真正掌握權力的人,通常都躲在表面上有權力的人後面,操控著一切。
法蘭西斯・安德伍德《紙牌屋》
這幾天在研究 BERT 的時候想著,如果要拿流行文化來比喻的話,可以用什麼。嗯...利用別人達到更好的成就、亦正亦邪,表現上看起來風風光光,但其實細思極恐,突然想到,還能有比紙牌屋的主角法蘭克還要更好的比喻了嗎?法蘭克也是為了要達成自己的目標,不斷踩在別人(屍)身前進,表面上看起來很厲害,但站上高位之後,卻也容易被別人陷害,受到影響。

Source: CNN(小知識:現在 NETFLIX 開頭的「咚咚」就是出自於這一幕喔!)(沒人在乎)
我想我大概是全世界第一個把 BERT 跟紙牌屋拿來放在一起比較的人了吧!
幹話說完,該進入正題(終於嗎?)昨天我們提到兩階段的遷移式學習(Transfer Learning) 以及 BERT 的訓練方法,還有 BERT 可以完成的那些下游任務。今天來仔細一一了解 BERT 的內部構造吧!
在昨天的文章中有提到,原文獻將遷移學習(Transfer Learning)分成了兩階段,第一階段為Pretraining、第二階段則為模型微調。首先,讓我們來看看預訓練模型在一開始是如何訓練出來的。預訓練時,原文獻的作者將模型訓練分成了兩個任務,一個是克漏字填空(Masked Language Model),另一個則是下文預測(Next Sentence prediction)。

首先,模型會先把文本中的字分成 character-level。如果你還記得的話,在中文中,character-level就是一個字一個字。接著再利用特殊字元 [MASK] 把其中一個字遮住。
[CLS]:分類相關的資訊會放在這個 token 中,讓模型知道我們要進行分類,通常在下游任務才會有用。關於這個標籤是否應該存在,目前也有些爭議,大家如果有興趣看更深一點的文章,可以往這裡去。[SEP]:用於下文預測的預訓練任務中。用於分隔兩個句子的 token。[UNK]:在 BERT 的字典中沒有的字元,會用此 token 取代。[PAD]:記得我們在循環神經網路模型中,為了將句子調整至相同長度,會將長度不夠的句子補足到一樣的長度,那用的就是 [PAD] token。[MASK]:就是克漏字專用的 token。所以說,克漏字填空的訓練資料就會如下:
['[CLS]', '等', '到', '潮', '水', '[MASK]', '了', ',', '就', '知']...
在進行訓練的時候,會將訓練資料中 15% 的詞彙遮蓋住。接著,這些輸入資料通過 BERT 之後,會得到一個 output embedding(還記得 embedding 嗎?)再透過 Linear Multi-class Classifier ,讓模型猜測(決定)被遮蓋住的字是哪一個字。模型之所以有辦法預測答案,是因為被遮蓋掉的字,其上下文的 embedding,一定會與那個被遮蓋掉的字接近,從這些 embedding 接近的字詞中去挑選最接近的,作為模型預測的正確答案。
我很喜歡李宏毅老師在課堂中做的比喻:
如果兩個詞彙填在同一個地方沒有違和感,那它們就有類似的 embedding。

至於下文預測也跟克漏字填空接近。在這裡,作者給了 BERT 兩個句子,讓 BERT 判斷兩個句子之間是否有相互關聯。[CLS] 標籤會放在句首,這是因為在 BERT 之中使用的是 Transformer 的 encoder,其中的 Self-attention 機制,讓標籤位置並不受位置的影響。所以放在句首,仍然可以獲得所有句子的資訊。
所以說,上下文預測放入模型的資料如下:
['[CLS]', '等', '到', '潮', '水', '[MASK]', '了', ',', '就', '知']
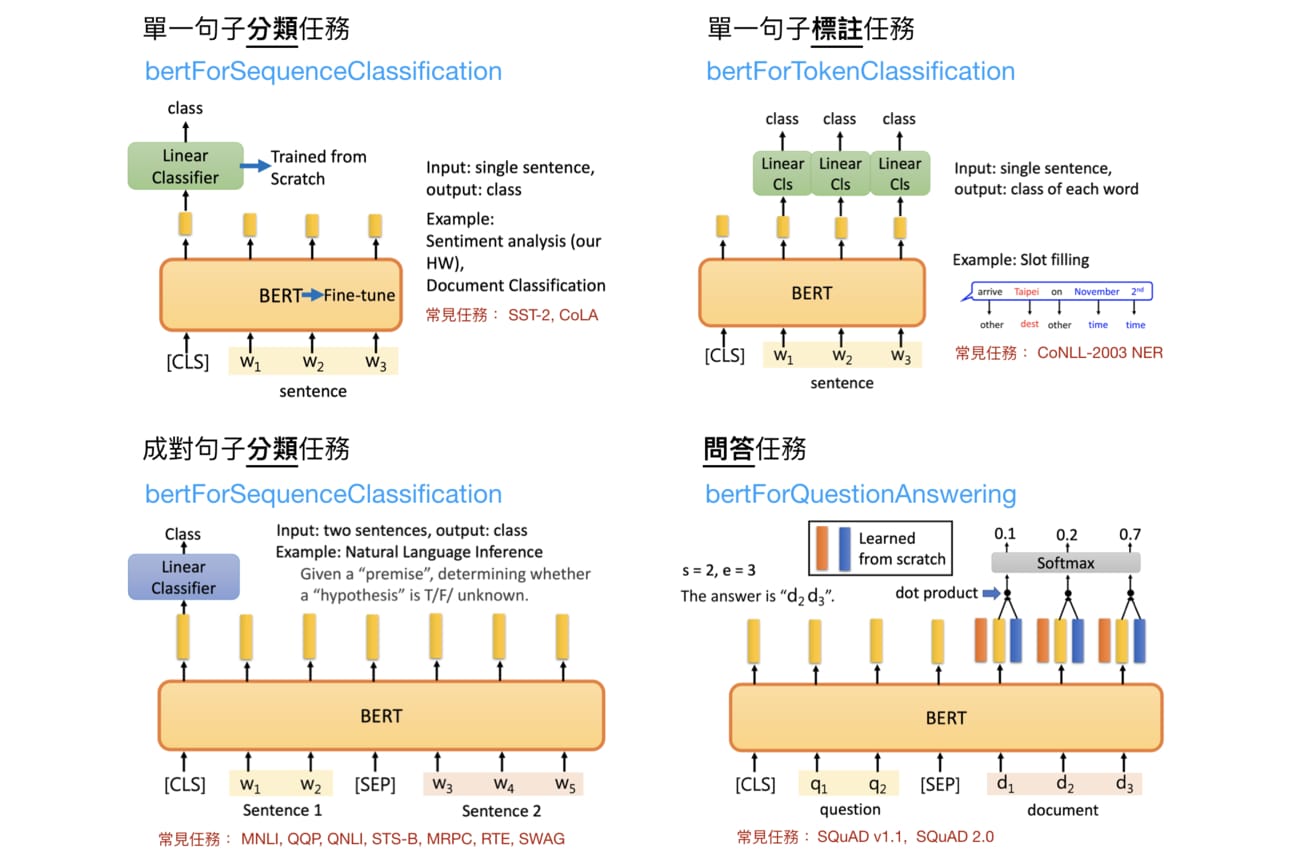
當預訓練模型準備完成之後,就可以用這個模型針對我們想要完成的下游任務進行調整。前面的兩個預訓練任務就是為了要幫助以上這四個下游任務所進行的,如同昨天所是,共有四個任務:單一句子分類任務、單一句子標註任務、成對句子分類任務,以及問答任務。
其中克漏字填空為的就是單一句子分類以及標註。
另外,下文預測的訓練目標就是成對句子分類任務以及問答任務。
[CLS]中的分類資訊,對這些句子進行分類。例如,給出一段前情提要,接著放入一段句子,使模型判斷兩者是否相關,或是可否從前情提要中推斷出這段句子。每一個章節最後一定都要來討論一下優缺點,BERT即使作為當代最厲害的語言模型,仍然也是有他的壞處,而我們則必須衡量這些優缺點,來決定最適合的解決方案。先讓我們來看看 BERT 有哪些缺點吧,當然這裡就不再提深度學習模型的學習時間較為耗時(是要講幾遍?)。
在 Allyson Ettinger 發表的What BERT Is Not: Lessons from a New Suite of Psycholinguistic Diagnostics for Language Models 論文中透過實驗以及以心理語言學的角度,探討了 BERT 的可能缺陷。這裡來一一整理:

從圖中,BERT 可以基於第二句的內容推斷空格中該填入的字,但是卻無法基於第一句的內容來對第二句的空格進行推斷。例如:
Pablo 想要砍一些柴來做木櫃。於是他詢問了鄰居是否可以借他______ 。
人類可以很快地推斷出空格應該填入如斧頭、電鋸等可以砍柴的工具,這是基於我們看過第一句話之後所做的推斷,認為 Pablo 應該要借的是可以砍柴的工具。但模型只能基於第二句的上下文進行推斷,無法像我們一樣基於生活常識進行推斷,於是預測了像是車、房子等詞彙,這就顯示了 BERT 的限制。

BERT 同樣也難以判斷基於語意角色的事件。所謂的語意角色是一個語言學專有名詞,簡單來說就是在句中的參與某個事件或是帶有某個狀態的「參與者」。在圖中的範例,作者刻意將主詞對調,發現 還是會預測相同的詞彙(推測大概是因為 Self-attention 的機制),而且雖然
沒有預測跟前句相同的詞彙了,但預測結果仍不理想。兩者仍然都無法預測出適當地符合句意的詞彙。例如:
紮營者回報有小女孩被熊______了!
模型可以正確預測出「攻擊」、「啃咬」,但一旦兩者對調,變成:
紮營者回報有熊被小女孩______了!
模型預測的詞彙仍然是「攻擊」、「啃咬」。可以發現 BERT 同樣難以推斷詞彙之間的關係,並預測出符合常識的語句。

其中提到 BERT 在推斷具有否定含義的語句時,準確度較肯定直述句還要低。從圖中可以看到說,肯定直述句的案例中,BERT 推斷出的詞放在空格中都是合理的,只是一但加上否定詞,BERT卻仍然會判斷相同的詞彙。例如:
Robin 是 _____。
模型可以很好地推斷出 Robin 是隻鳥,或是一個人。一旦變成否定句:
Robin 不是 _____。
BERT 仍然會在空格中填入 Robin。同樣也足見 BERT,或者是說 Attention 機制的缺點。
好,今天說到這!
Source:

