Pandas 的優勢在於可以處理大型數據,方便使用者觀察和分析,但處理數據前需要先載入資料,因此,本文將說明如何透過檔案路徑讀取外部資料,內容包含:
- 介紹檔案路徑
- 確認檔案位置
- 使用pandas讀取檔案
■ 介紹|檔案路徑
-
相對路徑:以目前 python 程式碼檔案所在位置為基準,標示欲讀取檔案的所在位置
(1) 特點:保持程式和檔案的相對關係時,無論怎麼移動都可以找到,建議使用!
(2) 舉例:假設目前python程式碼檔案的位置在「D:\桌面\【文章】2023鐵人賽」
- 當前路徑(./),相當於「D:\桌面\【文章】2023鐵人賽」
- 當前路徑的上一級(../),相當於「D:\桌面」
- 當前路徑的下一級(./data),相當於「D:\桌面\【文章】2023鐵人賽\data」
-
絕對路徑:從磁碟機根目錄為基準,標示欲讀取檔案的所在位置
(1) 特點:保持同一個磁碟機路徑,程式執行檔在哪裡都可以
(2) 舉例:「D:\桌面\【文章】2023鐵人賽」
■ 實作|確認檔案位置
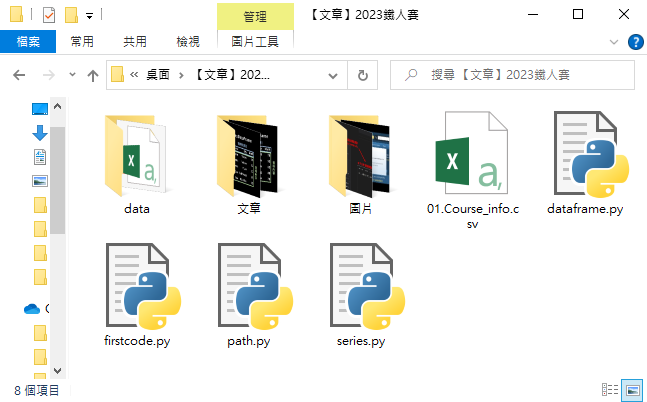
我自己習慣將同份專案的資料和程式碼放在同一個資料夾中,以利後續檔案管理或程式操作!以下圖為例,該資料夾中包含:
- 一個CSV檔:01.Course_info.csv
- 四支程式碼:dataframe.py、firstcode.py、path.py、series.py
- 三個子資料夾:data、文章、圖片
其中資料夾 data 中有一個CSV檔(02.Comments.csv)
■ 方法|使用pandas讀取檔案
- 操作語法
(1) 讀取CSV:pandas.read_csv( )
(2) 讀取EXCEL:pandas.read_excel( )
(3) 讀取JSON:pandas.read_json( )
- 執行檔案與欲讀取檔案位於「相同」當前路徑
舉例:讀取上方案例資料夾中,與執行檔同一層級的「01.Course_info.csv」
import pandas as pd
df = pd.read_csv('01.Course_info.csv')
- 執行檔案與欲讀取檔案位於「不同」路徑
舉例:讀取上方案例資料夾中,在執行檔下一級路徑(data資料夾)裡的「02.Comments.csv」
import pandas as pd
df = pd.read_csv('./data/02.Comments.csv')
■ 結語
檔案路徑的敘述有盡可能簡單明瞭,但不確定文字說明是否對於讀者來說會有點小吃力,希望大家都能跟上!如果有任何不理解、錯誤或建議的話,歡迎大家留言給我!喜歡的話,也歡迎按讚訂閱!
明天,我會以 Kaggle 案例實作一次讀取外部資料,並帶大家一起操作觀察數據的幾個方法!我是 Eva,一位正在努力跨進資料科學領域的女子!我們下一篇文章見!Bye Bye~【本篇文章將同步更新於個人的 Medium,期待與您的相遇!】


 iThome鐵人賽
iThome鐵人賽