
我們所有的資料,全都保存在瀏覽器的 localStorage 裡,
因此,這些資料全都只能在同一個網域內使用。
但我們所保存的詞語記錄,
顯然不應該受到「同網域」的限制。
比如 memory 要從【內存】替換成【記憶體】、
file 要從【文件】替換成【檔案】、
object 要從【對象】替換成【物件】、
tomato 要從【西紅柿】替換成【番茄】、
Beatles 要從【甲殼蟲樂隊】替換成【披頭四】...
如果這樣的替換規則只能在某個網站內達成,
到了另一個網站,
之前辛辛苦苦建立的詞語替換規則,
全都要重新來過,
這樣實在太不合理了。
更別說 localStorage 還有 5MB 的容量限制了!
為了跨越同網域與容量上的限制,
我們只能捨棄 localStorage 的做法,
還好,我們現在有了 Python flask,
可以用 server 的形式提供服務。
我們只要把想保存的資料送往 flask server,
(之後統一稱為 bt_server)
就可以把資料保存起來,
而其他網域若想要共用資料,
只需向 bt_server 請求資料即可。
為了讓 bt_server 擁有保存資料的能力,
我們引入了 Dataset 這個函式庫。
它是一個【懶人專用】的 DB 資料庫相關函式庫,
提供了十分簡單的界面,
讓我們能快速建立資料庫以保存資料。
在使用 Python 的情況下,
當然也可以考慮採用 SQLAlchemy,
不過相對來說 Dataset 真的簡單許多,
我們暫且不想太過深入資料庫的主題,
因此現階段就先用 Dataset 搭配 sqlite,
來實現我們的需求吧。
今天我們打算把各種詞語的翻譯方式,
全部保存到 bt_server 裡的 sqlite 資料庫。
接著就來看看怎麼做囉。
首先,由於要使用到 dataset 這個函式庫,
因此必須先要到 Bash shell 指令行界面中,
把 dataset 這個函式庫安裝起來:
pip install dataset
然後我們要建立一個 db 子目錄,用來存放資料庫檔案。
接著在這個子目錄內,建立一個空的 bt_server.db 資料庫檔案:
mkdir db
touch db/bt_server.db
這樣一來,dataset 的準備工作就完成了。
我們再來看 bt_server 的 Python 程式碼,
這裡可以先建立一個新的 API 界面,
用來保存我們原本放在 saved_terms 裡的詞語人譯與機譯:
@app.route('/api/save_term', methods=['POST'])
def api_save_term():
...
在這個 API 路徑的處理函式中,
任何環節都有可能會出現錯誤,
所以我們先建立一個機制,因應出錯的情況:
try:
...
if ...:
...
else:
raise
except:
return_str = 'save_term 出問題了。。。'
abort(404, return_str)
接下來我們就可以在 try 裡頭編寫程式碼了。
首先就是要取得送進來的資料:
data = json.loads(request.values.get("data"))
record_to_save = data['form_input']
接著進行簡單的判斷,
沒問題的話就去保存資料,再把回應的訊息送回去:
if (record_to_save['ot_text'] and record_to_save['tt_text']):
return_str = bt_dataset.saveTerm(record_to_save)
return json.dumps({
'action': 'save',
'type': 'term',
'return_str': return_str,
});
else:
raise
這裡可以看到,我們用了一個外部的函式:
... bt_dataset.saveTerm(record_to_save)
這個函式來自另一個 bt_dataset.py 檔案,
我們會把資料庫相關的函式,全都集中在這個檔案中。
由於引用了這個 bt_dataset.py 檔案裡的函式,
所以我們必須先在 bt_server.py 的程式碼最前面,
添加下面這行程式碼:
import bt_dataset
然後在同一個目錄下,建立 my_dataset.py 檔案。
緊接著在 my_dataset.py 的最前面,
匯入 dataset 這個函式庫:
import dataset
這個【懶人專用】的函式庫,使用起來相當簡單。
接著我們就來看看 saveTerm() 函式,
怎麼幫我們保存詞語的人譯機譯資料吧。
def saveTerm(record_to_save):
with dataset.connect(f'sqlite:///db/bt_server.db') as db:
table = db['terms']
id = table.upsert(record_to_save, ['ot_text'])
是的,就這樣。
好吧。我還是稍微解釋一下好了 ^_^
首先是這行:
with dataset.connect(f'sqlite:///db/bt_server.db') as db:
這裡會開啟 db 子目錄下那個叫做 bt_server.db 的資料庫檔案。
而 with ... as db 的做法,其實就是開啟一個所謂的 transaction,
也就是資料庫的【交辦模式】。
這就好像大家在辦公室要買飲料,總不可能買一杯就跑一趟,
我們會先把大家想買的飲料點好,再跑一趟飲料店一次完成。
transaction 也是一樣,
我們會在 with 這行指定所要存取的資料庫,並指其代號為 db,
然後在 with 下面的程式碼內,交待要進行哪些資料庫操作,
全部指定完之後,再讓 db 去執行動作。
在指定動作時,我們首先指定了所要操作的資料表 terms,
然後把所要保存的資料 record_to_save,
送進 table.upsert 這個函式中。
這個函式第二個參數,指定的是操作時做為索引的欄位。
我們先來解釋 upsert 的意思,
稍後你就會知道索引欄位的用處了。
upsert 其實是 insert(插入新增)和 update(修改) 的合體。
當我們要把資料保存到資料庫時,
並不知道這份資料是不是已經存在於資料庫內。
通常我們會先檢查一下資料庫:
old_record = table.find(ot_text=record_to_save.ot_text)
你應該有注意到,這裡就是用 ot_text 做為索引。
如果不存在舊資料,就直接 insert 插入新增;
table.insert(record_to_save)
如果存在舊資料,則進行 update 修改更新;
table.update(record_to_save, ['ot_text'])
這裡又再度看到,我們以 ot_text 做為索引欄位。
這是因為若要修改更新資料庫裡的某筆記錄,
就必須先找到那筆記錄,才能進行修改更新。
找記錄就需要用到索引欄位,
意思就是我們用這個欄位來進行比對,
其值比對相符的記錄,就是我們要進行更新操作的記錄。
insert 新增操作會直接添加新紀錄,所以並不需要索引欄位。
綜合以上所述,要在資料庫裡添加資料,
需要進行許多判斷和不同的操作。
但因為這些操作太常用,
每次都要寫一堆重複的程式碼,
實在有違 DRY 的原則。
因此,就有了 upsert 這個方法,把這些重複的工作整合起來。
而且,因為其中有可能會用到 update 操作,
所以也必須指定索引欄位。
如此一來,把資料儲存到資料庫的程式碼,
就可以縮減成一行了:
id = table.upsert(record_to_save, ['ot_text'])
執行完之後送回來的 id,也滿有趣的。
如果是 insert 新增記錄,送回來的就是相應的新 id 編號;
如果是 update 修改記錄,則會送回 True,表示修改成功。
如果我們不想管究竟是新增還是修改,
無論如何都想取得記錄相應的 id 編號,
也可以另外寫一個函式來達成:
def upsert_id(table, data, key):
is_new = True
id = table.upsert(data, key)
if isinstance(id, bool): # Update 【修改】
is_new = False
id = table.find_one(**data)['id']
return id, is_new
如此一來,我們的 upsert_id 一定會送回記錄相應的 id 編號,
而且還會透過 tuple 資料結構,
利用第二個回應結果告訴我們究竟是新增還是修改了記錄。
這樣一來,我們就可以再次修改程式碼:
def saveTerm(record_to_save):
with dataset.connect(f'sqlite:///db/bt_server.db') as db:
table = db['terms']
id, is_new = upsert_id(table, record_to_save, ['ot_text'])
關於索引欄位,這裡再多說幾句。
如果我們只用 ot_text(原文)做為索引欄位,
那麼資料庫裡的每一個 ot_text(原文),就只會有一組的記錄。
你只要稍微想想,就知道為什麼了。
如果是新增的話,當然只會新增一筆記錄。
如果是修改的話,它會用 ot_text 做為索引,把記錄找出來修改,
所以相同的 ot_text 原文,只會對應一組的記錄。
但如果我們希望同一個原文,
可以保存多種 tt_text 人譯、mt_text 機譯的對應記錄,
那該怎麼做呢?
最簡單的做法,
就是把索引欄位設定為 ['ot_text', 'mt_text', 'tt_text'],
這樣一來,唯有這三個欄位的值全都相同,才會更新記錄,
否則一律新增記錄,
因此,相同的 ot_text(原文)就能保存多組記錄了。
至此,保存詞語記錄的程式碼大體上就完成了。
刪除詞語記錄的程式碼也不複雜。
我們同樣先在bt_server.js 中設定 API 路徑的處理函式:
@app.route('/api/delete_term', methods=['POST'])
def api_delete_term():
...
return_str = bt_dataset.deleteTerm(record_to_delete)
...
至於 deleteTerm() 函式,則定義在 bt_dataset.py 檔案中:
def deleteTerm(record_to_delete):
...
deleted = table.delete(
ot_text=record_to_delete["ot_text"],
mt_text=record_to_delete["mt_text"],
tt_text=record_to_delete["tt_text"])
...
這樣就可以啦!!
除了保存、刪除詞語記錄之外,
我們還需要一個可以取得所需詞語記錄的功能。
同樣的,我們可以再設定一個新的 API 路徑:
@app.route('/api/get_terms', methods=['POST'])
def api_get_terms():
...
terms_result = bt_dataset.getTerms(tokens)
...
至於 getTerms() 函式,則定義在 bt_dataset.py 檔案中:
def getTerms(tokens):
saved_terms = {}
with dataset.connect(f'sqlite:///db/bt_server.db') as db:
table = db['terms']
for token in tokens:
records = [r for r in table.find(ot_text=token)]
if records:
saved_terms[token]=records
return saved_terms
Python 伺服器這邊準備好之後,
再來就是外掛的程式碼了。
首先是詞語的保存與刪除。
原本我們在按下【保存】或【刪除】按鍵時,
會透過 sendMessage 把表單內容送到【背景服務】,
再轉送到網頁的【原始內容】content.js 中。
【背景服務】只是單純轉送表單內容而已。
else if (message.cmd == 'save_term') {
chrome.tabs.sendMessage(sender.tab.id, {cmd: 'save_term', data: message.data});
}
else if (message.cmd == 'delete_term') {
chrome.tabs.sendMessage(sender.tab.id, {cmd: 'delete_term', data: message.data});
}
現在我們可以讓它除了轉送之外,
同時向 bt_server 發出請求:
else if (message.cmd == 'save_term') {
...
simple_fetch('http://localhost/api/save_term', message.data)
}
else if (message.cmd == 'delete_term') {
...
simple_fetch('http://localhost/api/delete_term', message.data)
}
其中這個 simple_fetch() 函式,只不過是整合了重複的程式碼。
它其實就只是把表單資料送出去進行處理,
然後就「射後不理」、不管後續的回應了。
我們只是把表單資料送去 bt_server 保存起來,或是去刪掉資料,
因此並不需要等待後續的回應。
而原來的 sendMessage 機制,也可以保留,
它還是會去更新全域變數和 localStorage 裡的資料。
只要添加上面兩行程式碼,
我們就可以重新載入外掛,
再隨便找個詞語,填入人譯、機譯,
然後點擊【保存】,
就可以看到 flask server 那邊做出狀態碼 200 的正確回應了。

但資料究竟有沒有存入資料庫呢?
我們可以利用一個叫做 DB Browser for SQLite 的工具,
來查看 bt_server.db 的內容。
安裝的步驟我就不多說了,查看資料庫內容的結果如下: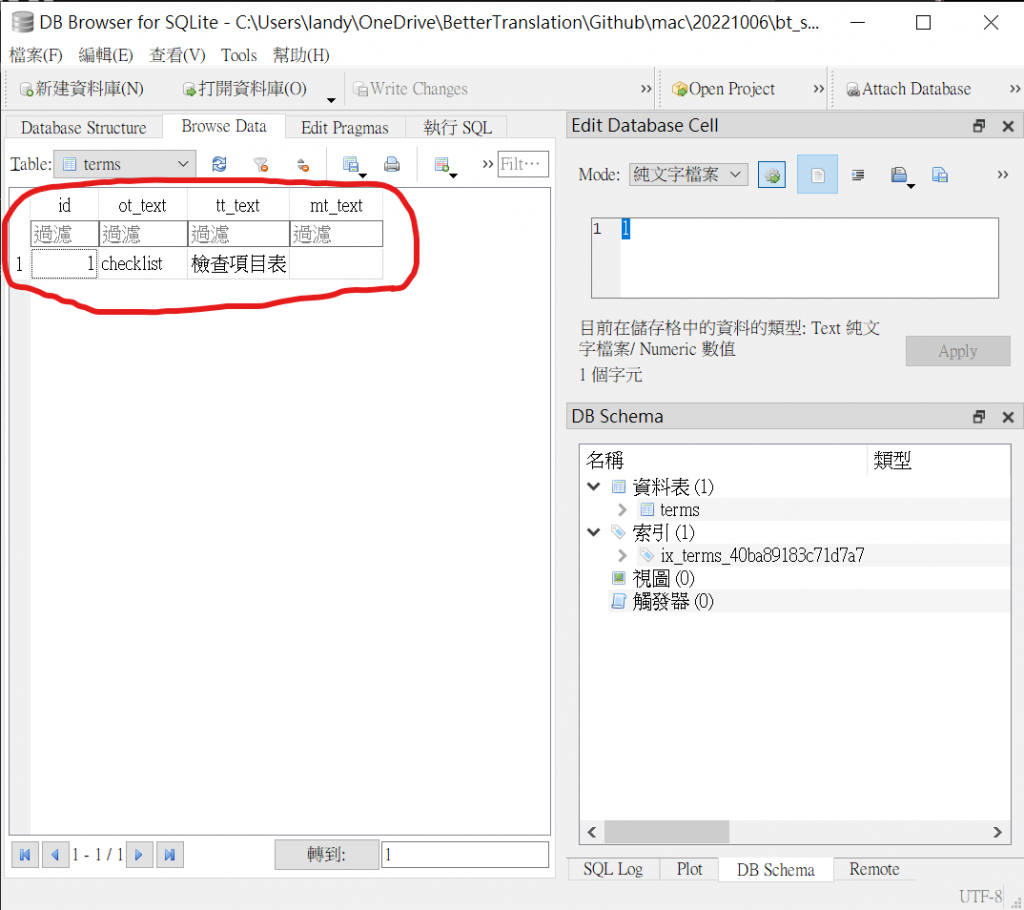
可以看到,資料確實順利存入資料庫了!
你也可以試試【刪除】的功能,
查看 DB Browser for SQLite 裡的記錄是否隨之變動。
既然詞語記錄的保存與刪除都沒問題,
我們就可以讓外掛從資料庫這邊取得詞語資料了。
我們的外掛最起初是在切換原文、譯文的 switchTranslation() 函式內,
從 localStorage 裡取得詞語的人譯機譯資料 saved_terms。
saved_terms = localStorage.getItem('saved_terms')
saved_terms = saved_terms?JSON.parse(saved_terms):{}
我們現在可以先把這兩行註解掉。
改向 bt_server 的資料庫取回資料。
我們可以利用 sendMessage 機制,
向【背景服務】發出 get_saved_terms 的指令:
chrome.runtime.sendMessage({cmd: 'get_saved_terms', data: {tokens: tokens} })
不過,這裡可以看到,如果想要執行這個指令,
就需要提供 tokens 詞語列表。
目前這個階段,我們還不確定要處理的是哪個句子,
所以 tokens 的內容還無法確定。
我們當然也可以把整頁的 tokens 全都送過去,
一次就取回整頁相應的 saved_terms(這也是之前的做法),
不過這種做法其實蠻耗力,
先要拆解出整頁內容所有的 tokens,
其中可能又只有少數在資料庫裡有記錄,
所以會白費很多功夫。
如果要省功夫,當初在保存詞語記錄時,可以連同 url 一起記錄起來,
這樣的話,現在就可以輕鬆根據 url 取用相應的詞語記錄了。
但這樣的做法也有缺點。
我們之所以改用資料庫保存詞語資料,就是為了擺脫網域的限制,
如果只取 url 相關的詞語記錄,就等於走回頭路白忙一場了。
相較之下,前面那種做法還比較合理一點呢!
還有另一種做法,則是在進入每一句的編輯界面時,
才去取用單句的相應詞語記錄。
這樣的做法合理多了。
唯一的缺點,就是每次換句都要去存取一次資料庫。
最後最好的做法,就是再搭配 localStorage,
將存取過的句子保留在本地的 localStorage 中,
沒有存取過的句子,才去資料庫取資料。
換句話說,就是把 localStorage 當做快取的意思。
從以上的討論可以看得出來,
簡單的功能也有可能牽涉到很細緻的考量,
代誌經常都不是想像中那麼簡單,
不過有時用對架構和做法,
還是有可能用很簡單的方式,解決很複雜的問題就是了。
今天的篇幅好像有點多,
我們這裡姑且先改用每一句取相關詞語記錄的做法,
簡單做個介紹,
各位如果有興趣,也可以自己嘗試實現更好的做法喲。
回到我們的程式碼,
在註解掉前面那兩行之後,
我們來到 vue_components.js 裡的【原文句】orig_sent 元件內,
在 tokens 這個 computed 衍生資料的函式裡,
讓它在取得語法分析結果之後,再發出 get_saved_terms 的指令吧!
tokens: function () {
...
if (this.syntax_result) {
...
chrome.runtime.sendMessage({
cmd: 'get_saved_terms',
data: {tokens: token_strs} })
}
...
},
接下來在 background.js 中,接受這個指令,
然後向外部發出請求,以取回 saved_terms 的值。
取得回應之後,再發出 return_saved_terms 指令:
else if (message.cmd == 'get_saved_terms') {
...
fetch('http://localhost/api/get_terms', {
...
})
...
.then(function(response) {
...
chrome.tabs.sendMessage(sender.tab.id, {
cmd: 'return_saved_terms',
data: { saved_terms: result['saved_terms'] }
});
})
【原始內容】content.js 收到 return_saved_terms 指令後,
就會去更新 saved_terms 的值,
並重新設定 Vue 實體 panels.$data.saved_terms 的值,
讓面板顯示新的內容。
else if (message.cmd == 'return_saved_terms') {
saved_terms = message.data.saved_terms;
if (Object.keys(saved_terms).length > 0) {
panels.$data.saved_terms = saved_terms;
panels.$forceUpdate()
}
}
呼!
到這裡,總算是完成了!!
沒想到要把詞語保存到 bt_server 的資料庫,
還有這麼多需要考慮的事。
不過,只要走過這一趟,
其他類似的操作也就大同小異了。
有機會的話,
我們也可以考慮一下,
有沒有可能讓程式架構更簡單一點。
當然,這些都是後話,
今天我們就先這樣囉。
x x x
現在我們的 server,
不但可以代替我們執行【語法分析】之類特定的任務,
還擁有了保存資料的能力。
只要能存取到 bt_server,
就可以共享這些功能與資料。
這麼一來,
整個翻譯平台的想像空間瞬間大了許多。
比方說,如果可以讓多人使用,
不同人就可以透過 bt_server,
針對翻譯成果或不同的詞語譯法進行交流,
甚至可以針對不同階段、不同人處理過的譯文,
各自定義不同的翻譯狀態,
讓整個翻譯流程更加便於管理與交流。
即使是單人使用,
我們也可以在不同的裝置上,共用翻譯的成果。
如此一來,翻譯工作就不再總是需要正襟危坐,
非得坐在電腦前完成不可。
我們可以帶著平板或手機,
在任何不同的地點,延續之前的翻譯工作。
這樣豈不是更加愜意呢?
明天我們就來簡單分享一下,
如何在行動裝置上運用我們的程式,
搭配 bt_server 完成翻譯的工作囉。
