train()方法將模型訓練完後,我們需要了解它在未見過的資料上的表現。使用驗證集進行評估可以幫助您確定模型的泛化能力,即模型是否能夠在新數據上表現良好。trainer.evaluate()
evaluate()方法的用意是在訓練過程中對模型進行評估,以了解模型在驗證集上的表現和表現。Trainer時設定的eval_dataset參數來進行評估{'eval_loss': 0.03453173115849495,
'eval_precision': 0.9602925809822361,
'eval_recall': 0.9704329461457233,
'eval_f1': 0.9653361344537815,
'eval_accuracy': 0.9932748124026618,
'eval_runtime': 4.4921,
'eval_samples_per_second': 106.409,
'eval_steps_per_second': 13.357}
混淆矩陣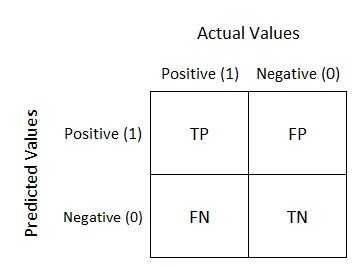
以上圖來自 Sarang Narkhede
混淆矩陣(Confusion Matrix) : 是在分類問題中用於評估模型性能的一種表格,它以矩陣的形式展示了模型對不同類別樣本的分類結果。混亂矩陣通常用於二分類和多分類任務,以幫助分析模型的表現和錯誤分類情況。
四格分別代表
TP (True Positives):模型正確識別的正類別樣本的數量。
(舉例: 預測小帥為陽性,他真的為陽性)
TN (True Negatives):模型正確辨識的負類別樣本的數量。
(舉例: 預測大壯不是陽性,他真的不是陽性)
FP (False Positives):模型將實際負類別樣本錯誤分類為正類別的數量。
(舉例: 預測大美是陽性,結果他不是陽性)
FN (False Negatives):模型將實際正類別樣本錯誤分類為負類別的數量。
(舉例: 預測小美不是陽性,結果她是陽性)
那接下來要來說與混淆矩陣有關的四個分數
Accuracy (準確率) : 模型預測正確數量所佔整體的比例。
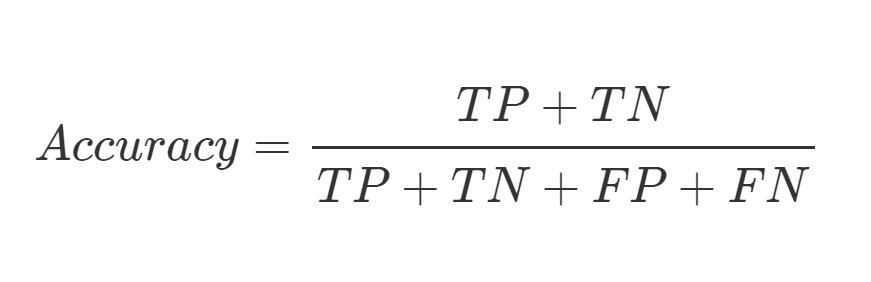
Precision (精確率) : 被預測為 Positive 的資料中,有多少是真的 Positive。
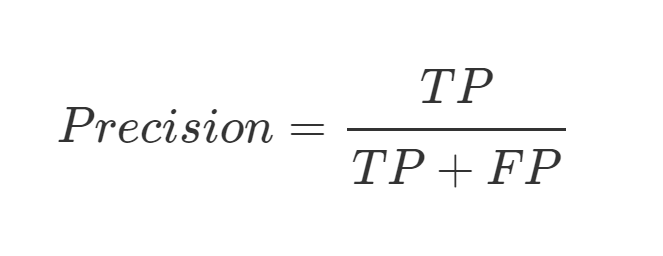
Recall (召回率) : 原本 Positive 的資料中被預測出來的有多少。
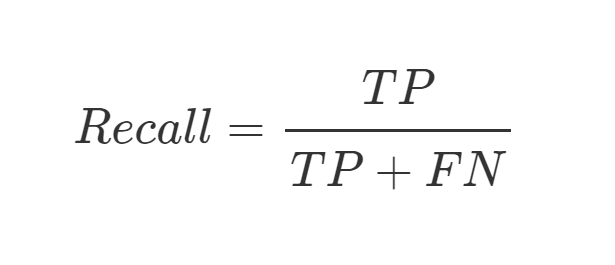
F1-score (F1值) : Precision 與 Recall 的調和平均數。(用於平衡準確度和召回率之間的權衡)
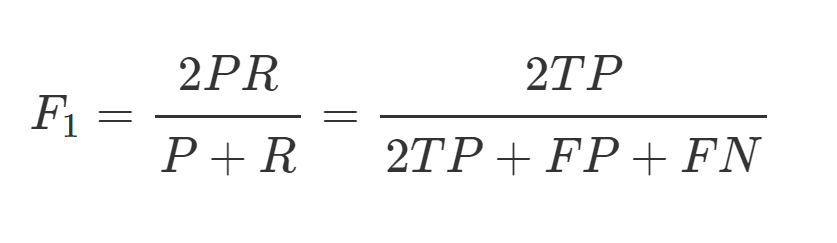
我們昨天在定義一個計算評估指標的函數這裡就可以使用到了
def compute_metrics(p):
predictions, labels = p
predictions = np.argmax(predictions, axis=2)
true_predictions = [
[label_list[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
true_labels = [
[label_list[l] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
results = metric.compute(predictions=true_predictions, references=true_labels)
return {
"precision": results["overall_precision"],
"recall": results["overall_recall"],
"f1": results["overall_f1"],
"accuracy": results["overall_accuracy"],
}
我們來使用這個函數從模型的預測結果和實際標籤中計算出效能指標,以便更全面地了解模型在測試資料上的表現表現。
predictions, labels, _ = trainer.predict(tokenized_datasets["test"])
predictions = np.argmax(predictions, axis=2)
# Remove ignored index (special tokens)
true_predictions = [
[label_list[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
true_labels = [
[label_list[l] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
results = metric.compute(predictions=true_predictions, references=true_labels)
results
predictions, labels, _ = trainer.predict(tokenized_datasets["test"])
predictions = np.argmax(predictions, axis=2)
predict的方法來將產生模型預測的結果: predictions和 原本標記資料的答案: labels
predictions經過argmax函數回傳每一個標記類別的索引,也就是回傳完整的預測結果 true_predictions = [
[label_list[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
true_labels = [
[label_list[l] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
-100
results = metric.compute(predictions=true_predictions, references=true_labels)
`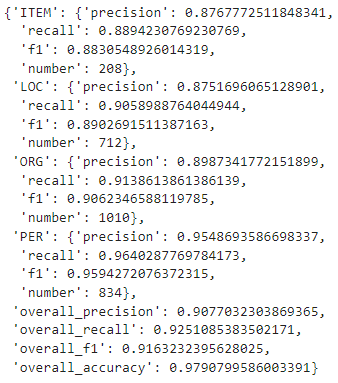
- 這裡除了會輸出`overall`的分數之外,也會把我們的每一個標籤的 `precision`、`recall`、`f1值` 計算出來以及每一個標籤的總數有多少,這樣可以更讓我們清楚知道自己哪一個標籤的表現比較好或是比以較差,以讓我們可以反覆地去調整。

