當大家初次接觸ChatGPT時,多數人都會感到驚訝,甚至非常好奇它背後究竟是什麼樣的技術在支撐。相較於過去那些回應呆板、機械式的人工智慧助理,ChatGPT顯然有著明顯的不同。
事實上,ChatGPT並不是使用預先撰寫好的回應或依賴專家進行背後的邏輯拼湊。那麼,它背後的運作原理是什麼呢?簡單來說,ChatGPT是一種基於機器學習的文字生成應用,而它真正在做的事情就像是我們在做文字接龍類似。
而 ChatGPT 是如何做文字接龍? 我們以下圖來說明。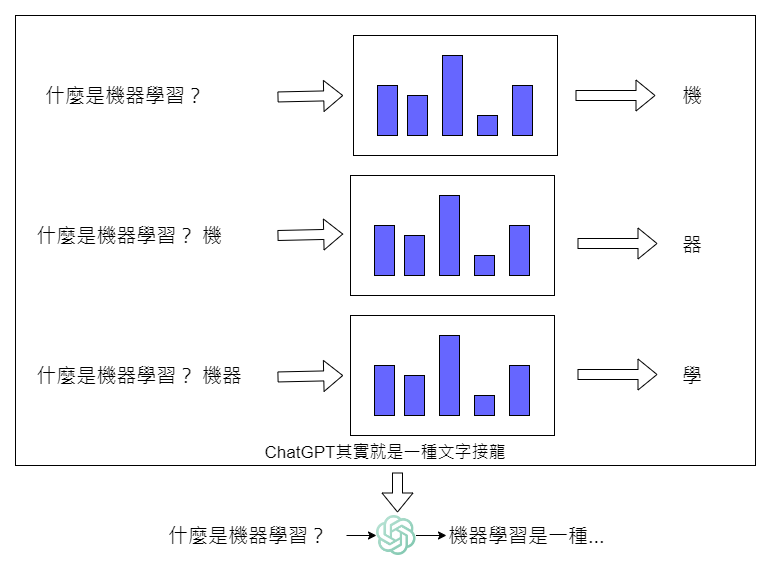
ChatGPT 的核心,你可以把它想象成一種能夠依照你的輸入,判斷、計算出來接下來接什麼字機率比較高的一種數學函數的黑盒子。
不同於傳統程式設計中透過人工組織邏輯和因果關係,機器學習則是通過大量資料來訓練模型,學習一個特定的數學函數。這個數學函數一旦被學習完成,機器就能根據它來回應新的問題。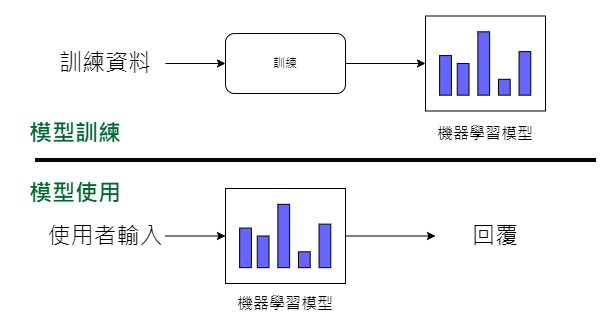
至於機器學習的訓練過程,以實例來說明,如果我們想訓練一個英翻中的機器學習模型,首先需要準備大量的英中對照數據,如:
有了足夠的如上述的數據後,特定的訓練算法則會依照我們提供的資料來調整模型的內部參數,使其能夠理解英文和中文之間的對應關係,例如原來蘋果就是 apple, 橘子就是 orange。
而這種依賴大量標註數據的訓練方式也被稱為監督式學習。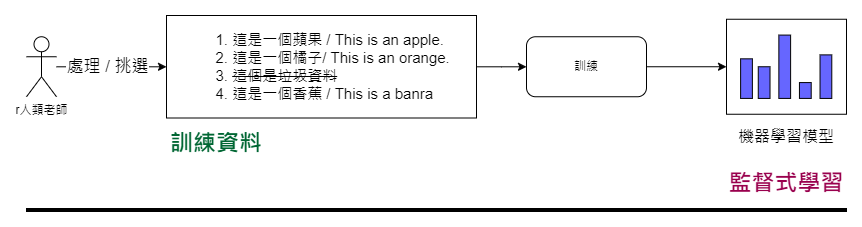
您可能會好奇,僅僅通過這種方式訓練出來的機器學習模型怎麼可能這麼強大?事實上,ChatGPT的強大,的確不單單來自監督式學習這個招式,還有其他關鍵技術,我們將會在後續內容中詳細介紹。
在本文結束前,有另一點值得一提的是,ChatGPT不僅是一種語言模型,它更是一個大型語言模型。所謂的「大型」是指其內部有著巨大的參數量。雖然沒有明確的界定,但一般來說,參數量達到數億或數十億以上的模型,我們會稱它為大型語言模型。
至於 GPT 模型歷代在參數數量的變化歷程,也很值得大家注目。
OpenAI在2018年首次在市場公開發表了第一代GPT,這一版本僅配備了相對較少的1.17億個參數。然而,令人驚訝的是,到了2019年推出的GPT-2,其參數數量便大幅成長,直接提升至15億個。
更令人震驚的是,在2022年,GPT-3的登場將這一數字一舉躍升到了近乎不可思議的1,750億個參數。這種快速且巨大的參數增長不僅展示了技術的飛速進步,也成為了ChatGPT在同年推出GPT-3.5後,能夠全球性地引起廣泛關注和讚譽的一個重要技術基礎。


 iThome鐵人賽
iThome鐵人賽