昨天我們介紹完捲積這個在影像處理當中很重要也很好用的工具,今天我們會沿著這個節奏往下介紹由它所建構出來的捲積神經網路(Convolutional Neural Network),最後也會有個簡單的實戰,讓大家感受一下這樣的模型是怎麼運作的,以及在設計的時候有哪些需要留意的事情。
昨天討論的內容比較偏向理論或概念,所以在正式開始實戰之前,我們藉由介紹捲積神經網路這個架構,來深入了解一下要如何把捲積這個概念應用在AI模型中。
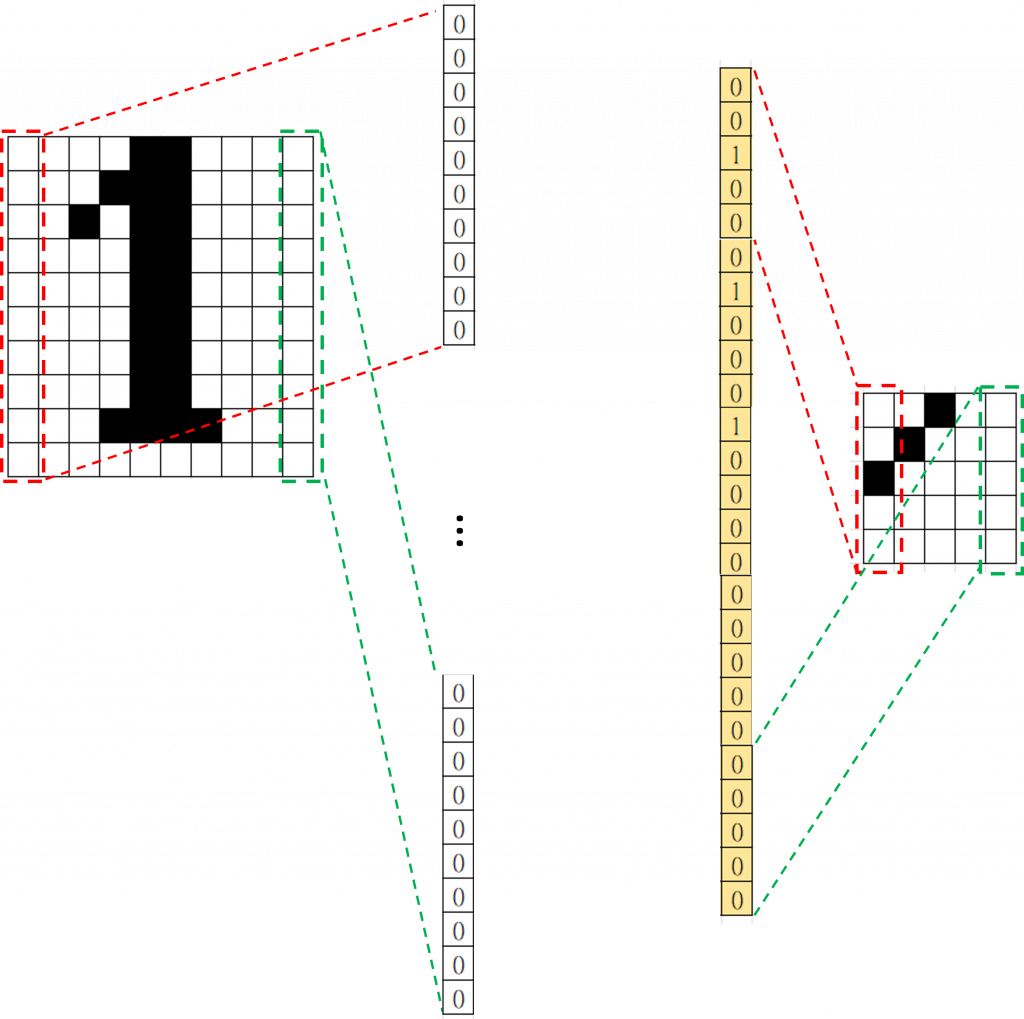 最後就是像之前我們做的一樣,將中間所有節點彼此相連去計算那條線的權重多少,如果權重越高,代表那個輸入節點跟目標節點之間的關係越強,「有多少條線,就代表有多少權重需要學習」
最後就是像之前我們做的一樣,將中間所有節點彼此相連去計算那條線的權重多少,如果權重越高,代表那個輸入節點跟目標節點之間的關係越強,「有多少條線,就代表有多少權重需要學習」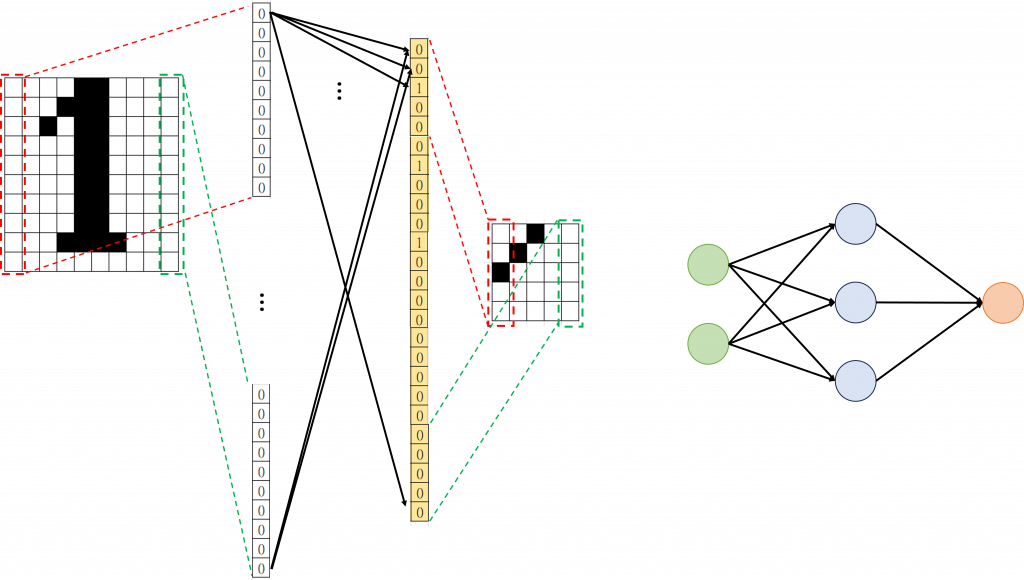 右邊是我們之前討論過的MLP架構,跟左邊我們在做的事情是一樣的,只是畫法上有些差異。
右邊是我們之前討論過的MLP架構,跟左邊我們在做的事情是一樣的,只是畫法上有些差異。 與MLP最大的差異就在這邊,因為在CNN中,我們需要學習的就是「核」要怎麼設計,所以這個「核裡面有多少元素就代表我們就多少參數需要學習」,以上圖為例就是5*5,跟MLP相比是不是少了很多!
與MLP最大的差異就在這邊,因為在CNN中,我們需要學習的就是「核」要怎麼設計,所以這個「核裡面有多少元素就代表我們就多少參數需要學習」,以上圖為例就是5*5,跟MLP相比是不是少了很多! 池化層設計的重點在如何從左邊變到右邊,也就是「要如何挑選元素」,以及「經過挑選之後的圖片大小」,這兩個關鍵我們會在實作的時候看到具體的運作方式。
池化層設計的重點在如何從左邊變到右邊,也就是「要如何挑選元素」,以及「經過挑選之後的圖片大小」,這兩個關鍵我們會在實作的時候看到具體的運作方式。nn.Conv2d裡面不同的參數設定,看看輸出跟輸入大小之間的關係如何變化:import torch
import torch.nn as nn
# Create a simple input tensor (batch size, channels, height, width)
input_tensor = torch.randn(1, 1, 28, 28)
# Example input with 1 channel (grayscale) and 28x28 resolution
# Define a 2D convolution layer
conv_layer = nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=1)
# Forward pass through the convolution layer
output = conv_layer(input_tensor)
# Print the output shape
print("Output shape:", output.shape)
stride 指的就是每一滑動的間隔,而padding 則是控制輸出圖片的大小,因為正常經過捲機運算之後得到的圖片會小於原先的輸入圖片,所以我們可以在一開始就先把輸入圖片外圍填充一圈別的元素,讓最後輸出的圖片可以大一點。
import torch
import torch.nn.functional as F
# Create a sample 2D tensor
input_tensor = torch.tensor([[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[13, 14, 15, 16]], dtype=torch.float32)
# Max Pooling Example
max_pooling_result = F.max_pool2d(input_tensor.view(1, 1, 4, 4), kernel_size=2, stride=2)
print("Max Pooling Result:")
print(max_pooling_result)
# Average Pooling Example
avg_pooling_result = F.avg_pool2d(input_tensor.view(1, 1, 4, 4), kernel_size=2, stride=2)
print("\nAverage Pooling Result:")
print(avg_pooling_result)
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
# Define the CNN model
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)
self.relu = nn.ReLU()
self.maxpool = nn.MaxPool2d(kernel_size=2, stride=2)
self.fc1 = nn.Linear(32 * 14 * 14, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.maxpool(x)
x = x.view(x.size(0), -1) # Flatten the tensor
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
# Hyperparameters
batch_size = 64
learning_rate = 0.001
num_epochs = 10
# Load MNIST dataset and apply transformations
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
# Initialize the model
model = SimpleCNN()
# Loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# Training loop
total_step = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward pass and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{total_step}], Loss: {loss.item():.4f}')


 iThome鐵人賽
iThome鐵人賽