
本節要探討 optimizer 與 learning rate 有哪些初始設定方式,運作,與有什麼影響。
以上一節範例:
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras.models import Model
class SimpleDense(layers.Layer):
def __init__(self, units=32):
super(SimpleDense, self).__init__()
self.units = units
def build(self, input_shape):
self.w = self.add_weight(shape=(input_shape[-1], self.units),
initializer='random_normal',
trainable=True)
self.b = self.add_weight(shape=(self.units,),
initializer='random_normal',
trainable=True)
def call(self, inputs):
return tf.matmul(inputs, self.w) + self.b
from keras.models import Sequential
model = Sequential([
SimpleDense(512),
layers.Dense(10, activation="softmax")
])
import tensorflow.keras.optimizers as optimizers
model.compile( optimizer= optimizers.get( {"class_name": "rmsprop",
"config": {"learning_rate": 0.0001} } ) ,
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
model.build(input_shape=(None,784))
from keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype("float32") / 255
test_images = test_images.reshape((10000, 28 * 28))
test_images = test_images.astype("float32") / 255
model.fit(train_images, train_labels, epochs=1, batch_size=128)
有三種方式設定 optimizer:
(1)
這邊於模型的compiler內設定 optimizer,以名稱 "rmsprop" 為參數,keras會自己去找對應名稱的模組,但是模組會用預設值0.001。
參考keras官網對於此參數的註記:
learning_rate: Initial value for the learning rate: either a floating point value, or a tf.keras.optimizers.schedules.LearningRateSchedule instance. Defaults to 0.001.
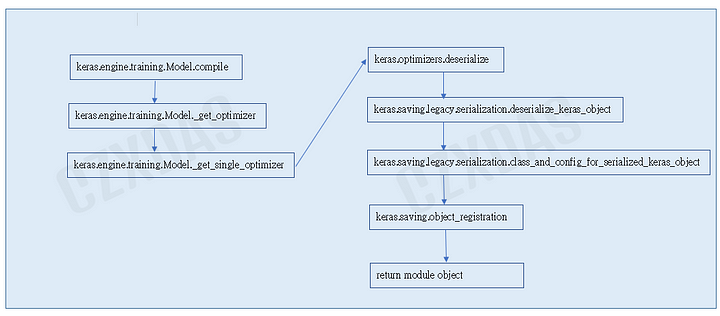
上圖就是靠指定名稱來取得實體過程,主要靠的就是keras.engine.training.Model._get_optimizer 函式,會透過內部設定成dict後,經由keras.optimizers.deserialize取得對應的實體,回傳實體給模型。其中對應的方式是會內建一個對應表,如Compiler章節所提到,內容如下:
"adadelta": keras.optimizers.adadelta.Adadelta
"adagrad": 'keras.optimizers.adagrad.Adagrad
"adam": 'keras.optimizers.adam.Adam
"adamax": keras.optimizers.adamax.Adamax
"experimentaladadelta": keras.optimizers.adadelta.Adadelta
"experimentaladagrad": keras.optimizers.adagrad.Adagrad
"experimentaladam": keras.optimizers.adam.Adam
"experimentalsgd": keras.optimizers.sgd.SGD
"nadam": keras.optimizers.nadam.Nadam
"rmsprop": keras.optimizers.rmsprop.RMSprop
"sgd": keras.optimizers.sgd.SGD
"ftrl": keras.optimizers.Ftrl
"lossscaleoptimizer": keras.mixed_precision.loss_scale_optimizer.LossScaleOptimizerV3
"lossscaleoptimizerv3": keras.mixed_precision.loss_scale_optimizer.LossScaleOptimizerV3
"lossscaleoptimizerv1":keras.mixed_precision. loss_scale_optimizer.LossScaleOptimizer
(2)optimizers.get( {"class_name": "rmsprop", "config": {"learning_rate" : 0.0001} } )
這個方式可以傳遞參數,模型compiler程式修改為傳入learning_rate :
import keras.optimizers as optimizers
model.compile( optimizer= optimizers.get( {"class_name": "rmsprop",
"config": {"learning_rate" : 0.0001} } ) ,
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
(3)
明確物件並給參數
model.compile( optimizer= optimizer.rmsprop("learning_rate" : 0.0001) ,
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
本範例,optimizer 為 RMSprop,以下秀出隨著learning rate往下調,正確率不見得會越來越好。
learning rate set 0.001 (default)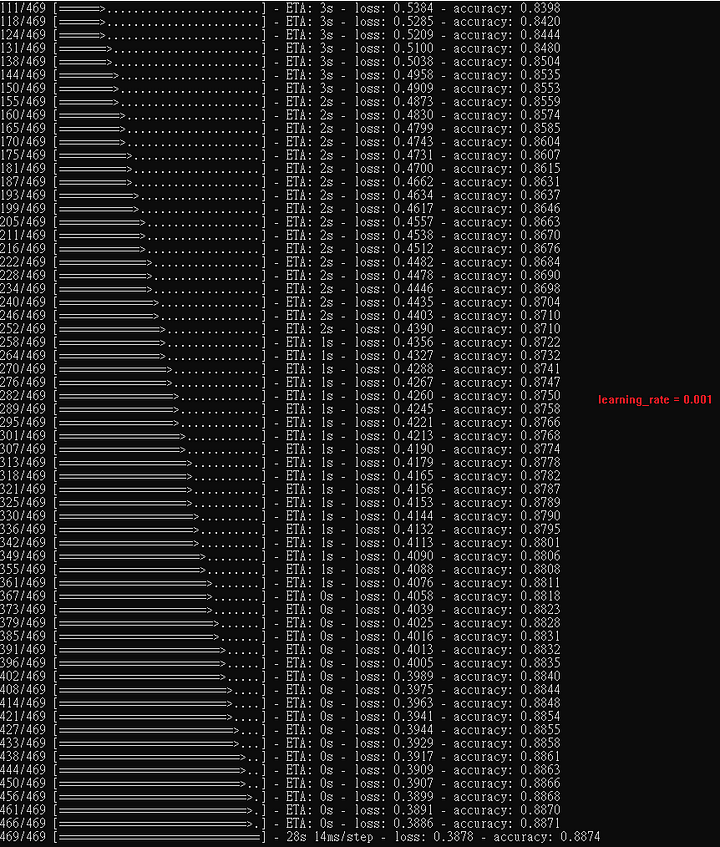
learning rate set 0.0001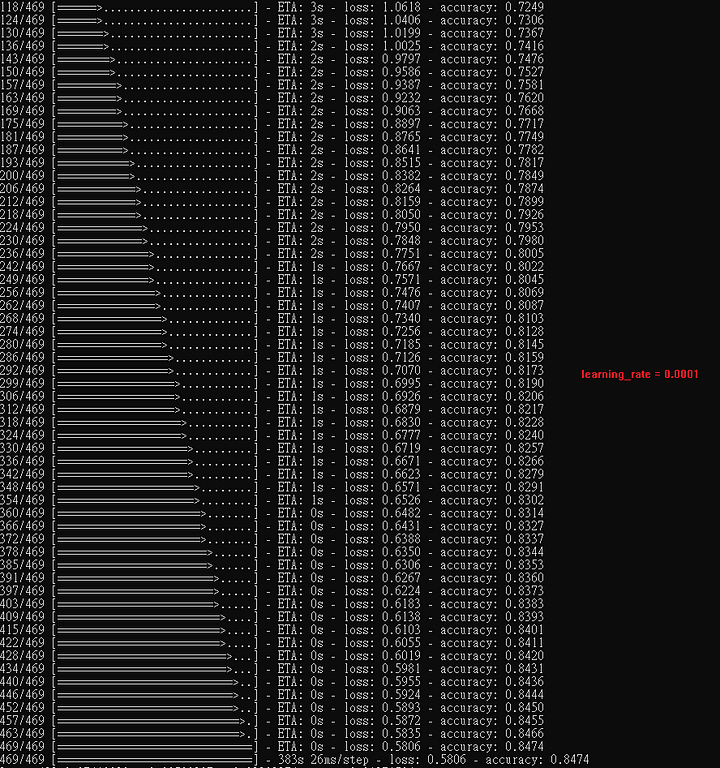
learning rate set 0.00001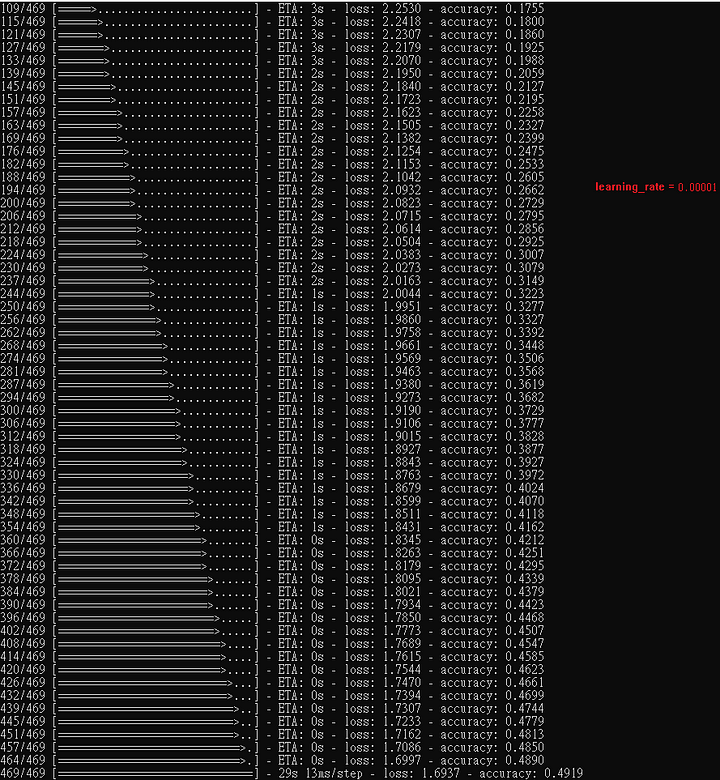
以上是 optimizer 不同的設定方式, 與 learning_rate 在訓練時的重要關係,紀錄於此。

