前面介紹了什麼是 BigQuery、為什麼要用 BigQuery、如何用 BigQuery,和 BigQuery 上的查詢優化。 當使用一陣子或是使用者很多的時候,我們應該會想知道,到底我們使用的狀況如何? 有沒有哪些 user 做了降低效能的查詢;因此本篇將要介紹 BigQuery 中的監控。
在 BigQuery 中,有三種方法可以相互使用,幫助我們監控我們的 BigQuery。
是 cloud google operation 的其中一個功能,裡面主要包含了整體雲端服務的指標,因此我們能夠特別選取感興趣的服務探索,以我們的案例來說,可以選擇 BigQuery。
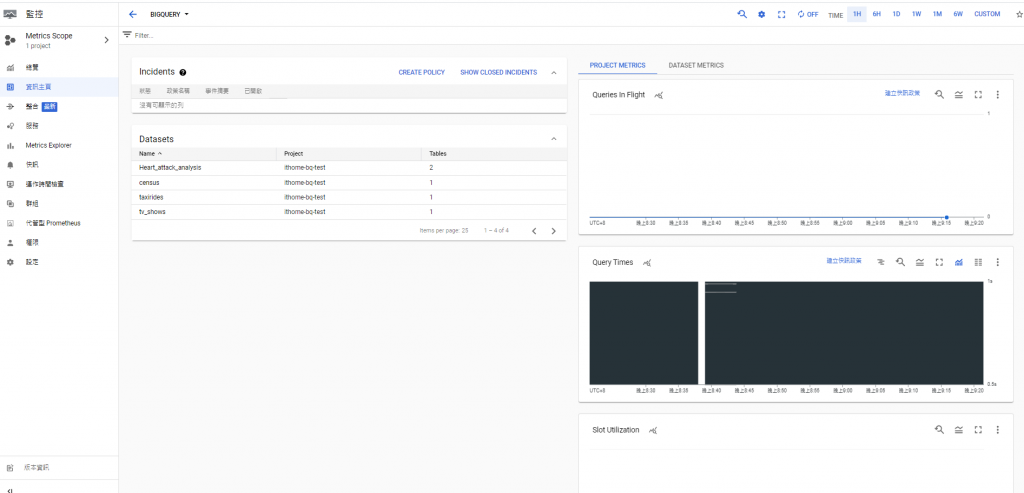
預設的圖表分為 Project metrics 和 Dataset metrics。
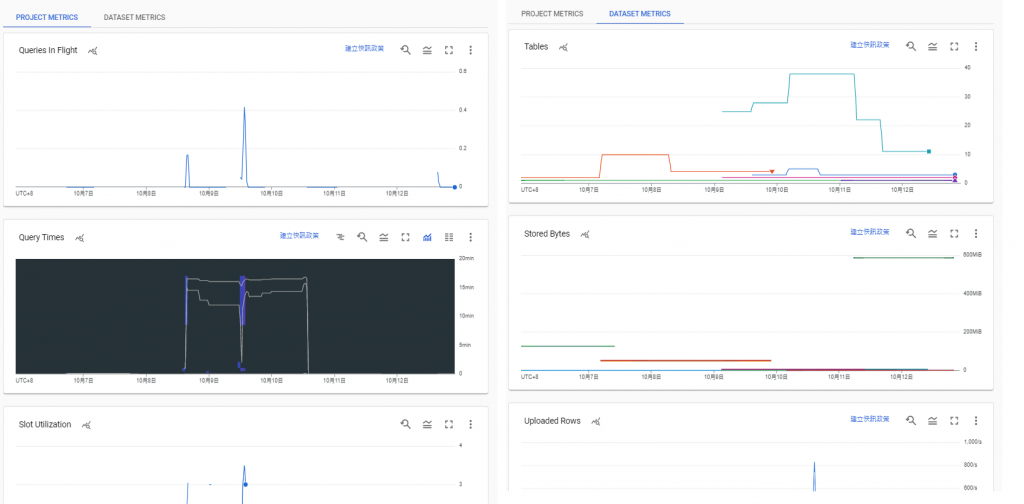
總體來說,monitoring 具備以下的功能:
Cloud monitoring 比較像是總體的角度去做分析,但是如果我們今天想要查看那些單個查詢影響成本和效能呢?
這個時候就是 information_schema 進場的時候了。
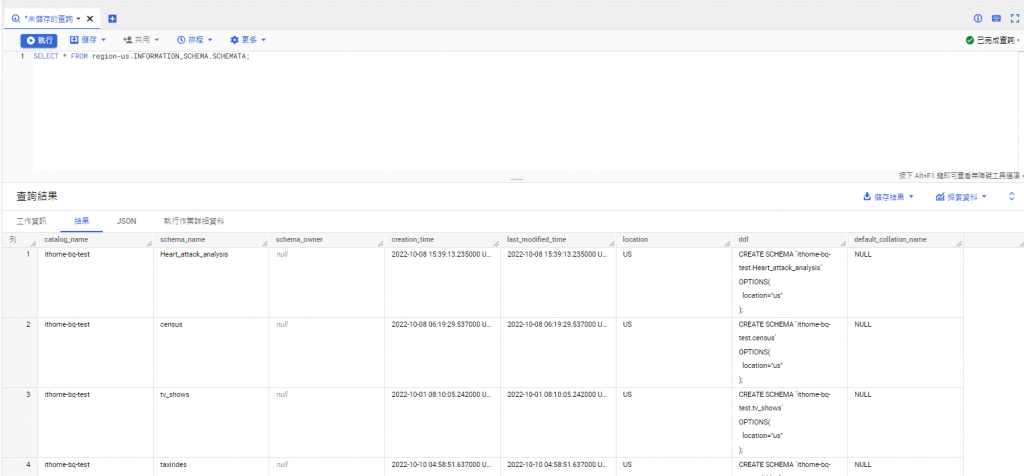
what is an information schema?
In relational databases, the information schema (information_schema) is an ANSI-standard set of read-only views that provide information about all of the tables, views, columns, and procedures in a database.
INFORMATION_SCHEMA view 是系統定義的只讀 view,提供有關 database的metadata。
以上是 information schema 的定義,但GCP已經做了進一步的延伸,和效能有關的,可以分為以下三個:
透過 information schema,我們能夠找到消耗最多資源的 jobs ,並且試著去修復它。
SELECT
project_id,
user_email,
query,
total_bytes_billed,
FROM `ithome-bq-test`.`region-us`.INFORMAION_SCHEMA.JOBS_BY_PROJECT
WHERE EXTRACT(DATE FROM creation_time)=current_date()
ORDER BY total_bytes_processed DESC
LIMIT 5
start time/end time: strat time 可用於分析活躍時間,end time - start time 可用於計算查詢時間。
Job type: 作業的類型。可以是 QUERY、LOAD、EXTRACT、COPY 或 null。
Query (by project only): SQL 查詢語法。這裡要留意,只有 JOBS_BY_PROJECT 視圖具有 query 列。
User email: 可以是 service account 或是 user account。
Bytes processed: 處理的位元組。
Bytes billed: 處理的費用。只適用於以量計價模型 (在固定費率底下僅供參考)。
另外,這個表是 partitioned by creation_time, clustered by project_id and user_email,記得查詢時使用這兩個去做篩選,能夠提升查詢效能並減少費用。 (Day 20: 優化你的BigQuery 查詢,提高查詢效能並節省費用 (下) (實作))
日誌記錄了特定事件或操作而生成的文本記錄。 BigQuery 會為創建或刪除表、購買槽或運行加載作業等操作創建日誌。
日誌是 JSON 的格式。
總體來說,audit log 包含以下幾個項目:
比較特別的是,我們能夠將 audit log 匯出到 BigQuery,也就是說,用 BigQuery來分析自己本身的效能! 明天我們會操作這個部分的練習。
為什麼要匯出呢?
因為 audit log的資料只能保留30天,將數據匯出,才能讓我們對過去的歷史資料進行分析。
另外,通常 audit log 容量比較大,記得在匯出時要設置過濾器,以免匯出資料量過大,高於預期。(這個部份我們在明天的實作會操作到。)
在 BigQuery 中,有三種方法可以相互使用,幫助我們監控我們的 BigQuery。
模組5:BigQuery 中的監控和優化
Google Cloud 的运维套件(以前称为 Stackdriver)
BigQuery 监控简介
BigQuery INFORMATION_SCHEMA 简介
JOBS view


