
經過前20節的文章,了解模型訓練與預測相關運作後,接著實例應用並比較幾種損失函數與optimizer的搭配比較。這邊拿某集團企業的銷售資料訂單來做訓練範例。
資料內容為某年度的業務銷售訂單,每張單客戶可以一次付清或分期給付,每張銷售單號會有對應的申請日期。
訓練目的要讓機器幫忙辨認未來的案件報酬是否相符於此年度的前70%~80%之間的銷售案 ,排除80%以上的極端訂單與70%以下的普通或較差訂單。
因為訂單有很多因素構成,所以利用深度學習來幫忙找出訂單,將找出的訂單單號蒐集後,日後可以由系統調出這些單號來分析。而未來進件的單也可拿來判斷是否為符合報酬區間的案件。如果不是,那就可以調整訂單內容,使其可以趨近報酬範圍,讓業績可以趕上。
隨後也會產生其它的損失函數與optimizer搭配的結果。
步驟如下:
1.首先匯入資料到dataframe:
這邊是由資料庫匯出某年度資料至csv檔,但其實可以直接以python建立DB server連線,下SQL語法來擷取資料。
此用匯出資料來做範例示意。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
df = pd.read_csv('20230502052056.csv',
header=0,
names=["單號","date","期數","進貨價","手續費","印花稅",
"營所稅","貨物稅","保險費","特別稅",
"維護費","物品管理費","每期費用",
"銷項稅",
"商品估值","淨收入"]
)
idf = df.copy()
feature_names = list(idf.columns[:-1])
idf.dropna(inplace=True)
示意範例資料大約有80萬筆以上。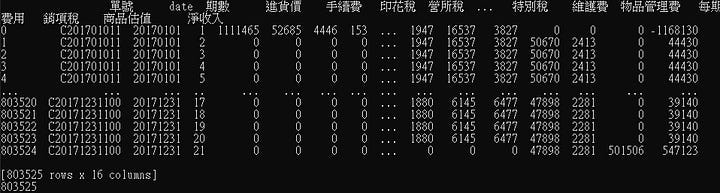
2.對資料作前處理,過濾處理不太合理的單子內容,並加上成本欄位;這部分依照資料內容來做處理,可與資料規劃師或系統分析師規劃討論,因各公司業務邏輯來做相關處理,此只是範例說明有做data pre-process。
def generate_cost(row):
cost = 0;
if row['期數'] == 1 :
if row['進貨價'] == 0:
cost = row['淨收入']
elif ( abs( abs(row['進貨價']) - abs(row['淨收入']) ) / abs(row['淨收入']) ) <= 0.05 :
cost = abs( row['淨收入'] )
else:
cost = row['進貨價']
return cost
new_col = 'cost'
columns=idf.columns.tolist()
columns.insert(2, new_col)
idf[new_col] = idf.apply(generate_cost, axis=1)
idf.loc[:, columns]
idf.set_index(["date", "單號"], inplace = True)
idf.dropna()
gpdf= idf.groupby(["date", "單號"]).sum() #將某單案件直接依照index合併起來
def generate_reward(row):
reward = 0.0
if abs(row['cost'])>0:
reward = ( row['淨收入'] ) / abs(row['cost'])
else:
reward = 1.0
return reward
new_col = 'reward'
columns=gpdf.columns.tolist()
columns.insert(2, new_col)
gpdf[new_col] = gpdf.apply(generate_reward, axis=1)
gpdf.loc[:, columns]
feature_names = ["進貨價","手續費","印花稅",
"營所稅","貨物稅","保險費","特別稅",
"維護費","物品管理費","每期費用",
"銷項稅",
"商品估值","淨收入"]
units = len(feature_names)
3.將資料做標準化
from sklearn.preprocessing import StandardScaler
Standard_Scaler = StandardScaler()
data_scaled = Standard_Scaler.fit_transform(gpdf[feature_names])
data_scaled = pd.DataFrame(data_scaled, index=gpdf.index, columns=feature_names)
print('data_scaled:',data_scaled)
data_scaled['reward'] = gpdf['reward']
data_scaled.describe()
4.建構模型
from keras import layers
import keras
from keras import optimizers
model = keras.Sequential()
model.add(layers.Dense(units, activation='relu', input_shape=(len(feature_names),)))
model.add(layers.Dense(1, activation='sigmoid'))
5.設定模型 compiler 參數,損失函數 為 binary_crossentropy,optimizer為 Adam
adam = optimizers.Adam(lr=0.001)
model.compile(loss='binary_crossentropy', optimizer=adam, metrics = ["accuracy"] )
6.訓練模型,並指定要辨認的資料為報酬率位於 70%~80% 之間的資料
data_scaled_train = data_scaled
Best_ValLoss_Model = keras.callbacks.ModelCheckpoint(filepath="ModelBestLoss",monitor="val_loss")
historyTrain = model.fit(data_scaled_train[feature_names],
( (data_scaled_train['reward'] >= data_scaled_train['reward'].quantile(0.7)) & (data_scaled_train['reward'] <= data_scaled_train['reward'].quantile(0.8)) )
,
batch_size = 1000, epochs = 1000 , validation_split = 0.1 ,
callbacks = [Best_ValLoss_Model ]
)
7. 將預測結果圖示化
PredictResult = model.predict(data_scaled_train[feature_names])
PredictResult = pd.Series(PredictResult.swapaxes(0, 1)[0], index=data_scaled_train.index)
dfResult = data_scaled_train.copy()
dfResult['PredictResult'] = PredictResult #預測未來哪些業績是幫助提升
dfResult['PredictCategory'] = dfResult['PredictResult'] >= dfResult['PredictResult'].mean()
dfResult = dfResult.reset_index()
PredictResultMean = dfResult['PredictResult'].mean()
#預測結果觀察
import seaborn as sns
plt.figure(figsize = (20,6))
sns.scatterplot(x='date' , y='reward' , hue = 'PredictCategory' , s = 5 , data = dfResult)
plt.show()
此例的 損失函數設定為 binary_crossentropy,optimizer設定adam,其學習率以預設的0.001 來操作,模型訓練時 batch size 為 1000, epoch 設定為 1000。
產生以下結果:
A. 損失值的變化,紅色為訓練資料,藍色為測試資料。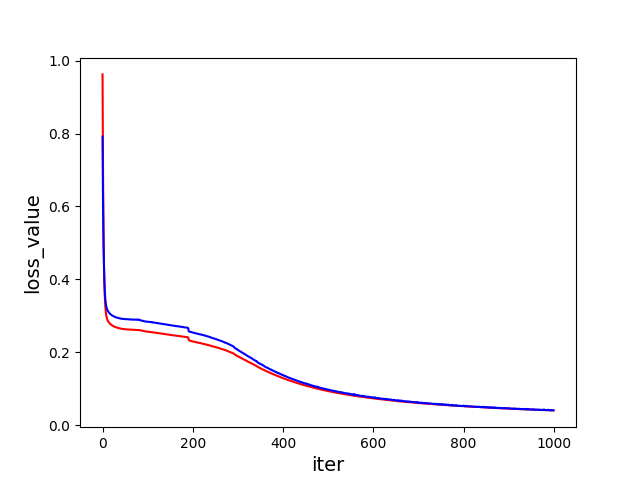
B. 橫軸為日期訂單編號,縱軸為報酬率,黃色為80萬筆資料中報酬率前 70%~80% 的資料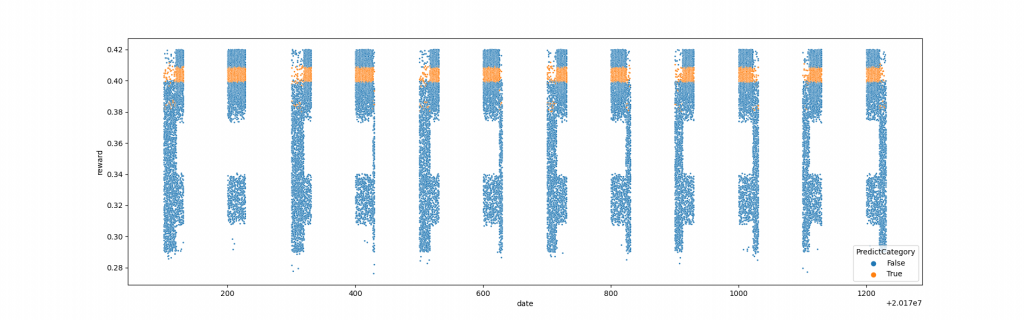
C. 觀察訓練準確率達0.99以上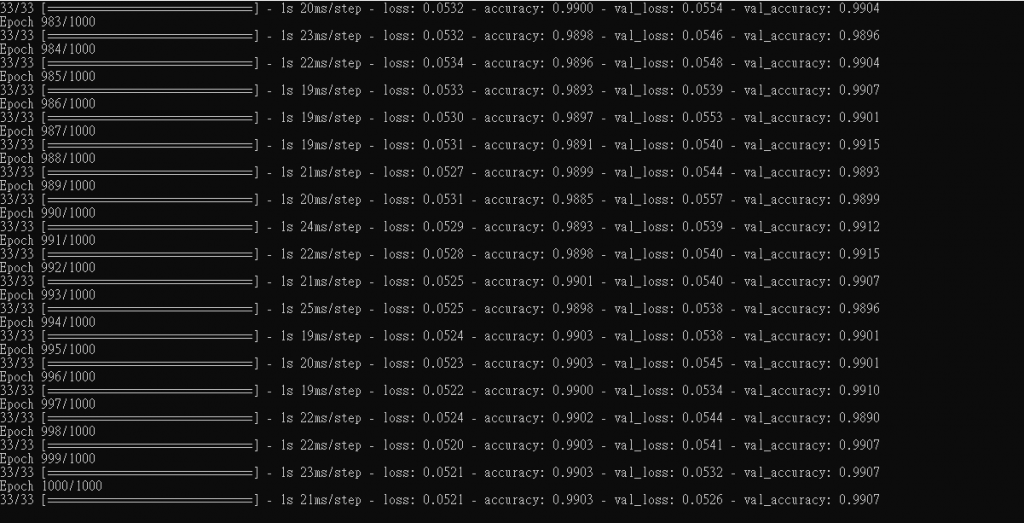
D. 紅色為預測報酬為前 70%~80% 的資料平均報酬 ,對上藍色非預測出的資料平均報酬,平均計算為每日計算。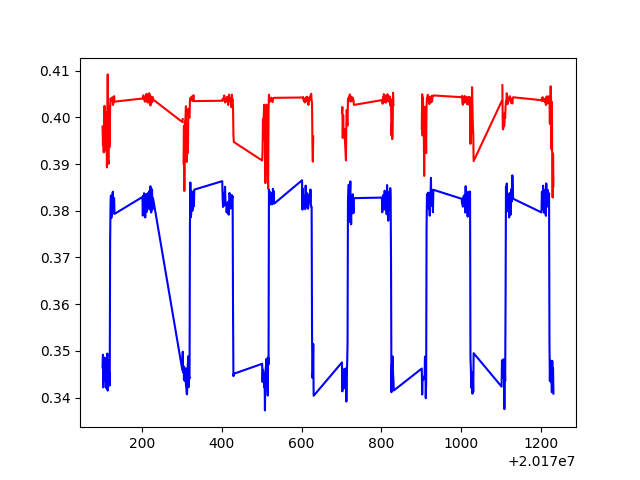
比較
將步驟5的損失函數與optimizer替換與比較。
由以下比較結果,可以看出 Binary Focal Crossentropy 搭配 Adam 收斂速度較快,但隨 epoch的增加其實準確率不相上下。
Loss Value 變化 (紅色為訓練資料,藍色為測試資料)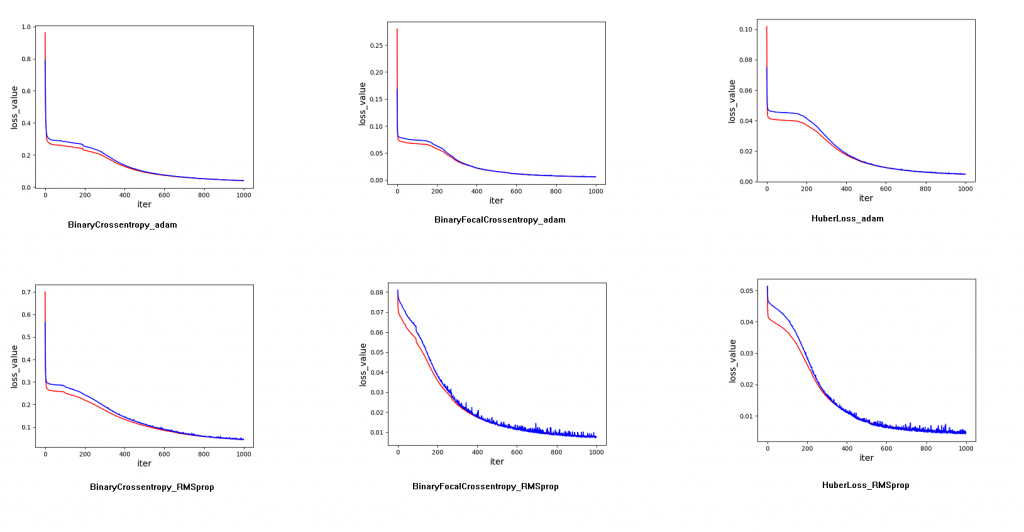
預測結果分佈,黃色為80萬筆資料中報酬率前 70%~80% 的資料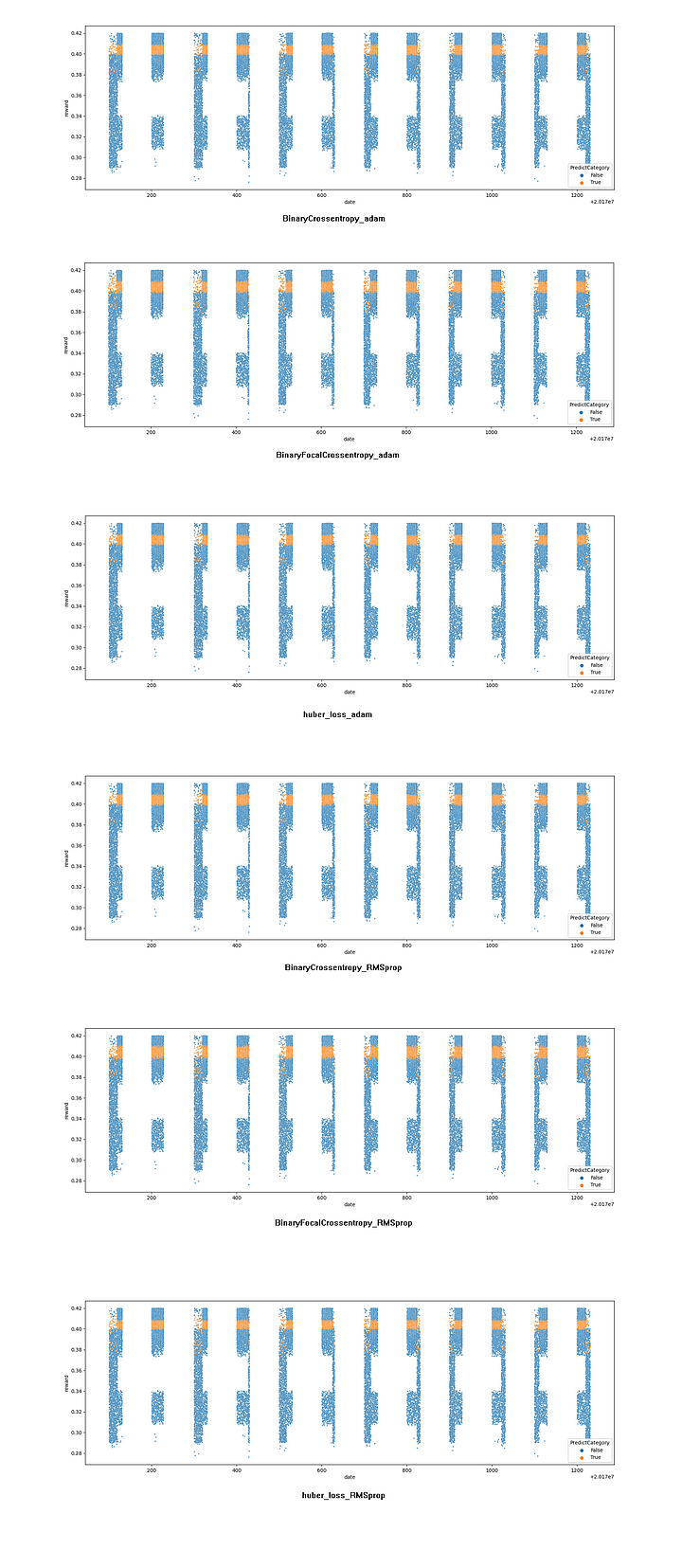
訓練準確率觀察幾乎都在0.99以上,交叉觀察損失值:
透過實例應用與觀察損失函數與optimizer替換時的效果,而其它待交互替換測試的因子如 epoch、batch size、學習率、正規化資料方式、資料訓練分割,與模型建構方式,甚至資料再度經由threshold設定過濾等等,每個步驟階段其實是有很多事情要做,這邊大致是示意應用過程供初步參考。而大致上透過keras運作的內容也於此稍做個小結,之後會是進入到數學概念的章節呼應。

