技術文章
技術問答
iT 徵才
聊天室
2026 鐵人賽
登入/註冊
文章
問答
Tag
邦友
鐵人賽
搜尋
2023 iThome 鐵人賽
DAY
29
0
自我挑戰組
30天從零開始學習NLP(自然語言處理)
系列 第
29
篇
Day 29 - NER 模型檔案內容
15th鐵人賽
ner模型
模型檔案
huggingface
肉彈
2023-10-14 16:30:51
879 瀏覽
分享至
這篇我使用我之前上傳到 Hugging Face 的模型檔案來解說,那因為在模型訓練那部份我沒講到要如何上傳模型,因此等鐵人賽結束後我會再補充回去。
介紹兩個重要的部分 (先來說最重要的)
files : 模型的檔案
README.md:README 文件包含了模型的基本資訊,有關模型的描述性文件。
config.json:包含了有關模型配置的 JSON 檔案。它描述了模型的架構、超參數和其他配置資訊。
pytorch_model.bin:這是 PyTorch 模型的二進位權重文件,包含了訓練完成的模型參數。
special_tokens_map.json:這個 JSON 檔案描述了特殊標記(如[PAD]、[CLS]、[SEP]等)的映射和設定資訊。
tokenizer.json:此 JSON 檔案包含了有關標記器(tokenizer)的配置信息,用於將文字轉換為模型的輸入格式。
tokenizer_config.json:這個 JSON 檔案也包含有關標記器(tokenizer)的設定信息,通常與tokenizer.json檔案相關。
Training_args.bin:二進位訓練文件,包含訓練參數和訓練過程的配置資訊。它可以用於還原模型的設定。
vocab.txt:此文字檔案包含了模型訓練的詞彙表,包括模型期間遇到的所有詞彙。
但這些全部的檔案內容我們在使用時也會全部一起載入,基本上也不用太深入地去理解
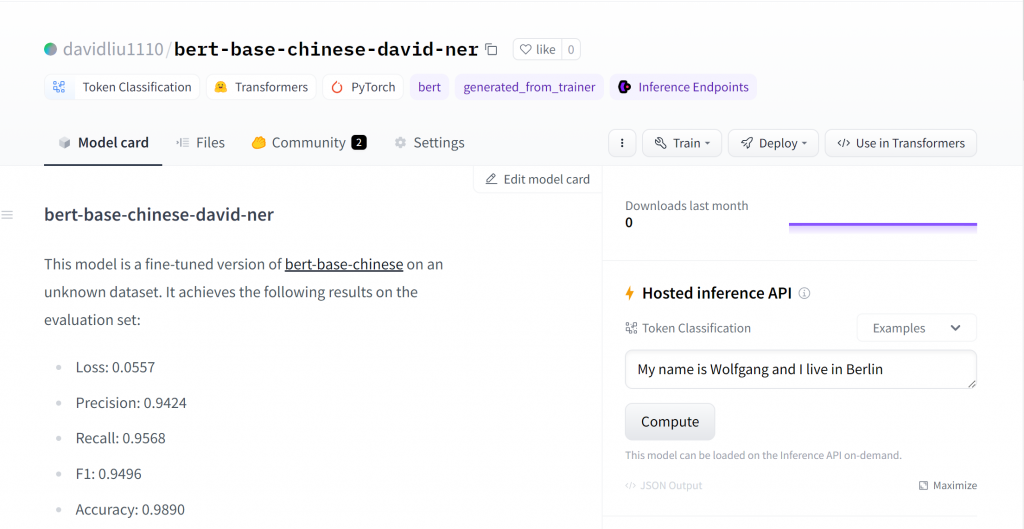
Model card
在預設不去更動 Model card 的情況下,他會包含以下內容
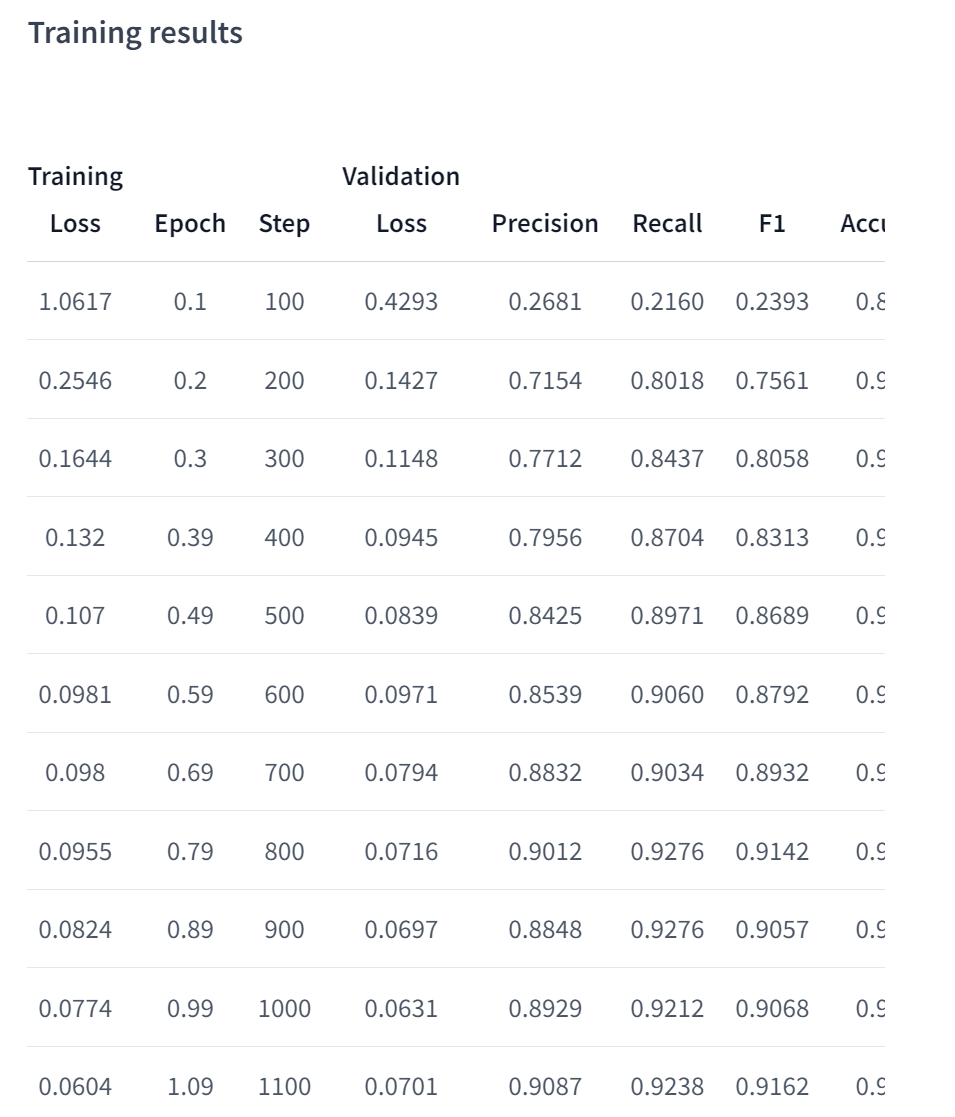
模型的分數和效能等分數
訓練參數
訓練的過程
一些套件的版本
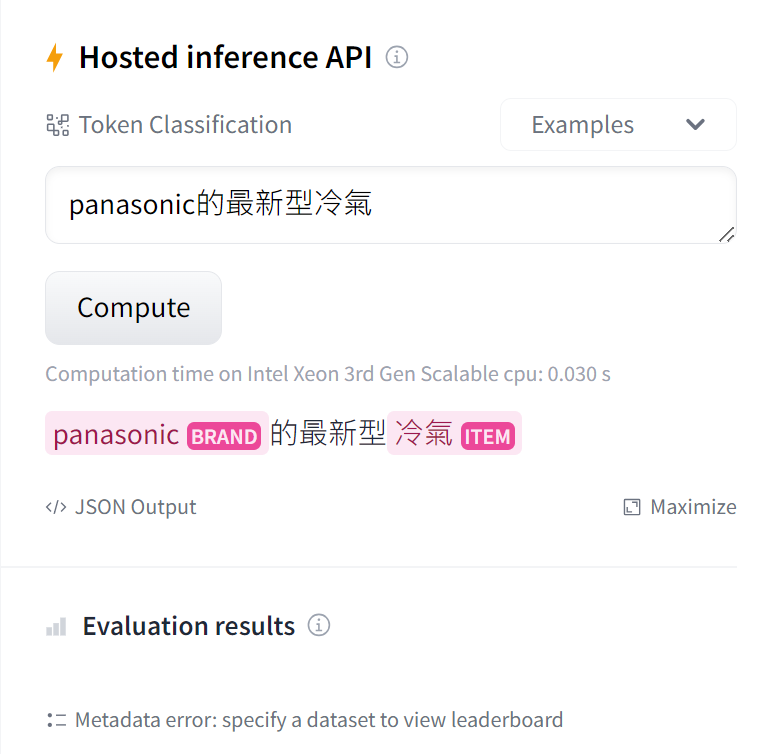
簡易的API
(這是我覺得最棒的地方,他這裡就可以直接試用看看模型的結果)
,下面的句子範例事之前訓練品牌和物品兩種的模型
參考資料
https://huggingface.co/davidliu1110/bert-base-chinese-david-ner/tree/main
留言
追蹤
檢舉
上一篇
Day 28 - NER 模型評估和驗證
下一篇
Day 30 - 建立 Gradio Demo App
系列文
30天從零開始學習NLP(自然語言處理)
共
30
篇
目錄
RSS系列文
訂閱系列文
5
人訂閱
26
Day 26 - NER 模型訓練 (1)
27
Day 27 - NER 模型訓練 (2)
28
Day 28 - NER 模型評估和驗證
29
Day 29 - NER 模型檔案內容
30
Day 30 - 建立 Gradio Demo App
完整目錄
熱門推薦
{{ item.subject }}
{{ item.channelVendor }}
|
{{ item.webinarstarted }}
|
{{ formatDate(item.duration) }}
直播中
立即報名
尚未有邦友留言
立即登入留言
看影片追技術
看更多
{{ item.subject }}
{{ item.channelVendor }}
|
{{ formatDate(item.duration) }}
直播中
熱門tag
15th鐵人賽
16th鐵人賽
13th鐵人賽
14th鐵人賽
17th鐵人賽
12th鐵人賽
11th鐵人賽
鐵人賽
2019鐵人賽
javascript
2018鐵人賽
python
2017鐵人賽
windows
php
c#
linux
windows server
css
react
熱門問題
WSUS伺服器近期客戶端更新都會出現0x80244010
vs code不能執行npm找了很多方法
outlook2024 郵件圖檔無法顯示的情況
熱門回答
vs code不能執行npm找了很多方法
outlook2024 郵件圖檔無法顯示的情況
熱門文章
【 AI Agents 架構】很多人都在談 Loop Engineering,但實際上到底要怎麼做?
[Tedium Is Stability-02] 與 AI 一起開發,看見冰山:一個「功能」,其實是一組沒說出口的隱形契約
使用 Antigravity CLI 建置 Firebase AI Logic 應用程式
清洗 14 年台灣實價登錄資料,我踩到的坑
[Backup] 為什麼「有備份」不等於「救得回來」
IT邦幫忙
×
標記使用者
輸入對方的帳號或暱稱
Loading
找不到結果。
標記
{{ result.label }}
{{ result.account }}