2023 iThome 鐵人賽
分享至
與監督學習相反,這種學習方法是用沒有經過標籤的原始數據集下去做訓練,目標是從未標籤數據中發現其結構或群集。這種無須事先對資料加以標籤,而是讓模型去自己發現資料的結構模式,常用在難以被分類的資料。
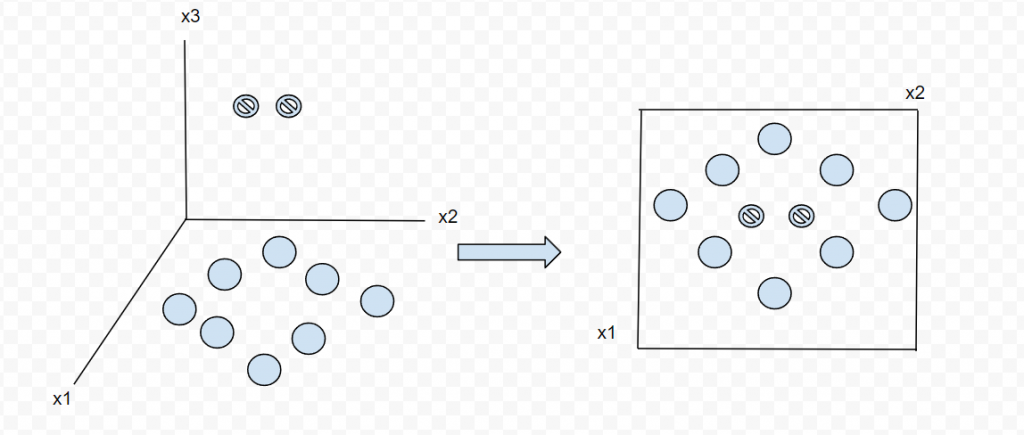
在社交網絡中,可以幫助辨識在各種方面相似的用戶或群體,從而提升社交媒體平台用戶體驗的和改善社交分析。(聚類方法)在音頻訊號的處理中,可以用在數據的特徵訊息保留和壓縮處理,可以幫助去除某些不必要的訊息,如躁聲,還可以節省儲存空間和傳輸頻寬。(降維方法)
IT邦幫忙