今天來介紹 Pod 相關的屬性及設置:
我們可以定義運行 Containers 時要跑的 Commands & Arguments,與 docker Dockerfile 中的 ENTRYPOINT & CMD 對應。
Dockerfile
FROM Ubuntu
ENTRYPOINT ["sleep"]
CMD ["5"]
Kubernetes configuration file
apiVersion: v1
kind: Pod
metadata:
name: busybox
spec:
restartPolicy: Never
containers:
- name: busybox
image: busybox
command: ["sh", "-c"]
args: ["echo $(date); sleep 1; echo 'Hello'; echo $(date)"]
這邊要注意 Dockerfile 中 CMD 在 kubernetes yaml 中的參數是 args。ENTRYPOINT 對應的是會執行的 command。
建立 pod 後利用 kubectl logs 查看 log,可以看到印出了時間1、Hello、時間2。
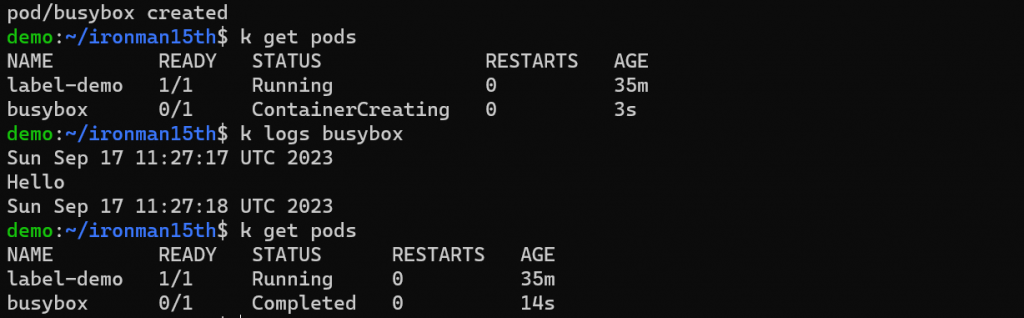
因為用 busybox 這個 image 跑的 Container 執行完這些指令後就沒事做了,類似於 docker,如果主要 process 執行結束就會 Exit。因 kubernetes 預設 restartPolicy 是 Alwasys,如果 container exit,kubelet 會嘗試一直重啟這個 container,我這邊更動 restartPolicy 變成 Never,如果 exit 就 exit 了。
再利用 kubectl describe 查看 pod status & event -
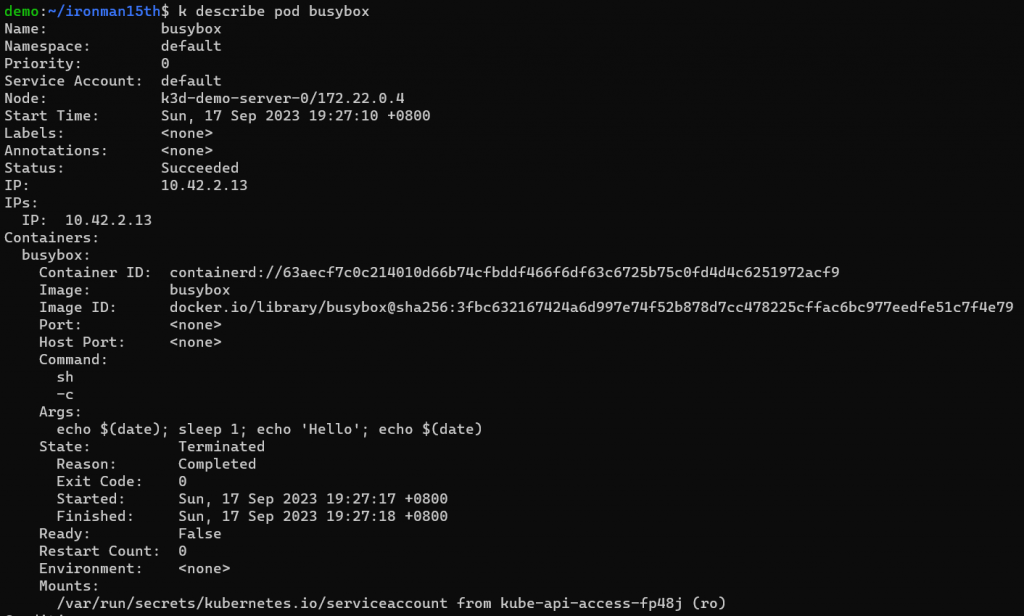
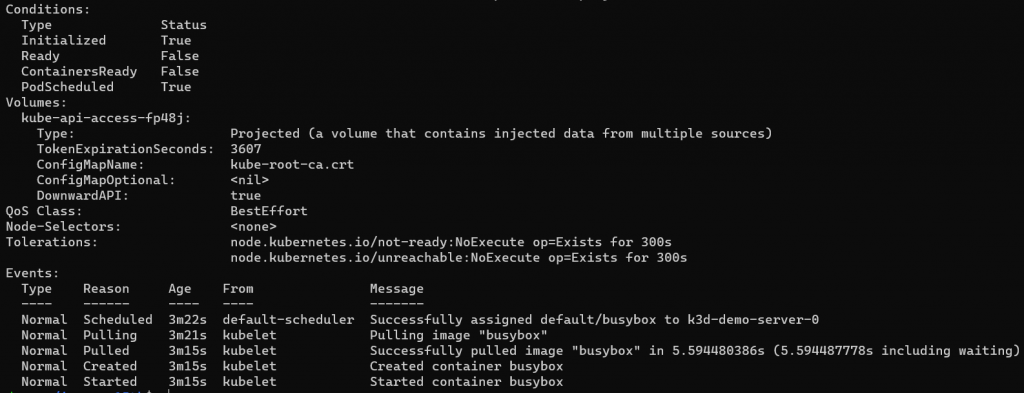
可以看到我們定義的 Command & Args,還有底下的 Events,有時如果 Pod 無法運行成功也可以透過 kubectl describe -n <namespace name> <type> <object name> 查看有沒有什麼錯誤訊息。
從前面的圖可以看到列出 pods 也會一併列出 Pod Status -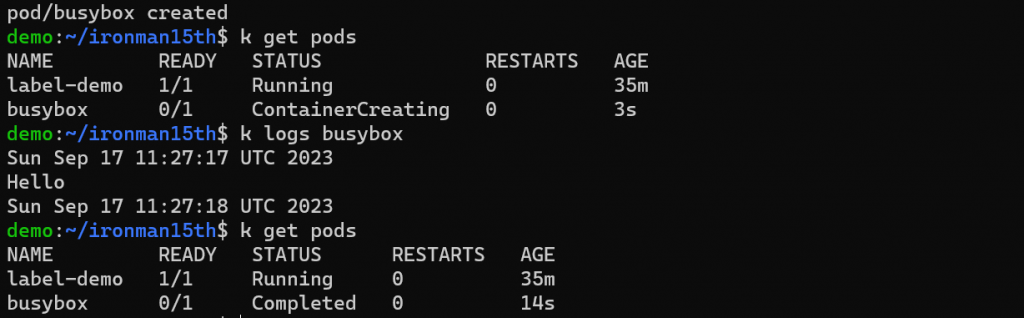
kubectl describe 的 output 中也有列 Container State -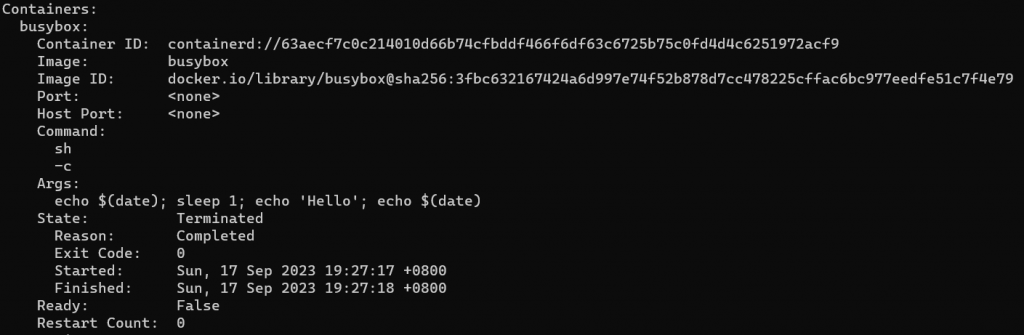
Pod 中跑著一個或多個 Container,這裡面就是要提供服務的應用,在管理上掌握 Pod 的生命週期、確認它是否健康、不健康要重啟就是很重要的事啦。接下來來看看 Pod 狀態、Container 狀態在 kubernetes 中是怎麼樣。
Pod 的生命週期分成 Pending、Running、Succeeded/Failed、Unknown 這幾種 Phase。可以從 kubectl describe output 中觀察。
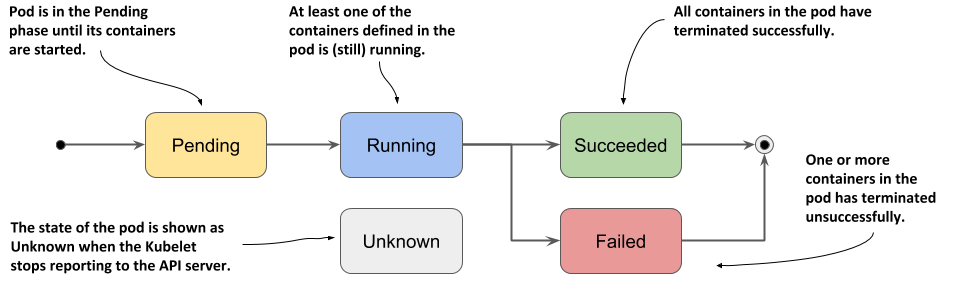
Source: https://bobcares.com/blog/kubernetes-pod-states/
使用 kubectl get pods 指令時,可以看到 Pod 在哪個階段。例如 Pod 還沒被分配到 Node 上會是 Pending、運行中會是 Running 。不過如果是錯誤的情況會顯示錯誤的原因,如果是完成階段性任務且 Container 終止,則會顯示 Completed。
Kubernetes 也會追蹤 Container 的狀態,Container states 有 Waiting、Running、Terminated 三種。
如果 State 是 Running,表示 Container 正在運行中;Terminated 則是這個容器已經終止,有可能是已經完成工作或是因為某些原因失敗;Waiting 則是當 Container 不是前述兩個狀態時,就會是 Waiting。
Container State 一樣可以從kubectl describe output 中觀察,包含為什麼會在這個 State 的原因。
上一段也有提到 Pod spec 中我們有定義 restartPolicy ,可能的值有 Always 、OnFailure、Never 。這個重啟策略是適用於 Pod 中所有容器,會由 kubelet 重新啟動容器,重新啟動的間隔會越來越長,如 10s, 20s, 40s, … 最長等待的時間不會超過 5 分鐘。如果容器運行 10 分鐘都沒問題,kubelet 會重設這個容器的重啟時間的 timer。
Note: restartPolicy 是定義在 Pod level,但重啟的對象是 Container
kubectl describe output 中的 Conditions 區塊包含了下面四種類型: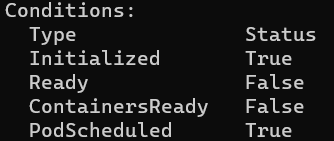
Initialized: 所有 init containers 都成功啟動Ready: Pod 可以接受 requests 了ContainersReady: Pod 中的所有 Containers 都 ReadyPodScheduled: Pod 被安排到 Node 上以剛才跑的 pod 為例,因為沒有 init container,所以 Initialized 這部份算是完成;PodScheduled 也完成,Pod 已經被分配到某一個 node 上;但因 Container 已經終止,所以 ContainersReady & Ready 這兩項都會是 False。
Probes 是 kubelet 檢查 Container 狀態的一個設計。為什麼會需要 Probes 呢?有些場景是 Web server 需要較長的暖機時間,雖然 Web UI 已經出現但可能還需要再幾秒 server 才能開始回應請求。但如果 Pod 被視為 Ready 的時候,就會被視為可接受請求。另外也有可能應用程式雖然在運行,但不一定能夠成功回應,這時會需要重新啟動。我們該怎麼偵測這種狀態以及讓 Pod 自動重啟?Kubernetes 有幾種 Probe 來監測 Pod 的健康程度:readinessProbe、livenessProbe、startupProbe。
先來看個 redis 的例子
apiVersion: v1
kind: Pod
metadata:
name: redis-server
spec:
containers:
- name: redis
image: redis:latest
ports:
- containerPort: 6379
livenessProbe:
tcpSocket:
port: 6379
initialDelaySeconds: 10
periodSeconds: 5
timeoutSeconds: 10
readinessProbe:
exec:
command:
- "redis-cli"
- "ping"
initialDelaySeconds: 10
periodSeconds: 3
timeoutSeconds: 5
使用 Probe 來檢查 Container 狀態有四種方法 -
上面的例子 livenessProbe 是使用 tcpSocket 的方法來判斷 redis 這個 container 是否還活著,kubelet 能跟這個容器建立 TCP 連線則算成功。readinessProbe 則是利用 redis-cli 對 redis 發出 ping 這個請求,用這個方式來判斷 redis 是否能接收請求。
在 Probe 的配置上有不同的選項可以控制探測的頻率、怎樣算是成功等等。比較常用的有:
initialDelaySeconds: 等 container 啟動之後等待多久進行第一次檢查。而順序上 startup probe 會先於 liveness & readiness probe,因此 liveness & readiness probe 的 initial delay 會等到 startup probe 成功後才開始計算。periodSeconds: 檢查的間隔,預設是 10 秒,最小可設為 1 秒。timeoutSeconds: 多久才算是 timeout,預設 1 秒,最小可設為 1 秒。successThreshold: Probe 檢查失敗後,被認為成功的最小連續請求成功次數。預設 1,對 liveness & startup probes 來說必須為 1 。failureThreshold: 幾次失敗才將這個 container 視為還沒準備好接受請求/不健康。readinessProbe 從名稱可以猜到,這是來判斷 Pod 是否能被視為 Ready (能對請求做出回應) 的 Probe。如果 readinessProbe 的結果是成功的,則這個 Pod 就能接受請求。
判斷 Container 是否正常運行,如果檢查失敗就視為不健康。會根據 Pod 設置的 restartPolicy 決定這個 Container 是否要重新啟動。
Readiness Probe & Liveness Probe 並沒有先後順序的關係,Liveness Probe 檢查成功不代表 Readiness Probe 成功。如果希望控制某些檢查的順序,可利用 initialDelaySeconds & Startup Probe。
判斷 Container 中的應用程式是否已經啟動。Startup Probe 如果成功後其他 Probes 才會開始作用。如果 Startup Probe 失敗,kubelet 會殺掉這個容器然後根據 restartPolicy 重啟。
這邊跟著官網來觀察下 http request 怎麼寫,還有 liveness probe 檢查失敗的話會怎麼樣。
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- name: liveness
image: registry.k8s.io/liveness
args:
- /server
livenessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3
這邊利用 httpGet 來檢查,如果 HTTP 回應的 status code ≥ 200 並且 < 400 則視為成功。這個 image 的 source code 會讓 Container 啟動前 10 秒回應 200,但之後會回應 500。
利用 kubectl describe 可以看到 Event section 有成功紀錄、失敗重啟紀錄。
前十秒內沒有問題。
超過十秒,偵測到 Unhealthy,殺掉 Container 再重啟。
也可以透過 kubectl get pod -w 觀察 Pod 狀態的改變。-w 是 watch for changes 的意思。可以用這個指令觀察 k8s object 的變化。可以看到 Pod 每隔一段時間就會重啟,這邊 restartPolicy 是 Always,但重啟的間隔會越來越長。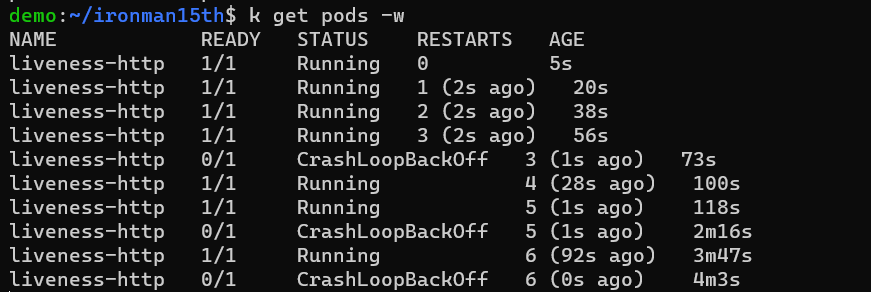
實際使用上 Probes 該怎麼設呢?像 Redis、MySQL 這種應用在網路上應該都能找到合適的 check mechnism 做設置。如果是網頁的話可能就要看使用場景或商業邏輯去設 HTTP Get path。檢查的間隔及秒數在 https://blog.pichuang.com.tw/20230529-kubernetes-probe.html 有看到一些建議。
Reference
https://kubernetes.io/docs/tasks/inject-data-application/define-command-argument-container/
https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/
https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/
https://www.baeldung.com/linux/kubernetes-livenessprobe-readinessprobe


 iThome鐵人賽
iThome鐵人賽