昨天分享了Tensorflow和Keras的小知識,今天將會繼續分享如何使用 TensorFlow 和 Keras 來執行波士頓房價預測的示例。希望這個示例能幫助各位更好地理解如何建立和訓練深度學習模型。
波士頓房價預測是一個很經典的神經網路回歸問題(雖然我當初剛接觸時覺得有點難QQ),首先我們要先載入所需的套件
import matplotlib.pyplot as plt
import numpy as np
from tensorflow.keras.datasets import boston_housing
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Input
在這裡可以發現,keras裡面含有波士頓房價的數據集,所以不需要在網路下載。而matplotlib和numpy則是用來繪圖跟計算,等等處理數據集時就需要numpy。
接下來我們需要載入波士頓房價數據集
(train_x, train_y), (test_x, test_y) = boston_housing.load_data()
然後對數據進行標準化
mean = train_x.mean(axis=0)
train_x -= mean
std = train_x.std(axis=0)
train_x /= std
test_x -= mean
test_x /= std
我們先將訓練集的所有樣本值進行平均。接下來,對訓練集中的每個特徵,減去該特徵的均值。這麼做的目的是將每個特徵的均值移動到零,從而實現中心化。
第三行則是求出每個特徵的標準差,然後再將訓練集去除以標準差,即可將數據縮放到一個標準範圍
最後也對測試集做一樣的動作。
接下來就來建立基本的神經網路吧
model = Sequential()
model.add(Input(shape=(train_x.shape[1],)))
model.add(Dense(64, activation='relu'))
model.add(Dense(32, activation='relu'))
model.add(Dense(16, activation='relu'))
model.add(Dense(1))
model.summary()
model.compile(optimizer='adam', loss='mse', metrics=['mae'])
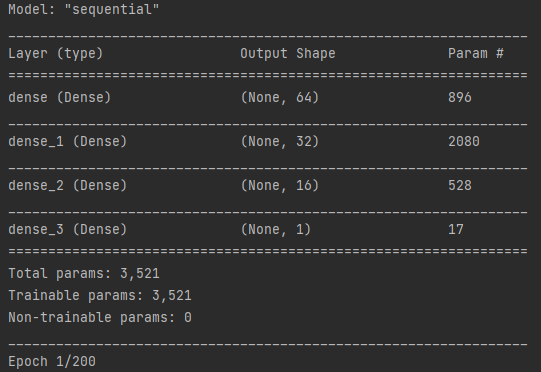
在這裡我添加了四個全連結層,前三個使用 ReLU 激活函數,最後一個是線性層,並在輸入定義了特徵的形狀,該形狀為訓練數據集特徵的數量。最後在編譯模型時我使用了Adam作為優化器,損失函數為MSE,並以MAE作為評估指標
MAE(Mean Absolute Error)為絕對平均誤差。所有誤差求絕對值後,求其平均。是常見的回歸問題評估指標
最後就來訓練模型吧,我們需要使用model.fit來訓練模型
epochs = 500
history = model.fit(train_x, train_y,batch_size=16,epochs=epochs,validation_data=(test_x, test_y),shuffle=True)
這裡我們的訓練批次大小為16,訓練週期為500次,而shuffle則是將資料進行打亂
以下是執行過程
接下來我們該怎麼了解預測結果和訓練成效呢?這時候就需要用到matplotlib了!他可以將我們要的結果畫成一張圖讓我們了解訓練成效
我們先畫出預測圖
predictions = model.predict(test_x)
plt.figure(figsize=(10, 5))
plt.scatter(test_y, predictions)
plt.xlabel('real')
plt.ylabel('predict')
plt.title('real vs. predict')
plt.show()
首先我們先從predictions得到測試集的預測結果,然後使用plt.scatter將預測和實際價格畫成散點圖,就可以知道模型的預測是否與實際值一致了
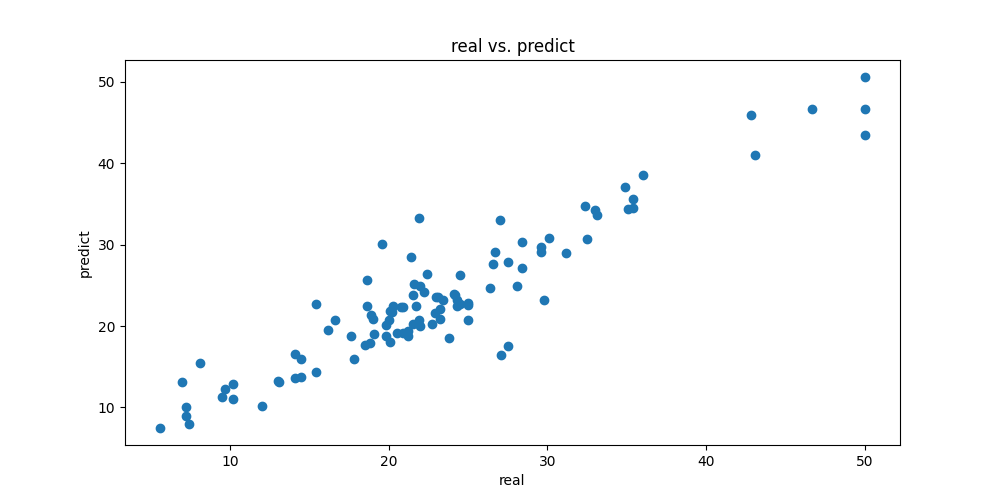
由圖表可得知如果點點越分布在對角線,代表模型預測越準確
最後再畫出評估標準圖
plt.plot(np.arange(epochs), history.history['mae'], c='b', label='train_mae')
plt.plot(np.arange(epochs), history.history['val_mae'], c='y', label='val_mae')
plt.legend()
plt.xlabel('epochs')
plt.ylabel('mae')
plt.show()
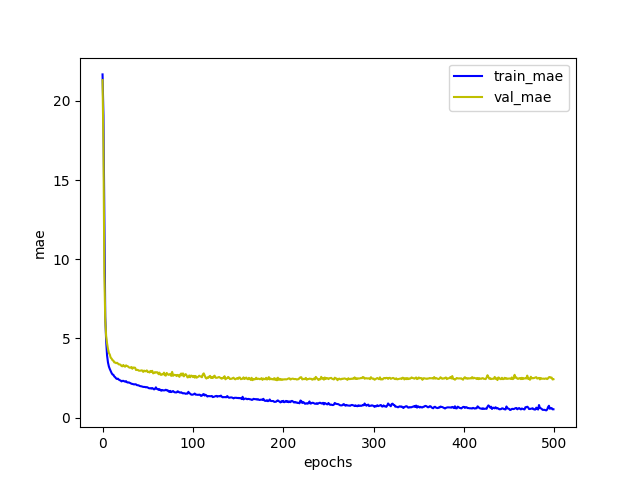
評估標準為MAE越小模型效果就越好
這樣我們就完成第一個深度學習模型了!
以上就是小弟我今天分享有關於深度學習模型的建立與訓練,明天將會使用另一種常見的鳶尾花分類來熟悉深度學習模型,那我們明天見!


 iThome鐵人賽
iThome鐵人賽