
前一篇提到Prompt 的基本技法,本篇開始會談一些進階式的用法,首先來看的是In-Context Learning。雖然前一篇的Prompt 基本技法在多數的基本應用場景下,已經可以讓模型生成不錯的回應,但是在複雜的場景下,就不是那麼足夠了,特別是我們都知道以ChatGPT模型來說,它的訓練集資料處理2021年為止,表示著如果沒有對模型本身做資料的更新,那麼它就只能就預訓練的知識去生成回應,但是如果要更新ChatGPT模型,成本又太高並具效果未知(例如Fine-tuning),因此通常會建議先採取In-Context Learning技法。
接下來的內容均以ChatGPT-4模型做為示範
In-Context Learning,就字面的直譯為"在上下文中學習",本質上是一種讓語言模型在特定的上下文中學習的技術。In-Context Learning與微調(fine-tuning)不同,In Context Learning不需要重新訓練模型,而是透過prompts來引導模型。例如,如果我們想教模型學習一個新的詞語或概念(不在模型預訓練的資料集中),可以在prompts提供一些關於這個詞語或概念的描述,然後再問模型,模型就可以根據這個特定的上下文進行學習和回應。
這個例子展示了一個In-Context Learning的結果,當我們在prompts給予動物與食性的範例後,接著問ChatGPT,ChatGPT能夠明白我們的意思,並回應出相對的答案。這個過程中並未涉及到調整ChatGPT內部資料的動作(事實上如果做Fine-tuning,所需要的資料集遠遠大於這幾個詞句)。
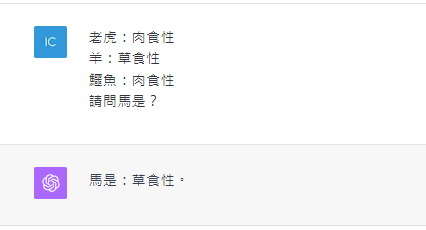
然而In-Context Learning是教會ChatGPT新知識嗎?
根據"Rethinking the Role of Demonstrations:What Makes In-Context Learning Work?"論文研究顯示In-Context Learning技法是教會模型學習特定的表達風格,就像上面的範例,詞句的風格是"動物VS食性",而非動物與食性間的真正關聯性。
研究發現首先給模型幾個範例(demonstrations),告訴模型需要學習怎樣的對應,接著進行詢問,模型就能給出對應的label。

(來源:https://arxiv.org/pdf/2202.12837.pdf)
圖中顯示範例資料中正確標籤比例的下降,對預測結果的影響幾乎可以忽略,也就是說模型其實並不是真正學習範例資料的對應關係性,其比較可能是學習到語義關係或是風格,例如海洋->魚、陸地->大象

研究中隨機替換資料的標籤,沒有保持一致性,其測試結果模型表現就明顯下降,例如:老虎—>動物,獅子—>4隻腳,魚->水裡,如此一來變混亂了,模型無法學習一致的關聯性,就無法表現的很好
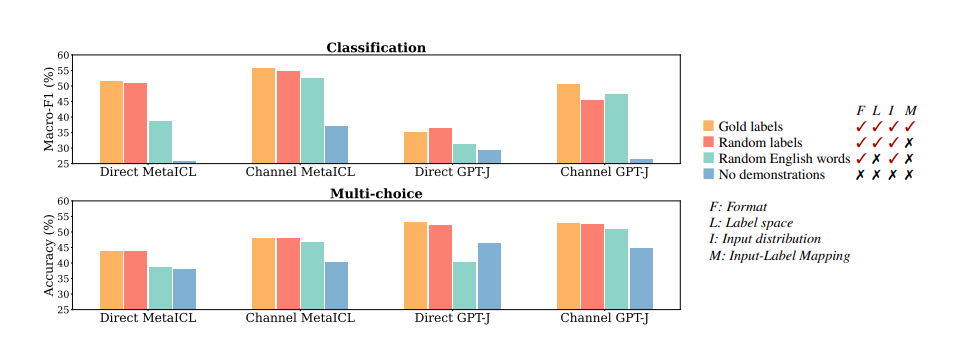
不過要注意的是,任何研究都有其限制,當研究的模型不同,模型大小不同,都有可能產生不同結論,因此這篇研究只是代表使用In-context learning確實對於模型的生成有所影響
那麼既然可以使用 In-context learning 讓模型在不更新訓練資料的情況,做即時學習和回應,那通常採到哪些技法來處理呢?
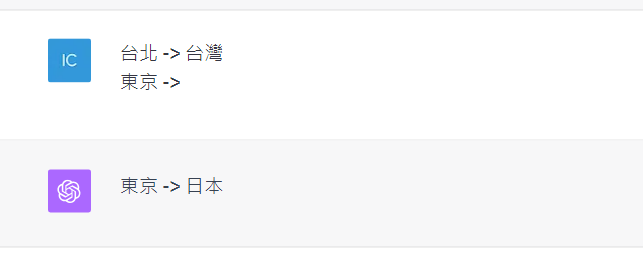


現在我們理解了In-Context Learning的概念,以及Zero shot / One shot / Few shot技法,只要透過Prompts注入了範例,讓模型能基於範例學習,就能創造更多的生成回應,這個技法完全不需要更新模型參數或是重新訓練模型,便可以賦予模型即時學習和適應的能力。
參考資料:https://arxiv.org/pdf/2202.12837.pdf
嗨,我是Ian,我喜歡分享與討論,今年跟2位朋友合著了一本ChatGPT主題書,如果你是一位開發者,這本書或許會有些幫助,https://www.tenlong.com.tw/products/9786263335189
這次的鐵人賽文章也會同時發佈於個人blog,歡迎關注我的blog : https://medium.com/@ianchen_27500
