經過前幾日的訓練,我相信你已對自然語言處理有初步的理解,因此從今天開始,我將轉變教學方向,開始導讀現今NLP中常用的技術,而今天的主題我會介紹時間序列模型,今天我們會學習以下四個重點:
循環神經網路(Recurrent Neural Network, RNN)的優缺點長短期記憶(Long Short-Term Memory, LSTM)的各層功能門控循環單元(Gated Recurrent Unit, GRU)出現的目的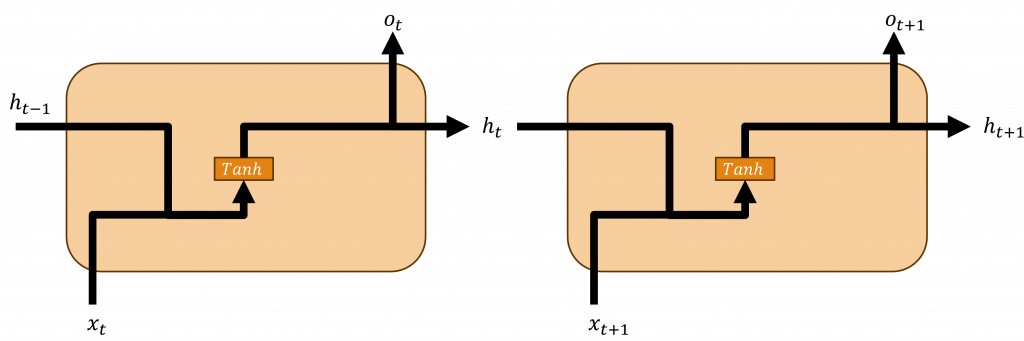
循環神經網絡(Recurrent Neural Network, RNN)的主要應用為處理序列數據,其特色在於其具備循環連接結構,可捕捉到序列數據中的時間依賴性與上下文資訊,我們可以透過比較下方兩個公式,來了解它與深度神經網路的不同點: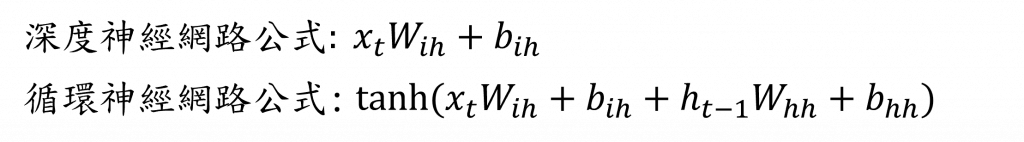
在上述兩個公式中,我們可以看到深度神經網路和循環神經網路之間的差異並不大,而循環神經網路最主要的概念就是,它能持續傳遞深度神經網路中的隱藏層結果並且與下一個序列進行運算,並且對該結果使用tanh函數,這個函數能返回一個介於-1與1的範圍,能有效地從而計算出下一隱狀態(Hidden State)的資料分布。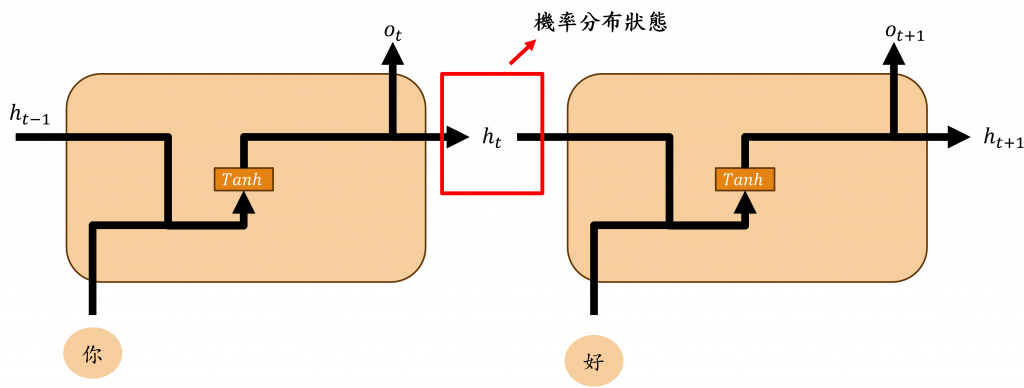
對於文字資料,我們能透過循環神經網路來計算前面文字的機率分布狀態,因此能夠考慮到文字的前後文關係,使我們在處理大量資料時,能更全面理解其文字訊息。
不過這種方式存在一個重大的問題,那就是當我們的輸入序列過長(一次輸入的文字太多)時,最初的序列資料可能會被遺忘,因為我們不斷的將資料傳送到下一層進行運算,這將導致在長時間的運算後,最初的序列資訊被稀釋掉,這種情況可能就會導致梯度消失(Gradient Vanishing)或梯度爆炸(Gradient Exploding)的問題發生。
小提示
梯度消失是指在深度神經網絡中,由於反向傳播算法計算出的梯度值變得極小接近於零,導致神經元的權重幾乎不會被更新,因此無法有效地進行訓練;梯度爆炸是指在深度神經網絡中,由於反向傳播算法計算出的梯度值變得過大,導致權重的更新變得極端,使得模型變得不穩定或無法達到收斂。
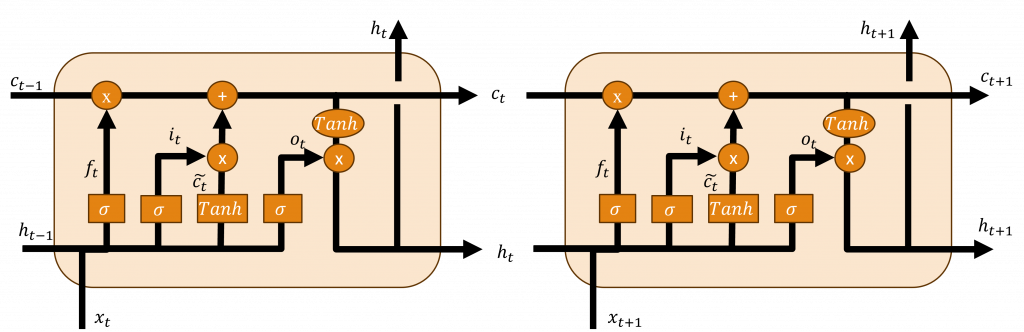
長短期記憶網絡(Long Short-Term Memory,LSTM)的設計就是為了解決循環神經網路中遭遇的梯度消失和梯度爆炸問題。它在原有的循環神經網路架構上新增了遺忘門(Forget Gate)、輸入門(Input Gate)、狀態保存層(Cell State)以及輸出門(Output Gate),透過這些部分,使其能更有效地處理長序列數據。
其中狀態保存層的設計是為了儲存重要的資訊,並將這些資訊傳遞至整個時間序列中,這些資訊的加入和移除過程,則需要透過輸入門和遺忘門的運算來實現,所以接下來我將介紹這些層的運算過程與其原理。
遺忘門主要透過計算上一個時間序的隱狀態與當前的輸入來調整狀態保存層中的內容,其實現公式如下所示: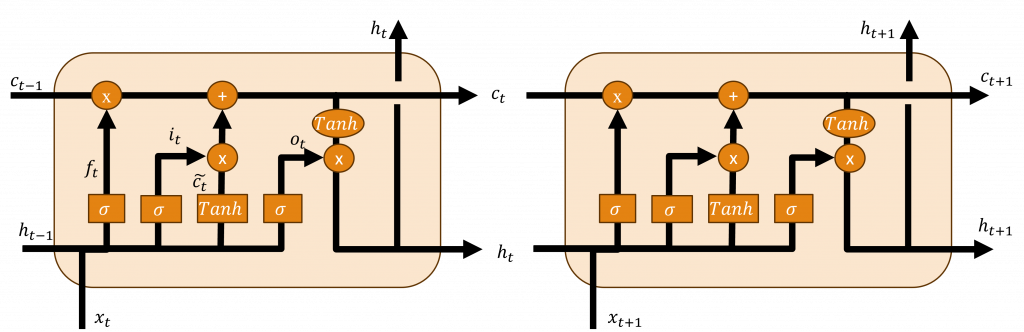
在該公式中代表著將輸入與上個時間序列的隱狀態進行計算,並利用σ(Sigmoid)轉換來獲取一個介於0和1之間的數值,這個數值用於決定哪些新的資訊需要被保留。當計算結果越接近1時,表示該數據較重要應該被保留;而當結果越接近0時則表示該訊息不夠重要可以被忽略,透過這樣的機制,使我們可以將重要的資訊保留,並將不重要的資訊剔除。
在輸入門中有兩個步驟,在兩個步驟中皆使用先前的隱狀態與當前的輸入進行計算,而在第一個步驟的計算公式與功能都與遺忘門相同,其計算公式如下: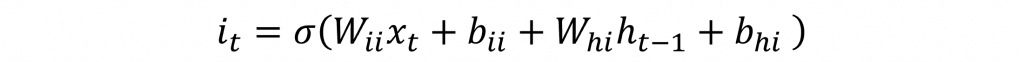
在該公式中的結果i(t)的計算與f(t)相同,只不過計算的權重是不相同的,因此它可以在計算上考慮更複雜的問題。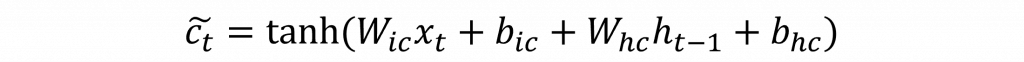
而在第二步驟,會先由先前的隱藏狀態和當前輸入串聯,接下來透過tanh來計算出h(t-1)與x(t)的資料分佈狀態,最後將這個分佈狀態與上述的i(t)進行計算,以確保該被遺忘的資訊不會被加入至狀態保存層中。
一旦我們計算出遺忘門層的輸出後,我們就可以計算該神經元中狀態記憶保存層中的資料,因此我們可以用以下公式來表示該層的狀態。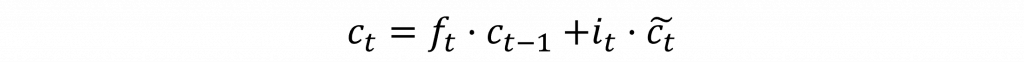
該公式代表著遺忘門主要負責從狀態保存層中遺忘資訊,並將新的資訊從輸入層加入到狀態保存層中。
在所有上述結果計算完畢之後,我們就能得到模型輸出至下一層的結果,該層會利用狀態保存層和當前層的向量分布狀態來進行運算,同時該層會先運用σ來忽視一些資料,其計算公式如下: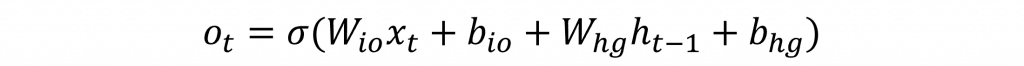
最後只需通過狀態保存層的資料分布狀態,並與上述的o(t)進行運算,就能計算出下一層的隱狀態了。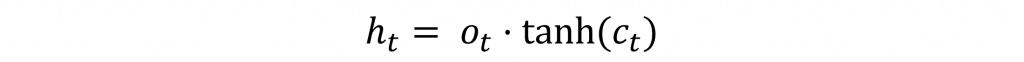
如此一來長短期記憶網絡便能夠計算出最終的答案,並通過狀態保存層傳遞重要的資料訊息,但該模型還存在一個問題,就是其計算公式過於複雜,導致運算速度極為緩慢。
門控循環單元(Gated Recurrent Unit, GRU)是一種長短期記憶的簡化版本,他簡化了一些不必要的公式,使在維持準確率的同時,增加計算的速度其架構主要由更新門(Update Gate)、重置門(Reset Gate)這兩個架構組成,並只使用單一隱狀態(Single Hidden State)傳遞資訊。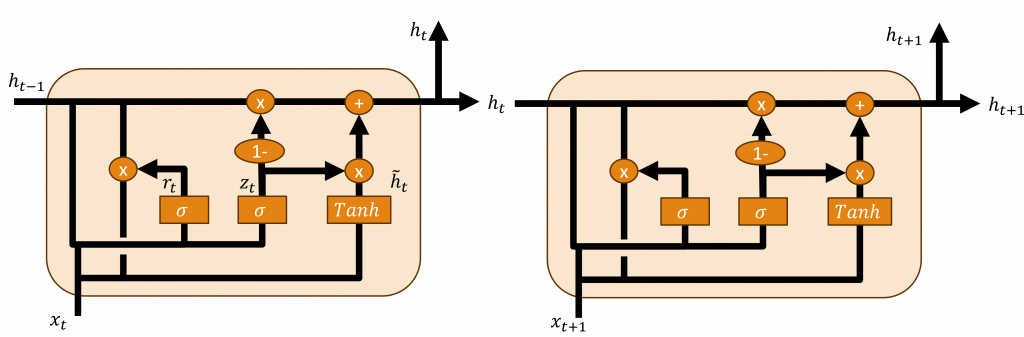
在更新門中主要簡化了長短期記憶的輸出門與輸入門,因此再該層中主要會更新門控循環單元單一隱狀態與並將其輸入到下一個神經元中,而該層的計算方式就是通過先前的隱狀態與當前的輸入進行計算,其公式如下: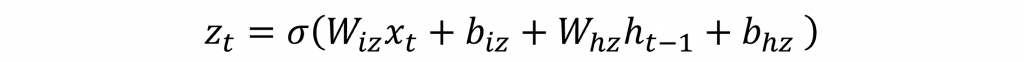
門控循環單元還設計了一個重置門,它的作用與長短期記憶相同,也就是透過當前的輸入與先前的隱狀態進行運算,以遺忘掉不重要的資訊,其公式也與長短期記憶相似。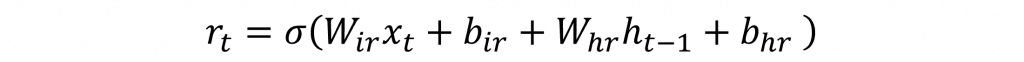
同樣的r(t)計算公式與z(t)相同主要就是權重不相同而已
在門控循環單元中,並未採用狀態保存層,而是只使用單一隱狀態,這部分的設計,就是增加運算速度的主要原因,它通過公式的變化,簡化了遺忘、更新、輸出動作的過程。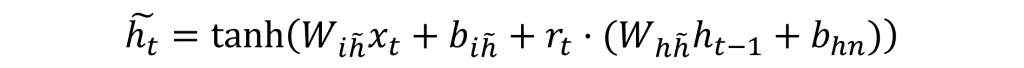
首先我們將先前計算出來的重製門結果r(t)與先前的隱狀態進行運算已計算出何種資料該被丟棄,接下來直接當前的輸入進行運算使這些新的資料能夠被加入到隱狀態中。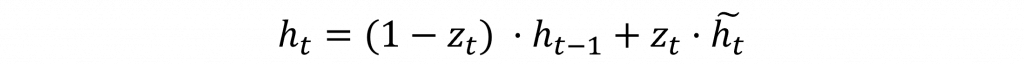
接下來因重製門的計算結果只保留了重要的資訊並遺忘掉無用的資訊並將該結果更新到單一隱狀態中,此時我們的單一隱狀態中包含了σ(h(t-1))與x(t)這兩個資訊,若我們再將更新門的資料透過σ運算時就會使單一隱狀態中σ(h(t-1))的數值變得更大,因此在此處更新時我們須透過z(t)的補數1-z(t)來遺忘該結果,使其能夠平均的傳遞到下一個神經元中。
在門控循環單元和長短期記憶之間的差別在於,門控循環單元在每一個神經元中進行完整的計算,而長短期記憶則是通過比對之前的序列資料來進行運算。
你今天可能會覺得大腦非常的混亂,因為我在今天解釋三個模型的公式,雖然我原先計劃將這三個模型單獨講解,但我認為一次性學習會有最好的效果,主要是因為所有的時間序列模型都彼此相連繫,這樣的方式可以增加你學習模型的速度,而明天我將會展示這三個模型的訓練方式,以及在處理大型資料集時其執行速度與準確率的比較。
那麼我們明天再見!
內容中的程式碼都能從我的GitHub上取得:
https://github.com/AUSTIN2526/iThome2023-learn-NLP-in-30-days


 iThome鐵人賽
iThome鐵人賽