上一篇介紹完NLP之後,現在要進入這次的重點 NLP 的子任務 Named Entity Recognition (NER) 中文是命名實體識別。
命名實體一般指的是文本中具有特定意義或者指代性強的實體,通常包括人名、地名、組織機構名、日期時間、專有名詞
它的目標是從非結構化的文本中識別這些具有特定意義的命名實體,並且可以按照不同需求定義不同類別的實體,像是這次實習時所做的模型就是自定義了 品牌 品項 兩種實體。

在這個例子中,就辨識三種實體
Luke Rawlence
Aiimi、University of Lincoln
Milton Keynes
透過這個技術我們能夠用於許多場景,例如搜尋引擎、問答系統等,找出文句中的關鍵資訊做出對應的處理,如同人與人之間的交流要從對方的話語中理解對方的意圖、意思、情緒,然後回復對方一樣。
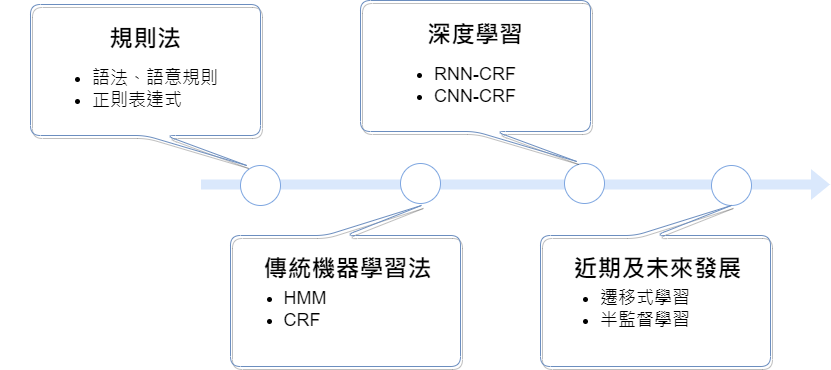
目前常見的方法包括規則法和機器學習法,後來發展深度學習技術甚至到近期的遷移式學習。
規則法 : 最早期的方法,是基於一組預先設定的規則來提取的,可以基於語法、語義等方面進行設計,也可以利用正則表達式等工具進行匹配。它的優點是可以明確定義規則和模式,可以比較容易地修改和調整規則,但是缺點是需要人工編撰規則,對數據的泛化能力較差,難以泛化到未見過的文本或領域。
機器學習法 : 使用標註好的數據集進行訓練,建立統計模型對實體進行識別和標記。優點是一些機器學習算法,如支持向量機(SVM)和決策樹,具有較強的可解釋性,有助於理解模型的決策過程,可以自動學習規律,缺點是需要有手動標記大量的數據資料及耗時的訓練。
深度學習法 : 深度學習技術在NER領域也有了廣泛的應用,深度學習模型通常能夠自適應不同的數據和任務,具有較強的泛化能力,如基於神經網絡架構模型和基於Transformer的模型,這些模型在大規模數據下具有很好的效果,但是需要大量的計算資源(GPU)
(這裡先簡單帶過)T_T
這些步驟用於構建和訓練 NER 模型

