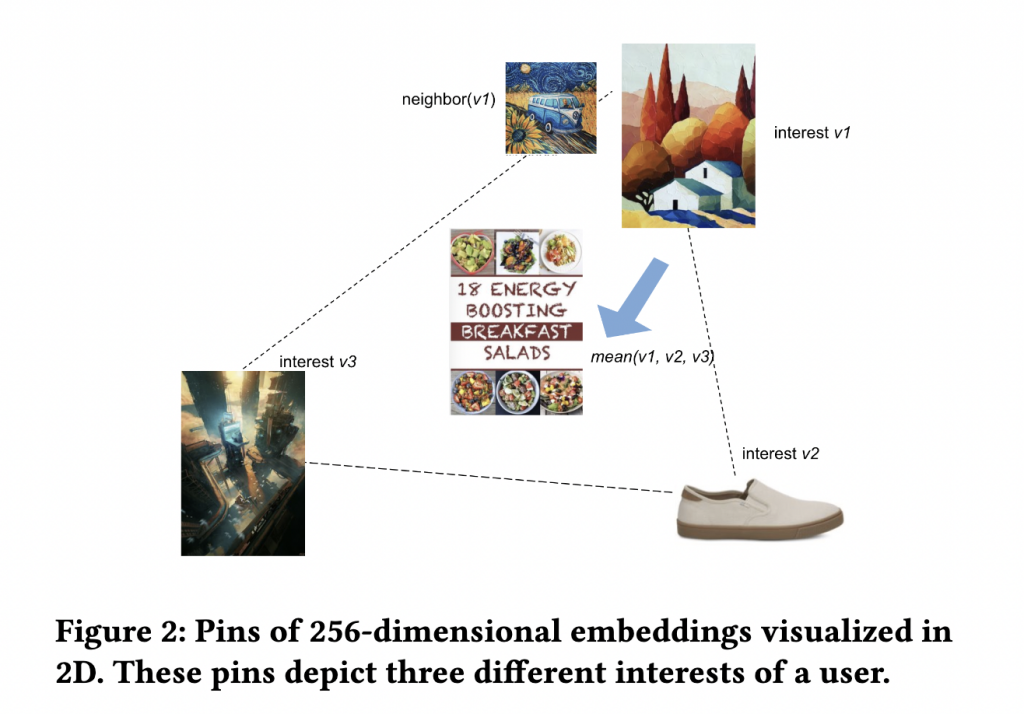
Pinterest 面臨的挑戰:如何有效地 encode 使用者的很多面向?使用者可能會有很多不同的興趣(還記得嗎?Instagram 也討論過這個問題,詳情請見 Instagram 的介紹文章,而這些興趣之間彼此沒有關聯。如下圖所示,使用者同時對繪畫、鞋子和科幻電影有興趣,而這三個主題彼此毫無關聯。
在嘗試過各種方法後,Pinterest 發現主要有兩個問題:
每一個設計理念的細節為何?讓我們一步一步看下去吧!
之前常見的方法是將用戶的興趣全部一起學習以產生embedding,但是這在大型應用程式上有一個問題,就是無法掌握模型最後會變多複雜,讓效能變慢。
另外,常常會跟想要的結果相反。以上圖的例子來說,如果同時學習繪畫、鞋子和科幻電影這三個主題,會使這三個主題的 embedding 變更靠近。但是,他們不應該被這樣學習,因為他們是互相不相關的主題。
Pinterest 的解法就是使用自己提出的 PinSage。
前人有時會將 embedding 的數量限縮在一個小數值,將過多的 embedding 合併起來。然而,如此一來很可能會限制對用戶的理解,甚至將不同概念混在一起,導致不好的推薦內容。
同樣以上圖為例,如果將這三個不同主題的 pin embedding 合併,例如取三者平均,會產生「energy boosting breakfast salads」這種內容,但很明顯地不是正確的推薦內容。
為了避免這件事發生,Pinterest 不限制用戶的 embedding 數量,而是使用 clustering,將用戶的行為利用一個階層式的架構聚集起來,並取用 medoid 當作代表。
為了讓推薦系統可以不斷適應用戶的新需求,並同時將用戶過去 60-90 天的行為納入考量,他們考慮同時使用兩種方法:
綜合以上,當用的新行為發生時,只有線上的版本會更新,在一天結束後,才會更新線下的版本 (1)。
當用戶輸入一個 query 時,ANN 系統需要快速得到跟這個 query 有關的 k 個 pin。而為了有效率地提取和輸入 query 相似的推薦內容,需要很好的 indexing 方法
懷抱著以上四個設計理念,PinnerSage 的推薦模型分為以下三個步驟:
讓我們來介紹每一個步驟。
在挑選 clustering methods 的兩個條件:
解法:Ward。一個利用最小變異數以計算 cluster 的方法(滿足條件一),且根據距離自動決定 cluster 的數量(滿足條件二)。
在取 cluster 的代表時,常見的方法是使用 cluster centroid、time decay avg model 或其他 sequence model(如 LSTM 或 GRU)。然而,這樣的問題是可能會得到一個在跟原本 embedding space 很不同區域的點當代表,由其是當有 outliers 時,最後造成推薦完全不相關的內容。
解法:使用 medoid 當作每個 cluster 的代表。此方法的好處是 medoid 一定會位在某個 cluster 成員的同個區域中。
挑選方法:選擇一個和所有其他 cluster 中的 pin 距離的平方總和最小的 pin,請見以下公式:
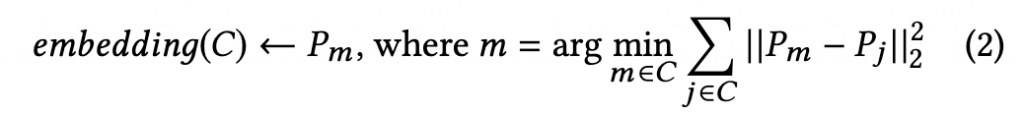
雖然一個用戶的 cluster 數量不多,但是還是要挑選一下,因為用戶太多了,不能所有 cluster 都使用。挑選的條件取決於每個 cluster 的重要度分數(importance score)。
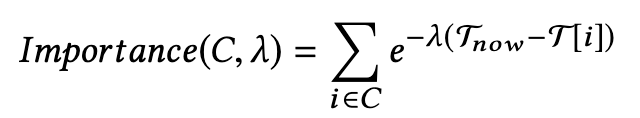
T[i] 是用戶對 pin i 有行動的時間,最近有互動的 cluster 分數會比較高,可使用 λ 調控想要強調的內容。例如 λ = 0 更強調用戶最頻繁的興趣,λ = 0.1 更強調的是用戶最近的行為。而 Pinterest 使用 λ = 0.01,因為可以平衡以上兩者。
最後,為了有效率地提取和輸入 query 相似的推薦內容,需要很好的 indexing 方法,他們使用 HNSW 做為 indexing schema。
另外,他們使用 candidate pool refinement。因為如果全部的 pin 都有 index 的話,會提取到一些非常相似的 pins。然而,呈現非常相似的 pin 給讀者是價值較小的,而且有些 pin 的品質可能較差,因此他們使用一些 ML 模型以過濾掉品質比較不好跟相似的 pins。
最後,A/B testing 的結果顯示,使用 PinnerSage 能夠有效地讓首頁的用戶參與度提升 4%,而用戶在購物頁面中的參與度提升 20%。
以上就是 Pinterest 使用 PinSage 和 PinnerSage,以建構推薦系統的方法!
謝謝讀到最後的你,如果喜歡這系列,別忘了按下喜歡和訂閱,才不會錯過最新更新。
也歡迎到我的 medium 逛逛!
Reference:
A. Pal, C. Eksombatchai, Y. Zhou, B. Zhao, C. Rosenberg, and J. Leskovec, “PinnerSage: Multi-Modal User Embedding Framework for Recommendations at Pinterest,” in Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event CA USA, Aug. 2020, pp. 2311–2320. doi: 10.1145/3394486.3403280.


 iThome鐵人賽
iThome鐵人賽