(會分為上下兩半)在BERT上進行的微調是指將預先訓練好的BERT模型進一步訓練以適應特定任務或領域的需求。BERT 是一個在大規模文本語言庫上進行預訓練的深度學習模型,但是它是一個通用的語言模型,可能需要進一步的訓練來適應特定的自然語言處理任務,那這個動作就稱為微調
中文的 wikiann
bert-base-chinese
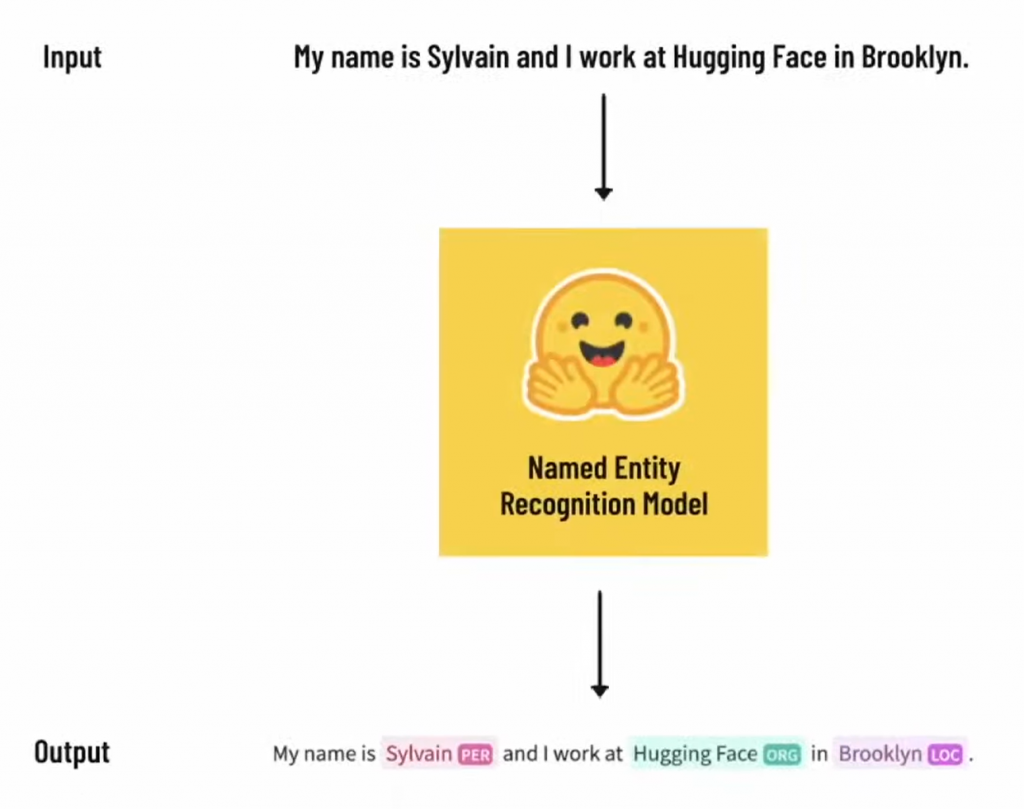
輸入的詞句經過模型處理標示出具有實體代表的詞彙
( 一樣打開 Colab )!pip install datasets evaluate transformers[sentencepiece]
!pip install accelerate
accelerate 用於加速 PyTorch 模型訓練evaluate 用於評估模型性能from datasets import load_dataset
datasets = load_dataset('wikiann', 'zh')
DatasetDict({
validation: Dataset({
features: ['tokens', 'ner_tags', 'langs', 'spans'],
num_rows: 10000
})
test: Dataset({
features: ['tokens', 'ner_tags', 'langs', 'spans'],
num_rows: 10000
})
train: Dataset({
features: ['tokens', 'ner_tags', 'langs', 'spans'],
num_rows: 20000
})
})
label_list = datasets["train"].features["ner_tags"].feature.names
# ['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC']
(這裡取七筆資料)from datasets import ClassLabel, Sequence
import random
import pandas as pd
from IPython.display import display, HTML
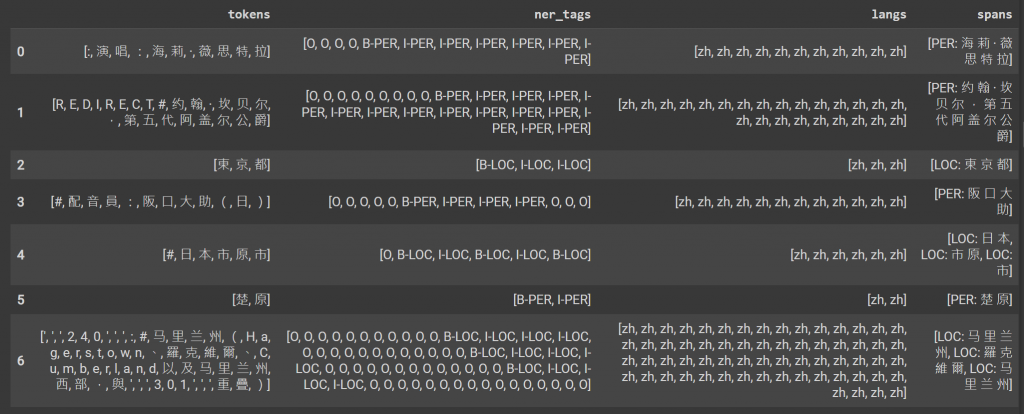
def show_random_elements(dataset, num_examples=7):
picks = []
for _ in range(num_examples):
pick = random.randint(0, len(dataset)-1)
while pick in picks:
pick = random.randint(0, len(dataset)-1)
picks.append(pick)
df = pd.DataFrame(dataset[picks])
for column, typ in dataset.features.items():
if isinstance(typ, ClassLabel):
df[column] = df[column].transform(lambda i: typ.names[i])
elif isinstance(typ, Sequence) and isinstance(typ.feature, ClassLabel):
df[column] = df[column].transform(lambda x: [typ.feature.names[i] for i in x])
display(HTML(df.to_html()))
show_random_elements(datasets["train"])
from transformers import BertTokenizerFast
model_checkpoint = "bert-base-chinese"
tokenizer = BertTokenizerFast.from_pretrained(model_checkpoint)
bert-base-chinese
label_all_tokens = True
def tokenize_and_align_labels(examples):
tokenized_inputs = tokenizer(examples["tokens"], truncation=True, is_split_into_words=True)
labels = []
for i, label in enumerate(examples["ner_tags"]):
word_ids = tokenized_inputs.word_ids(batch_index=i)
previous_word_idx = None
label_ids = []
for word_idx in word_ids:
if word_idx is None:
label_ids.append(-100)
elif word_idx != previous_word_idx:
label_ids.append(label[word_idx])
else:
label_ids.append(label[word_idx] if label_all_tokens else -100)
previous_word_idx = word_idx
labels.append(label_ids)
tokenized_inputs["labels"] = labels
return tokenized_inputs
tokenized_inputs = tokenizer(examples["tokens"], truncation=True, is_split_into_words=True)
truncation=True表示針對超過模型的最大長度會進行截斷,is_split_into_words=True表示原本的輸出文本已經是單詞狀態word_ids = tokenized_inputs.word_ids(batch_index=i)
ex: [None, 0, 1, 2, 3, 4, None]
label_ids = []
for word_idx in word_ids:
if word_idx is None:
label_ids.append(-100)
elif word_idx != previous_word_idx:
label_ids.append(label[word_idx])
else:
label_ids.append(label[word_idx] if label_all_tokens else -100)
previous_word_idx = word_idx
word_ids標記中的每個索引與標籤的對應關係,將標籤轉換為label_ids。ex: [-100, 0, 3, 4, 4, 4, 0, 0, 0, 0, 0, 0, 0, 0, -100]
tokenized_inputs["labels"] = labels
labels列表加入tokenized_inputs字典中的鍵labels下,以便將標籤與分詞後的輸入關聯起來。tokenized_datasets = datasets.map(tokenize_and_align_labels, batched=True)


