
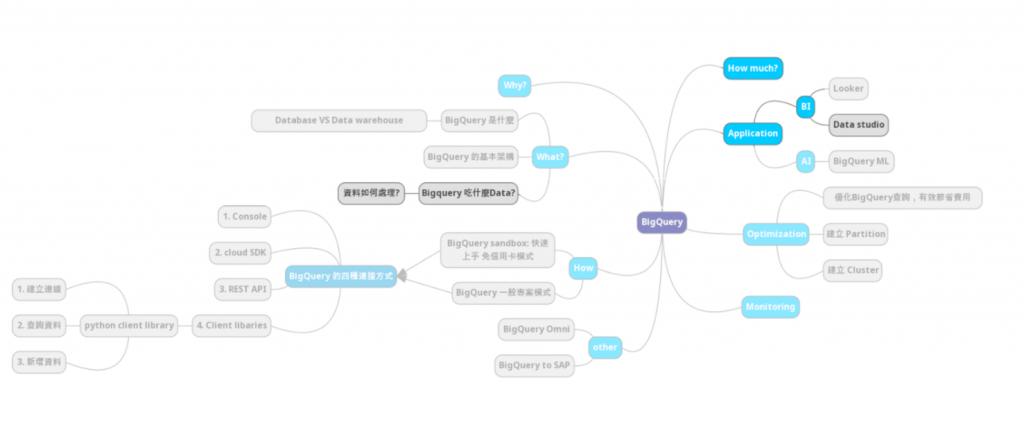
我們在數據分析實作一操作過載入批次數據並建立儀表板,這樣的使用場景非常適合像是主管想要看每周、每月的成本報表。
但是如果我們今天想要做的是即時流量分析、金融業的詐欺偵測或是製造業中的即時異常偵測呢? 這個時候我們需要不同的服務來幫助我們完成這種串流數據的分析!
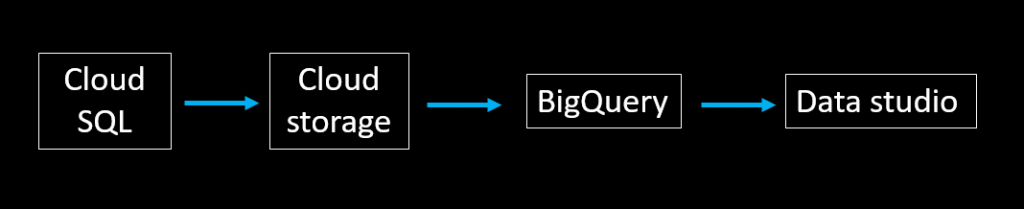
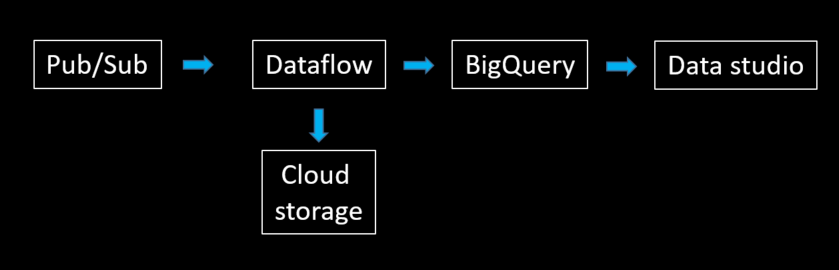
在GCP中,處理這類型串流資料 (streaming data),通常會用到Pub/Sub 和 Dataflow 這兩個服務。
Also known as event stream processing, streaming data is the continuous flow of data generated by various sources. By using stream processing technology, data streams can be processed, stored, analyzed, and acted upon as it's generated in real-time.
streaming data 也稱作 stream processing,是由數千個資料來源持續產生的資料。
其中關鍵詞是 streaming,streaming 表示連續的,是一種源源不絕的數據流,沒有開始,也沒有結束。
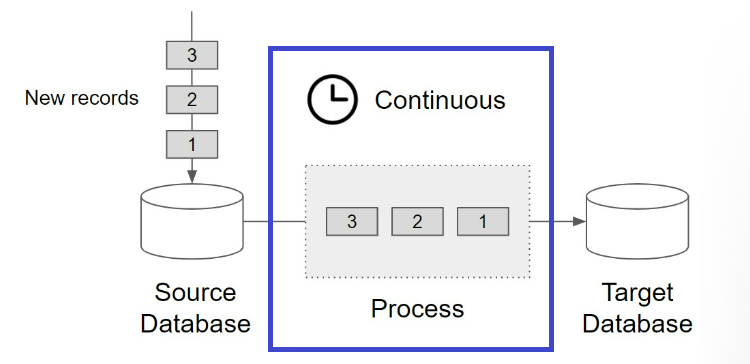
它們的關鍵差異在於是否連續。 batch data 通常會設置排程,有開始與結束時間,而 streaming data 則是源源不絕。
在 Adi Wijaya 撰寫的 Data Engineering with Google Cloud Platform一書中,兩張圖完美表示 streaming data 和 batch data的差異。
圖片來源: Data Engineering with Google Cloud Platform
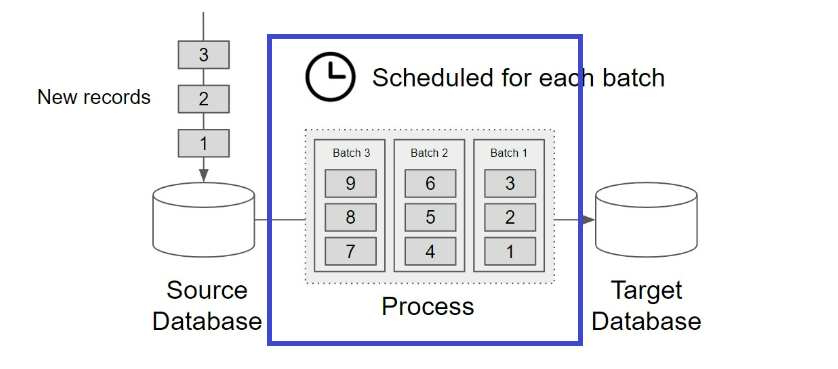
圖片來源: Data Engineering with Google Cloud Platform
圖片來源: Data Engineering with Google Cloud Platform
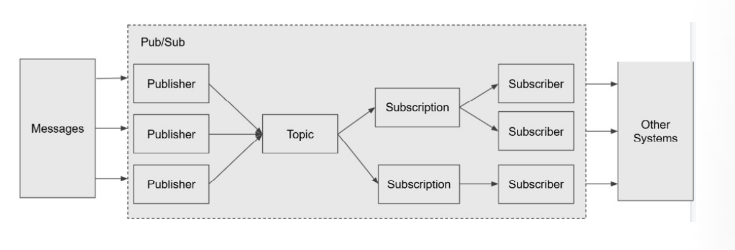
在 Pub/sub 這項服務,可以分為四個元素:
Publisher: 發送 messages 到特定的 Pub/Sub topic。 使用者可以用 python, JAVA…等程式把 message 寫入 Publisher。
Topic: Publish application 可以創建 topic 用來發送 messages (tasks) 到此 topic。我們可以把 topic 想成是 database 裡的 table。
Subscription: Subscriber applications 可以建立多個 subscription 訂閱同一個 topic,當此 topic 有新的 messages 時,會同時發送到所訂閱的 subscription。
Subscriber: 從特定的 Pub/Sub subscription 接收 messages、處理。 有多個 subscriber 是用於分散處理。
在 GCP 上的服務,是 Object Storage 的形式,使用上存在配額限制,比如單個檔案不能大於 5TB。
是 GCP 上資料串接服務,能夠處理 streaming data或是 batch data。
使用方法有以下幾種:
template: 使用既有的 template串接資料,用點按即可完成(下個章節會使用到)。
Apache Beam SDK: 可用 python、Java、GO
Rest API
具備這些先驗知識以後,我們下一篇就要將串流資料寫入 BigQuery 並建立 Real time Dashboard 囉!
streaming data 和 batch data 的關鍵差異在於是否連續。 batch data 通常會設置排程,有開始與結束時間,而 streaming data 則是源源不絕。
Pub/sub 是由Publisher、topic、Subscription和Subscriber組成。
在GCP的世界中,處理這類型串流數據,通常會用到 Pub/Sub 和 Dataflow 這兩個服務。
https://www.confluent.io/learn/batch-vs-real-time-data-processing/
https://aws.amazon.com/tw/streaming-data/
https://www.confluent.io/learn/data-streaming/
Data Engineering with Google Cloud Platform
拆解雲端 Message Service:Google Cloud Pub/Sub vs. AWS SQS 優劣分析
