今天要在 BigQuery 這個資料倉儲的環境中,建置機器學習,並且最後存放到 Vertex AI model registry,方便我們日後做模型的管理。
想像你是醫院心臟科的資料分析師,目前內部的資料倉儲是使用 BigQuery,你希望能夠使用心臟病發作的歷史資料,建立初步的機器學習模型,並且找到和心臟病發作有高度相關的因子。
BigQuery 中提供 BigQuery ML 功能,讓使用者能夠快速時現機器學習想法,另一方面,為了日後方便管理多個模型,後續可以使用 Vertex AI model registry。
今天使用到的資料是 Kaggle 上的 Heart Attack Analysis & Prediction Dataset,共有 303筆資料 和 15 個欄位(我自己有新增patient_id,方便日後做 train, validation和 test的切割)。
資料長相如下:
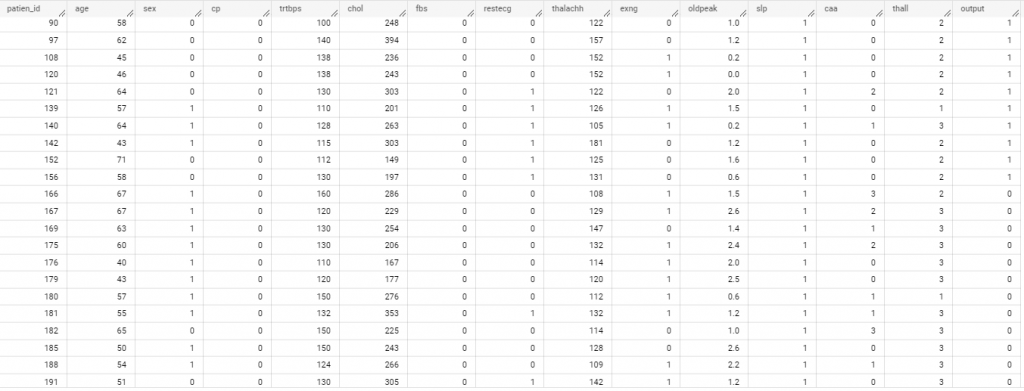
觀察一下資料,我們要預測的是output 這一欄: 是否心臟病發作,是一個分類問題,因此對照我們能夠使用的模型有這些:
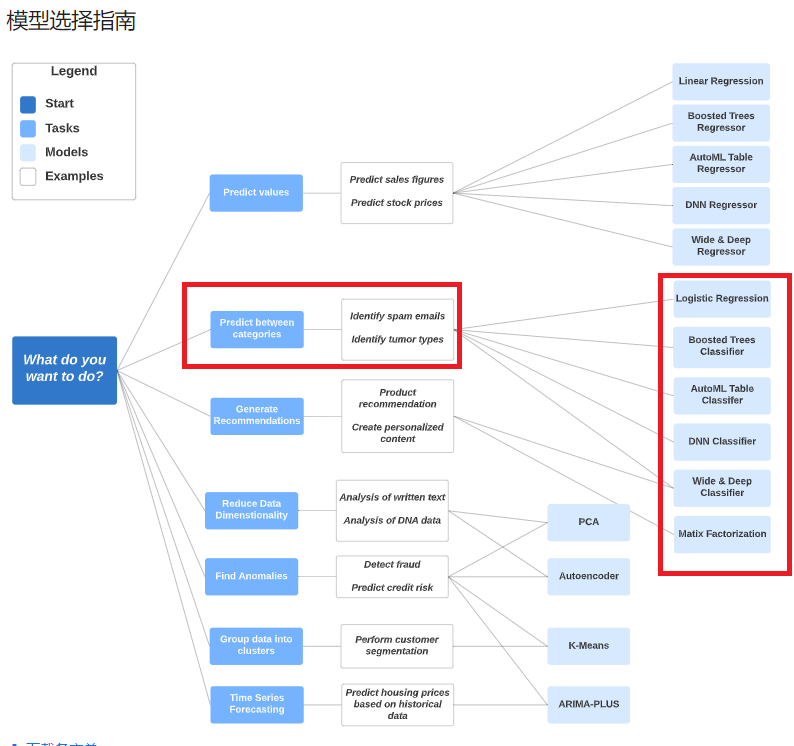
接下來會示範 logistic regression 和 XGBoost 兩種模型。
打開 BigQuery 頁面
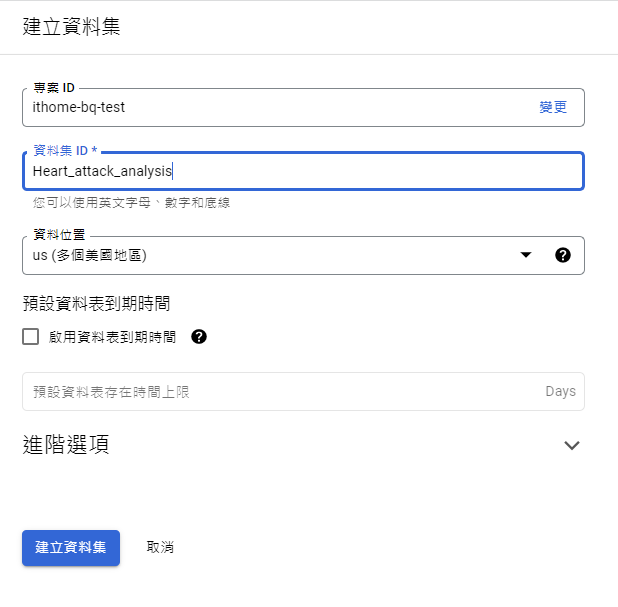
建立資料集:

建立資料表:
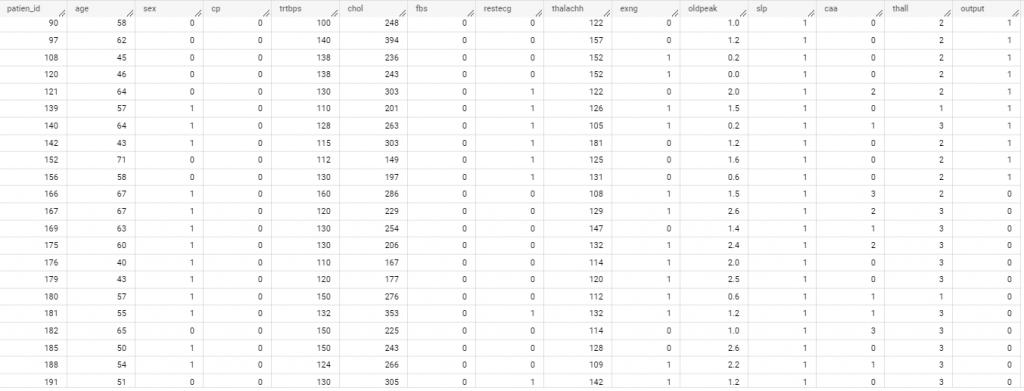
查看數據:
SELECT
*
FROM
`ithome-bq-test.Heart_attack_analysis.heart`
LIMIT
100;
建立 view 表:
CREATE OR REPLACE VIEW
`Heart_attack_analysis.heart_view` AS
SELECT
*,
CASE
WHEN ABS(MOD(patient_id, 10)) < 8 THEN 'train'
WHEN ABS(MOD(patient_id, 10)) = 8 THEN 'validation'
WHEN ABS(MOD(patient_id, 10)) = 9 THEN 'test'
END AS dataframe
FROM
`ithome-bq-test.Heart_attack_analysis.heart`
執行完成後,可看到 heart_view:

因為之後要導出模型,我們先啟用 Vertex AI API:

創建模型 (CREATE MODEL): (logistic regression model)
CREATE OR REPLACE MODEL
`Heart_attack_analysis.heart_model`
OPTIONS
( model_type='LOGISTIC_REG',
auto_class_weights=TRUE,
enable_global_explain=TRUE,
data_split_method='NO_SPLIT',
input_label_cols=['output'],
max_iterations=15) AS
SELECT
* EXCEPT(dataframe)
FROM
`Heart_attack_analysis.heart_view`
WHERE
dataframe = 'train'

模型跑完後,點選專案,可看到產生的模型:

詳細資料記錄了訓練過程用了哪些超參數、訓練日期。
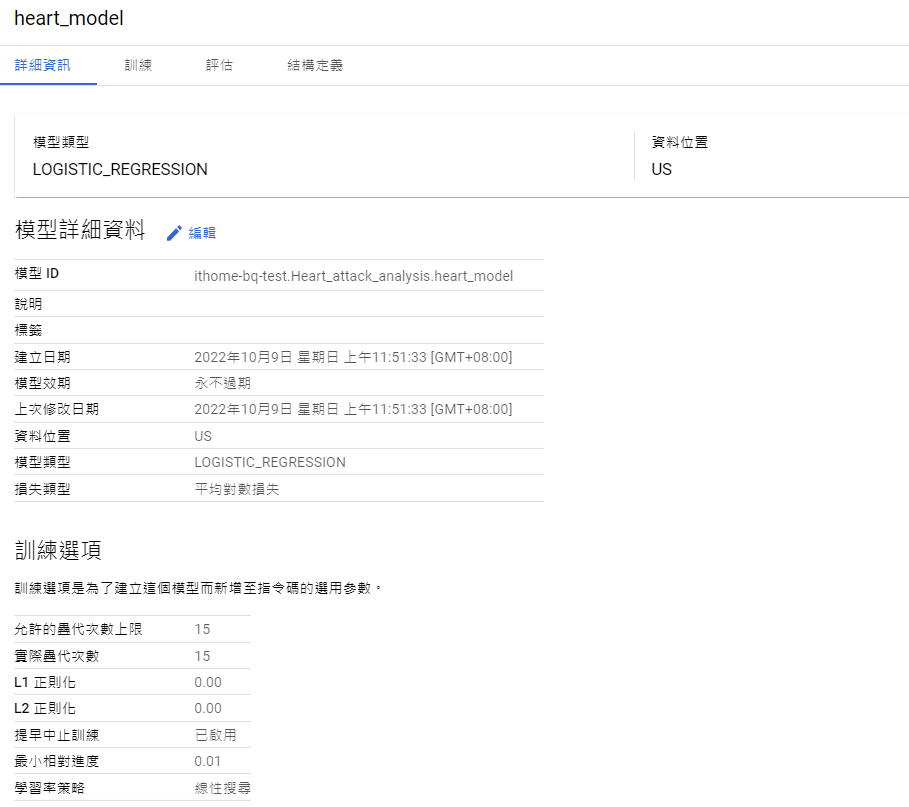
也記錄了訓練過程的學習率(learning rate):
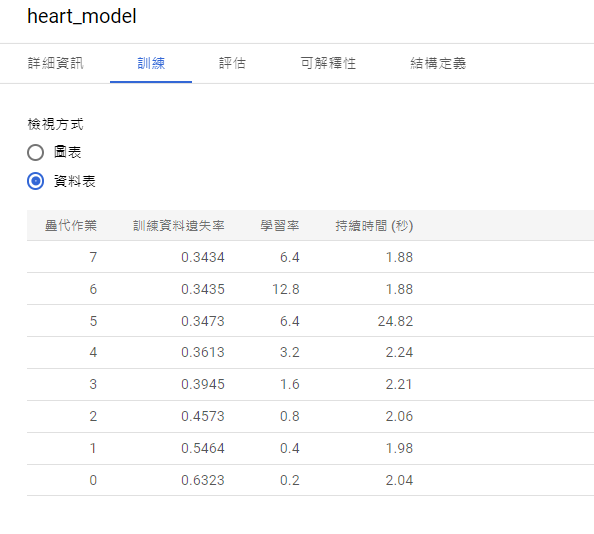
模型的Precision-recall curve、ROC curve:
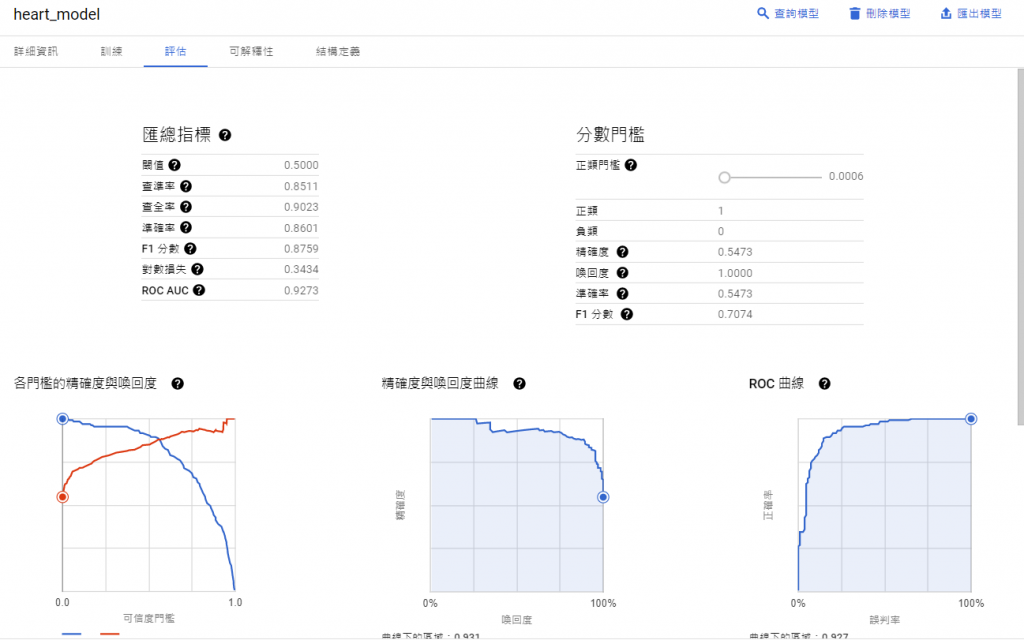
給出了模型中變數的重要性:
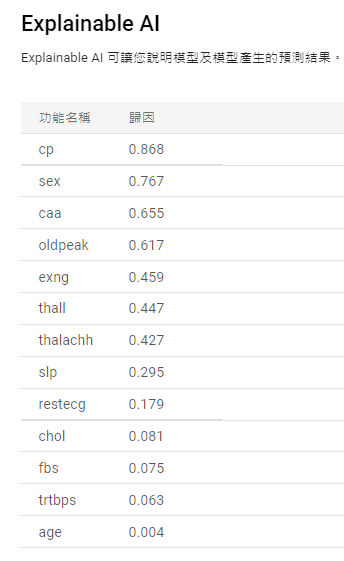
另一方面,我們可以去 Vertex AI查看 模型是否有導出:

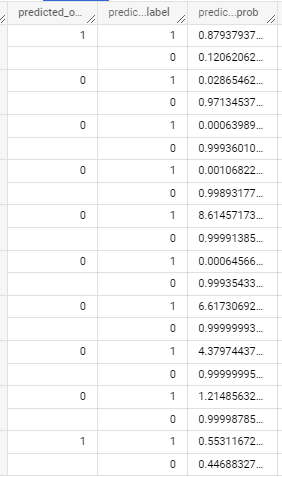
評估模型:
SELECT
*
FROM
ML.EVALUATE (MODEL `Heart_attack_analysis.heart_model`,
(
SELECT
*
FROM
`Heart_attack_analysis.heart_view`
WHERE
dataframe = 'validation'
)
)

模型推論:
SELECT
*
FROM
ML.PREDICT (MODEL `Heart_attack_analysis.heart_model`,
(
SELECT
*
FROM
`Heart_attack_analysis.heart_view`
WHERE
dataframe = 'test'
)
)
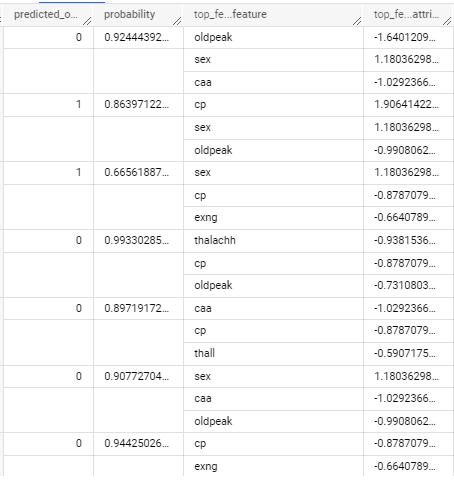
模型解釋:
SELECT
*
FROM
ML.EXPLAIN_PREDICT (MODEL `Heart_attack_analysis.heart_model`,
(
SELECT
*
FROM
`Heart_attack_analysis.heart_view`
WHERE
dataframe = 'test'
)
)
給出了預測是否會心臟病發作,並且還給出判斷的原因!
對模型進行全局說明:
SELECT
*
FROM
ML.GLOBAL_EXPLAIN(MODEL `Heart_attack_analysis.heart_model`)
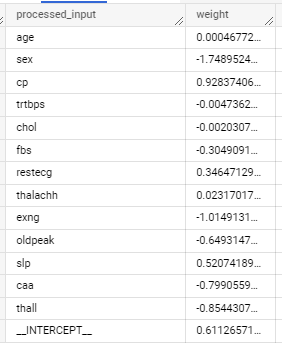
查看模型權重:
SELECT
*
FROM
ML.WEIGHTS(MODEL `Heart_attack_analysis.heart_model`)
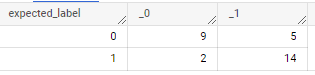
查看confusion matrix:
SELECT
*
FROM
ML.CONFUSION_MATRIX(MODEL `Heart_attack_analysis.heart_model`,
(
SELECT
*
FROM
`Heart_attack_analysis.heart_view`
where
dataframe = 'test'))
創建模型 (CREATE MODEL): (xgboost model):
CREATE OR REPLACE MODEL
`Heart_attack_analysis.heart_model_xgb`
OPTIONS(MODEL_TYPE='BOOSTED_TREE_CLASSIFIER',
BOOSTER_TYPE = 'GBTREE',
NUM_PARALLEL_TREE = 1,
MAX_ITERATIONS = 50,
TREE_METHOD = 'HIST',
EARLY_STOP = FALSE,
SUBSAMPLE = 0.85,
INPUT_LABEL_COLS = ['output']) AS
SELECT
* EXCEPT(patient_id, dataframe)
FROM
`Heart_attack_analysis.heart_view`
WHERE
dataframe = 'train'
接下來的步驟就和前面創建 logistic regression 一樣了,就不再重複描述。
身為一個醫院心臟科的資料分析師,到這裡,你就完成了初步的機器學習模型建置囉!
今天我們學會了在 BigQuery 中創建 logistic regression model 和 XGBoost model,各位也可以換成分類問題的其他模型看看 (Random forest, AutoML, DNN…etc)。
我們曾提過 BigQuery 有四種連接方式,今天使用的是第一種連接方法console 的方式操作,其實也可以用第四種連接方法---python client library 去操作。 之所以會使用 console 方式操作是因為 BigQuery ML 設計就是要讓不熟 python的人,用 SQL的方式實現機器學習。
個人覺得 BigQuery ML 的功能滿適合做初步的機器學習探索,只是因為很多細節 BigQuery 都幫我們自動處理了,建議要閱讀文件,才不會不知道自己的機器學習做了什麼處理。 (比如資料不平衡、資料如何分割、如何避免overfitting...等)
Building and using a classification model on census data
How to Split and Sample a Dataset in BigQuery Using SQL

