在進行數據分析前,需要先了解資料的內容,以利後續資料清理、特徵工程等處理,因此本篇將延續昨日主題,以實際案例實作一次讀取外部資料,並使用基本語法觀察資料內容!話不多說,Let’s Go~內容包含:
資料的來源有很多種,可能是網路上政府公開資料,也可能是 Kaggle 上的資料集,以下將以 Kaggle 的 Udemy Courses 資料集做為範例和大家實戰一次!
1. 建立專案資料夾:【文章】2023鐵人賽
2. 建立執行程式:load.py
(1) 開啟 VS Code 與專案資料夾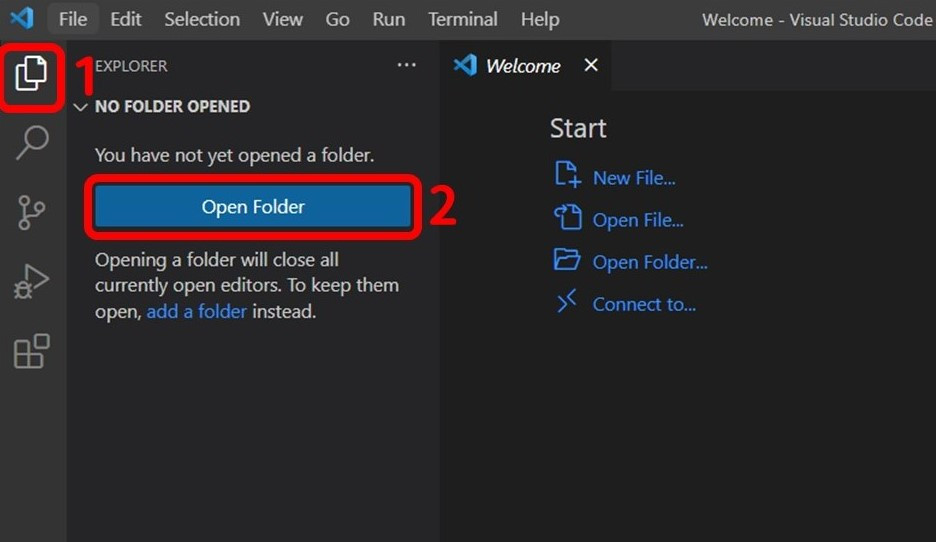
(2) 新增檔案並命名(⚠️ 寫Python,記得檔名後面要加「.py」)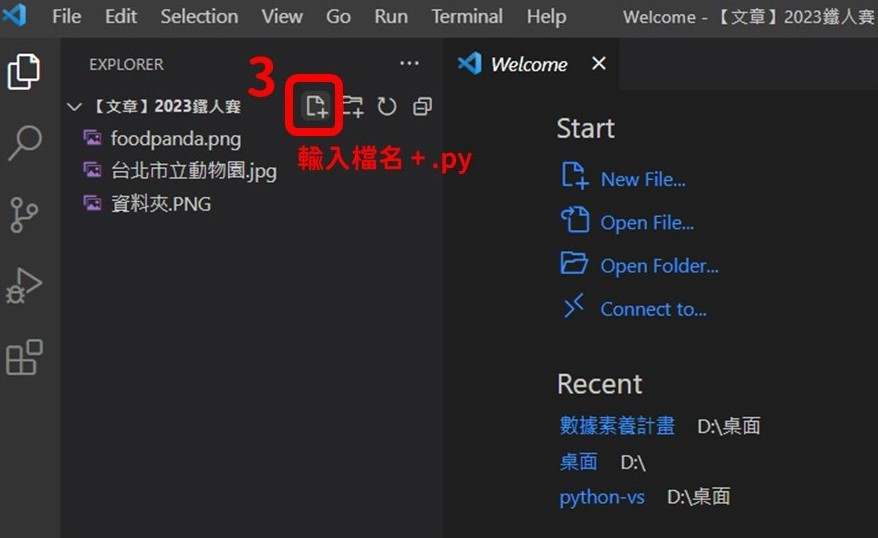
3. 下載資料並存放於專案資料夾中
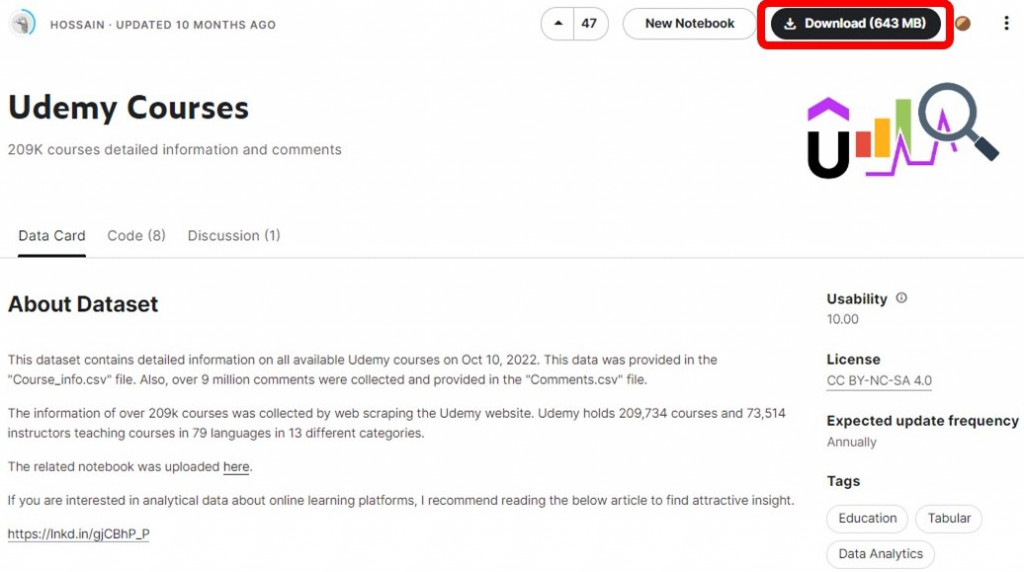
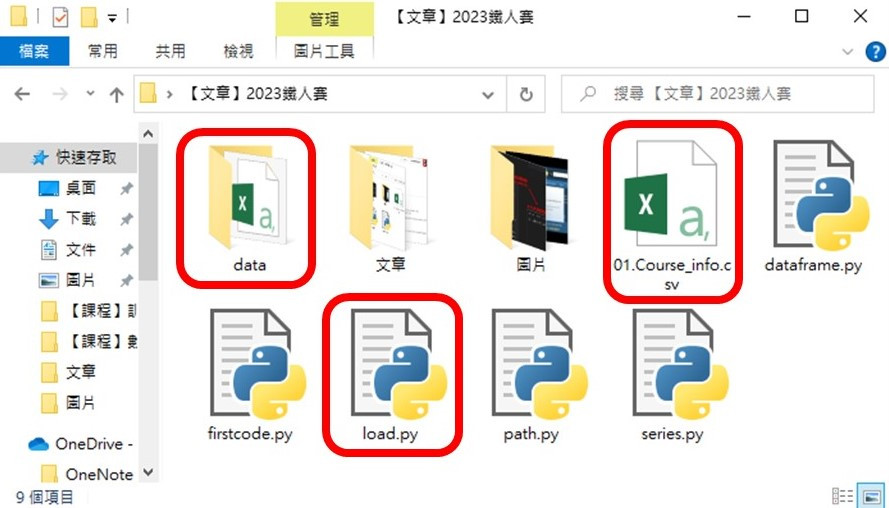
4. 讀取檔案:於 load.py 檔中,撰寫程式碼並執行
(1) 讀取與執行檔位於相同路徑的「01.Course_info.csv」
import pandas as pd
df = pd.read_csv('01.Course_info.csv')
print(df)
輸出結果:有20個欄位,209734筆資料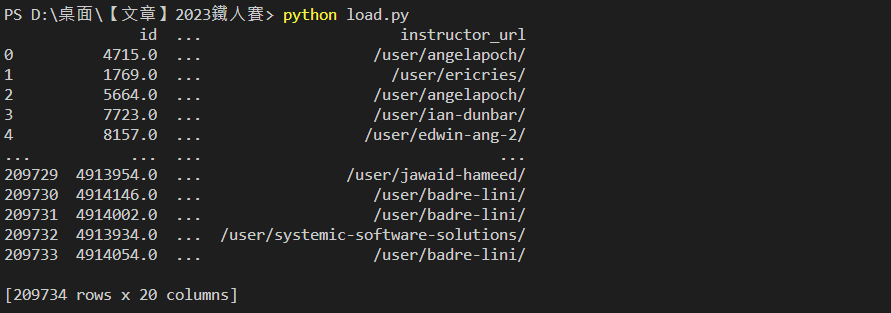
(2) 讀取與執行檔位於不同路徑,在下一級路徑(data資料夾)中的「02.Comments.csv」
import pandas as pd
df = pd.read_csv('./data/02.Comments.csv')
print(df)
輸出結果:有6個欄位,9411727筆資料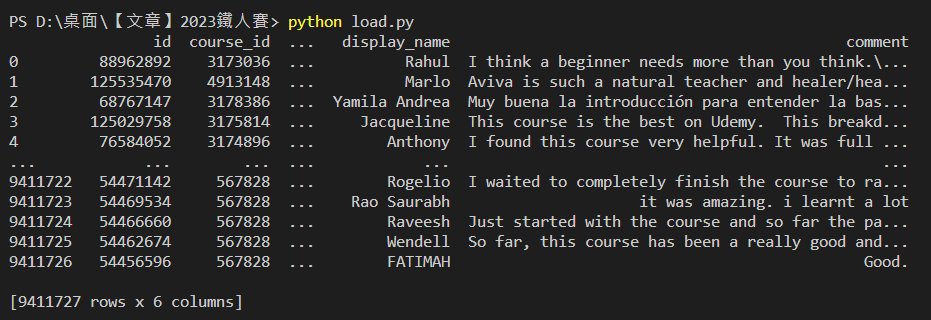
程式碼最後撰寫 print(df) 會將全部的資料印出,但有時僅需部分內容,此時使用下列幾種語法:
info():檢視檔案資訊print(df.info())
輸出結果: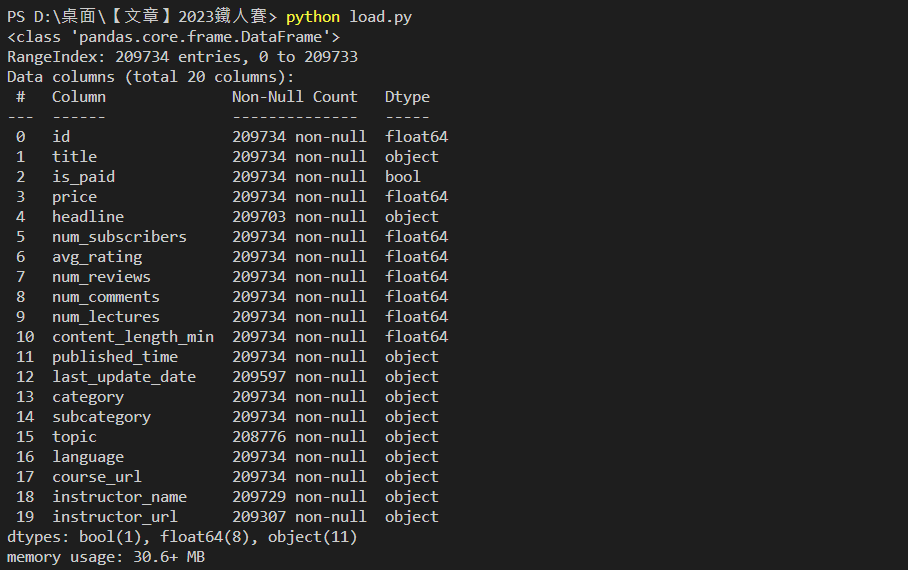
head():取得前幾筆資料,預設為 5,也可自行在括號中加入需要的數字print(df.head())
輸出結果: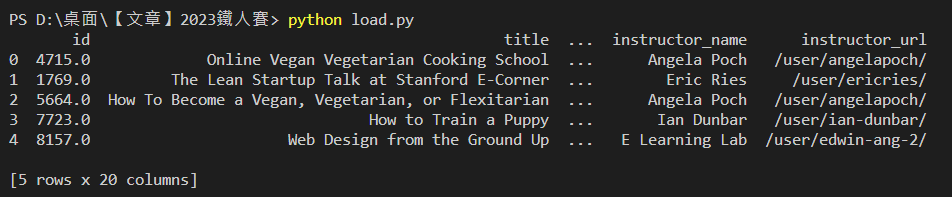
tail():取得最後幾筆資料,預設為 5,也可自行在括號中加入需要的數字print(df.tail())
輸出結果: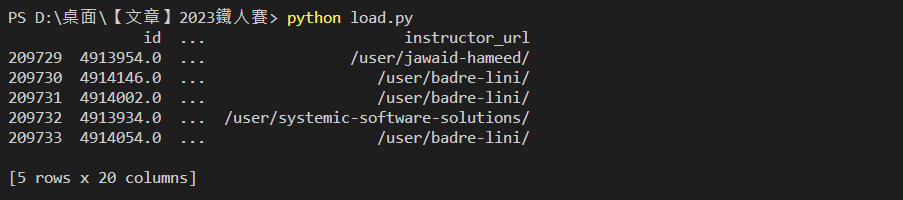
describe():檢視數值欄位統計摘要print(df.describe())
輸出結果: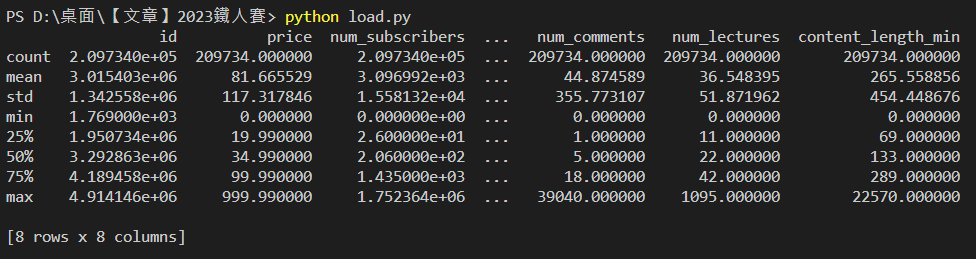
想要學習使用Pandas讀取外部資料的邦友們,可以按照內文實作看看喔!
如果有任何不理解、錯誤或建議的話,歡迎留言給我!喜歡的話,也歡迎按讚訂閱!
我是 Eva,一位正在努力跨進資料科學領域的女子!我們下一篇文章見!Bye Bye~
【本篇文章將同步更新於個人的 Medium,期待與您的相遇!】

