在 Day 23 知道我們在 GCP 上 有哪些做機器學習的選擇之後,接下來要針對其中一個選擇 — BigQuery ML 做進一步的介紹。
SQL 語法
機器學習知識
複習一下:
BigQuery ML 是一種用 SQL 語法來實現機器學習的功能,好處主要有兩點:
既然 BigQuery ML 是使用 SQL 的指令來實現,我們來了解有那些語法吧!
其實 BigQuery ML 在設計 SQL 機器學習的語法的邏輯,就是按照機器學習的步驟去設計,架構如下:
創建模型 (CREATE MODEL):
評估模型 (Evaluate function):
推論模型 (Inference function):
解釋模型 (AI explanation function):
模型權重 (Model weights):
管理模型:
看起來指令非常多,其實並不複雜,只要掌握下面三種寫法,你也能在 BigQuery ML 中使用的如魚得水。
第一種:
第一種的寫法是在創建模型時會使用到,創建模型當然需要知道 用什麼資料、如何分割、要預測的欄位、超參數設定、如何防止過度擬合等等資訊。。

第二種:
第二種的寫法在評估模型、預測時會使用到,另外評估和預測都會需要用到資料,因此才會有下面的 select * from table。
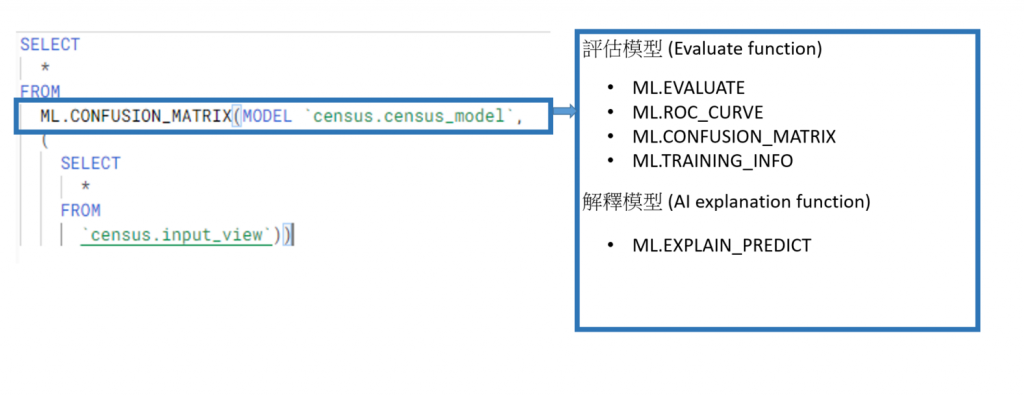
第三種:
第三種的寫法只和模型的數字有關,並不會使用到資料,因此不需要像第二種一樣有select * from table。
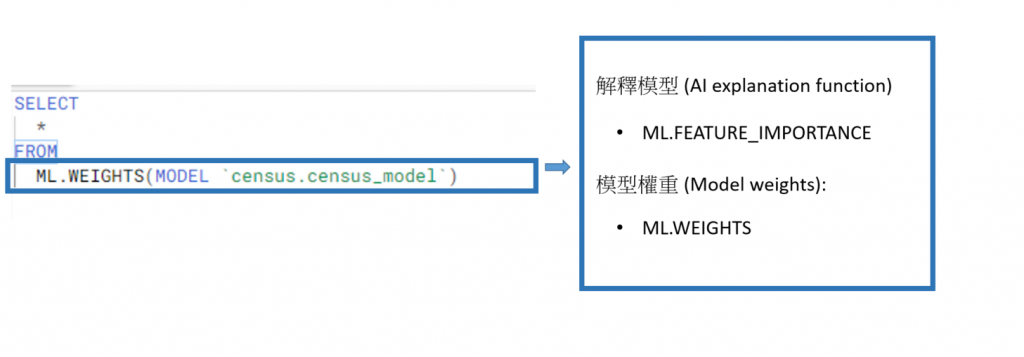
創建模型 (CREATE MODEL):
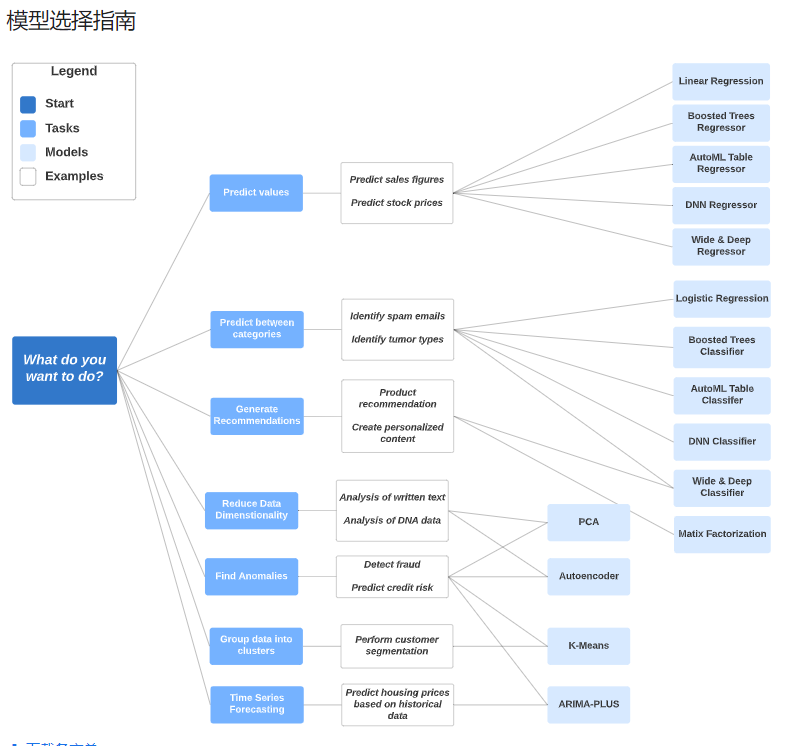
模型的選擇滿多元的,回歸、分類、分群、時序預測和降維等方法都有,官方做的這張cheat sheet 太棒了,我們就用這張做為參考:
Feature processing: 在進入模型訓練之前,常常要做一些資料處理。 這個部分,BigQuery很貼心地也幫使用者想好了,當我們使用 CREATE MODEL 的時候,BQ 會自動幫我們做遺失值插補和特徵轉換。當然,也可以自己另外設定要如何轉換。
Hyperparameter tuning: BigQuery ML 也可以做模型調參,找到相對最佳解。
防止 Overfitting: 目前 BQ 提供兩種方法避免模型過度擬合: early stop 和 regularization。
評估模型 (Evaluate function):
ML.EVALUATE: 依照使用的模型,給出對應的評估模型指標。 比如我們使用 logistic regression,那模型指標會是 Precision, Recall, Accuracy, F1 score, log_loss 還有 ROC_AUC。
ML.ROC_CURVE: 回傳依照不同的 threshold,得到的TP, FP, TN, FN。
ML.CONFUSION_MATRIX: 回傳 CONFUSION_MATRIX,預設的 threshold 是 0.5。
ML.TRIAL_INFO: 回傳訓練過程中迭代的超參數及對應的loss function。
推論模型 (Inference function):
解釋模型 (AI explanation function):
ML.EXPLAIN_PREDICT: 不僅給出預測的結果,還針對每一列的判斷給出解釋!
ML.FEATURE_IMPORTANCE: 給出 feature importamce,只有 Random forest 或是 Boosted tree model 才有這個功能喔,這和模型背後的演算法有關!
模型權重 (Model weughts):
管理模型:
導入 (Import model) : 可以導入先前訓練好的 tensorflow 模型,並使用 BigQuery 的資料去做預測,
導出 (Export model): 可以將模型導出到 Vertex AI model registry,方便日後做多個模型的管理,甚至佈署到端點進行實時預測。
刪除 (Delete model): 可將模型刪除,但目前刪除後無法復原。
下一篇,我們要來實際使用 BigQuery ML 完成機器學習預測!
掌握三種寫法及了解 BigQuery ML 語法五大架構 (創建模型、評估模型、推論模型、解釋模型及管理模型),即可快速上手 BigQuery ML。
https://cloud.google.com/bigquery-ml/docs/introduction

