昨天分享了波士頓房價預測的示例,今天將會繼續分享如何使用 TensorFlow 和 Keras 來執行另一個分類的示例—鳶尾花。希望這個示例能幫助各位更好地理解如何建立和訓練深度學習模型。
與波士頓房價預測不同,鳶尾花是個常見的深度學習模型分類問題,首先我們要先載入所需的套件
from sklearn import datasets
from sklearn.model_selection import train_test_split
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Input
from tensorflow.keras.utils import to_categorical
基本上與波士頓房價相同,鳶尾花分類也可以直接從sklearn載入,比較特別是我們多載入了to_categorical,這是等等處理數據集時要用到的工具
接下來我們需要載入鳶尾花分類數據集
dataset = datasets.load_iris()
然後對數據進行處理
x = dataset.data
y = dataset.target
y = to_categorical(y)
tr_x, te_x, tr_y, te_y = train_test_split(x, y, train_size=0.8)
我們先從數據集中提取特徵數據給變數X,其中包和花瓣和花萼的長度和寬度,然後再提取標籤交給Y,其中包含鳶尾花數據集中的目標類別,表示每個樣本屬於哪一個鳶尾花的品種
而弟三行則是對Y進行one-hot編碼,one-hot編碼是將每個類別映射為一個向量,其中只有一個元素為 1(表示該樣本屬於該類別),其他元素都為 0。
最後使用train_test_split將數據集拆分為訓練集(80%)和測試集(20%)。
接下來就來建立基本的神經網路吧
model = Sequential()
model.add(Input(shape=(4,)))
model.add(Dense(units=4, activation='relu', kernel_initializer='glorot_uniform'))
model.add(Dense(units=6, activation='relu', kernel_initializer='glorot_uniform'))
model.add(Dense(units=3, activation='softmax', kernel_initializer='glorot_uniform'))
model.summary()
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
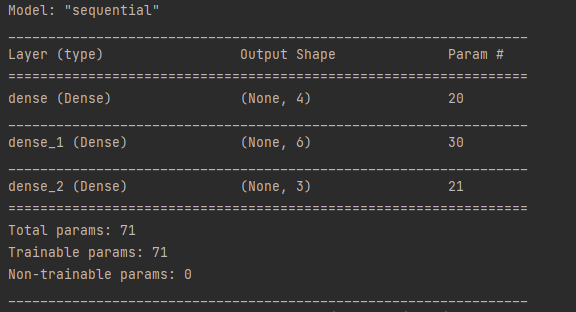
在這裡我添加了三個全連結層,前兩個使用 ReLU 激活函數,最後一使用softmax,並在輸入定義了特徵的形狀。最後在編譯模型時我使用了Adam作為優化器,損失函數為categorical_crossentropy(分類交叉熵),並以accuracy(準確率)作為評估指標
categorical_crossentropy為分類交叉熵,多用於分類問題。它用於衡量模型預測的類別概率分佈和實際類別的差異
最後使用model.fit來訓練模型
history = model.fit(tr_x, tr_y, batch_size=16, epochs=300)
這裡我們的訓練批次大小為16,訓練週期為300次
以下是執行過程
接下來我們需要評估模型在訓練集和測試集上的表現
train_loss, train_accuracy = model.evaluate(tr_x, tr_y)
print('Train Loss:', train_loss)
print('Train Accuracy:', train_accuracy)
test_loss, test_accuracy = model.evaluate(te_x, te_y)
print('Test Loss:', test_loss)
print('Test Accuracy:', test_accurac

這樣就會顯示訓練集和測試集的損失與準確率了!
最後預測測試集並列出預測結果
for i in range(len(predictions)):
predicted_class = np.argmax(predictions[i])
actual_class = np.argmax(te_y[i])
print(f'Sample {i+1}: Predicted class = {predicted_class}, Actual class = {actual_class}')
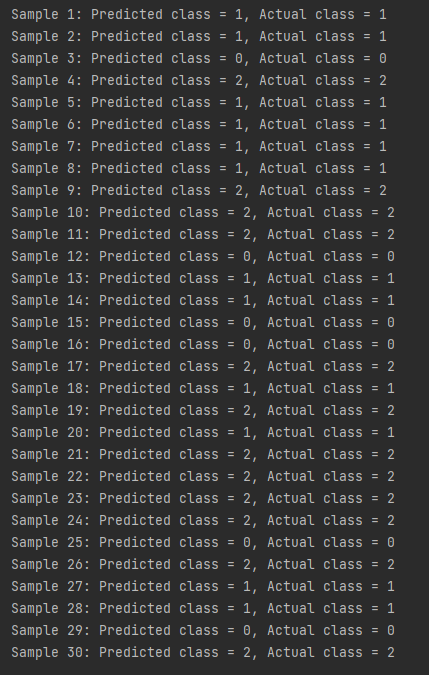
這樣就會列出模型預測的類別與實際的類別了!
經過兩天的練習,其實無論是波士頓房價預測還是鳶尾花分類,其實都是一樣動作,唯一不同的是需要對其問題的方向修改損失與評估標準而已~以上就是小弟我今天分享有關於深度學習模型的建立與訓練,明天進入我們的第二階段,也就是Autoencoder,那我們明天見!


 iThome鐵人賽
iThome鐵人賽