接著前一天繼續
5. 定義模型
from transformers import BertForTokenClassification
model = BertForTokenClassification.from_pretrained(model_checkpoint, num_labels=len(label_list))
- 導入 BertForTokenClassification 類,使用 from_pretrained 方法加載
bert-base-chinese
- num_labels 參數指定了模型要預測的標籤數量,這裡的標籤數量是
9
6. 建立各種參數
訓練參數
from tansformers import TrainerArguments
args = TrainingArguments(
output_dir="outputs/bert-base-chinese",
evaluation_strategy="steps",
save_strategy="steps",
save_steps=500,
eval_steps=500,
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
weight_decay=0.01,
fp16=True,
no_cuda=False,
)
-
output_dir會設置訓練完後模型存放的位置
-
evaluation_strategy和save_strategy設置為steps,以步驟為單位去評估模型和保存模型的檢查點
-
eval_steps和save_steps設置為500,每 500 步會去評估和保存模型
-
learning_rate是學習率,
-
per_device_train_batch_size和per_device_eval_batch_size設置為16,用於指定每次訓練和評估時模型接收的樣本數量,每個批次包含16個樣本
-
num_train_epochs設置為3,訓練的總輪數
-
weight_decay設置為0.01,權重衰減用於控制模型的正規畫﹐以防止過度擬和
-
fp16是否需要使用混和精度訓練,可以加速訓練過程,但是需要有特定的硬件才會有用
-
no_cuda通常如果有可用的 CUDA 設備,會建議使用 CUDA 來加速訓練
建立數據收集器
from transformers import DataCollatorForTokenClassification
data_collator = DataCollatorForTokenClassification(tokenizer)
- 建立這個數據收集器的用意是將處理過的數據批次在一起,並對它們進行 padding,確保它們適合於模型的評估和訓練
定義一個用於計算評估指標的函數 compute_metrics
from datasets import load_metric
metric = load_metric("seqeval")
def compute_metrics(p):
predictions, labels = p
predictions = np.argmax(predictions, axis=2)
true_predictions = [
[label_list[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
true_labels = [
[label_list[l] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
results = metric.compute(predictions=true_predictions, references=true_labels)
return {
"precision": results["overall_precision"],
"recall": results["overall_recall"],
"f1": results["overall_f1"],
"accuracy": results["overall_accuracy"],
}
-
metric = load_metric("seqeval")
- seqeval 庫提供了方便的方法來計算這些指標,特別適用於處理標記分類的序列資料,通過加載
seqeval 度量標準
-
predictions, labels = p
predictions = np.argmax(predictions, axis=2)
- 針對每個標記的各個標籤分數,選擇最高的類別來確認標籤
-
true_predictions = [
[label_list[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
true_labels = [
[label_list[l] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
-
results = metric.compute(predictions=true_predictions, references=true_labels)
return {
"precision": results["overall_precision"],
"recall": results["overall_recall"],
"f1": results["overall_f1"],
"accuracy": results["overall_accuracy"],
}
- 計算性能指標,包含精準度、召回率、F1值
(這些在下次講評估結果時會詳細講)
創建 Trainer 對象
from transformers import Trainer
trainer = Trainer(
model,
args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
-
Trainer是一個高級的訓練和評估工具,它簡化了很多流程,我們只需要傳入在訓練時我們所需要給的參數就好,包含定義好的模型、訓練參數、訓練資料等等。
8. 訓練模型 (微調)
trainer.train()
- 直接使用創建好的 Trainer 對向執行 train 方法就可以開始訓練
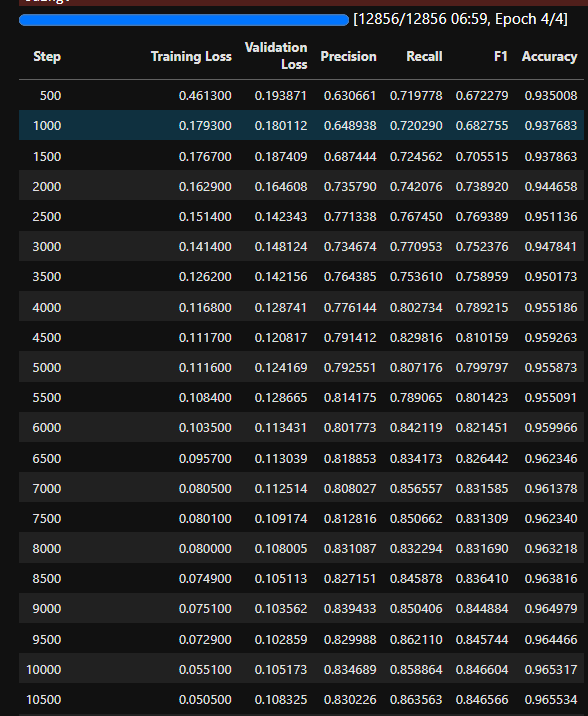
- 訓練時會像這樣照著我們設定的
eval_steps=500每500步做評估

