

於此先了解一下 compiler 的 metrics 在模型fit之後的數量變化。
from tensorflow.keras.models import Sequential
from tensorflow.keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype("float32") / 255
test_images = test_images.reshape((10000, 28 * 28))
test_images = test_images.astype("float32") / 255
from tensorflow.keras import layers
from tensorflow.keras.models import Model
model = Sequential([
layers.Dense(512, activation="relu"),
layers.Dense(10, activation="softmax")
])
model.compile(optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
)
historyTrain = model.fit(train_images, train_labels, epochs=1, batch_size=128 )
完成model.fit後查看 historyTrain.history.keys(),預設只有一個 "loss"
model.compile(optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"]
)
完成model.fit後查看 historyTrain.history.keys(),隨著設定 metrics=["accuracy"], 多了一個觀察指標 "accuracy"
historyTrain = model.fit(train_images, train_labels, epochs=1, batch_size=128, validation_split=0.2 )
完成model.fit後查看 historyTrain.history.keys(),又多出了 "val_loss" 與 "val_accuracy"
從以上三個範例,可以看出如何產生觀察指標。而本節要探討的是,使用callbacks.ModelCheckpoint 求最佳模型。
從上三例最後產生了四個觀察指標後,我們可以使用callbacks.ModelCheckpoint 類別來宣告要使用什麼指標的最佳結果,來保存所訓練的模型。
於是加入callbacks.ModelCheckpoint如下:
from keras import callbacks
Best_ValAcc_Model = callbacks.ModelCheckpoint(filepath="ModelValAacc",monitor="val_accuracy",mode="max")
Best_ValLoss_Model = callbacks.ModelCheckpoint(filepath="ModelValLoss",monitor="val_loss",mode="min")
historyTrain = model.fit(train_images, train_labels, epochs=50, batch_size=128, validation_split=0.2, callbacks = [Best_ValAcc_Model,Best_ValLoss_Model] )
import matplotlib.pyplot as plt
plt.xlabel('epoch', fontsize=12)
plt.ylabel('loss_value', fontsize=12)
plt.plot(historyTrain.history['val_loss'],color='red')
plt.plot(historyTrain.history['loss'],color='blue')
plt.show()
plt.xlabel('epoch', fontsize=12)
plt.ylabel('accuracy_value', fontsize=12)
plt.plot(historyTrain.history['val_accuracy'],color='red')
plt.plot(historyTrain.history['accuracy'],color='blue')
plt.show()
第一個 ModelCheckpoint 設定 monitor="val_accuracy" ,並指定於Best_ValAcc_Model;另一個 ModelCheckpoint 設定monitor="val_loss" ,指定於Best_ValLoss_Model。 接著於模型 fit 函式的 callbacks 將此二個 ModelCheckpoint物件傳入。執行後會於程式目錄產生ModelValAacc與ModelValLoss二個資料夾:
此二資料夾保存了分別以最大值val_accuracy所對應的模型權重 與 最小值val_loss所對應的模型權重。
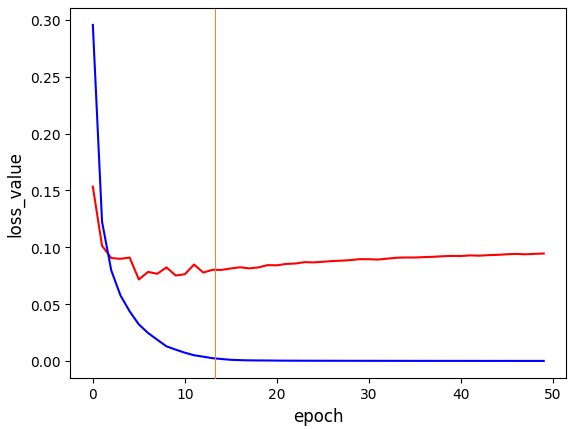
大致上模型訓練至epoch值 10 ~ 20 之間就保留模型所訓練出的最佳權重。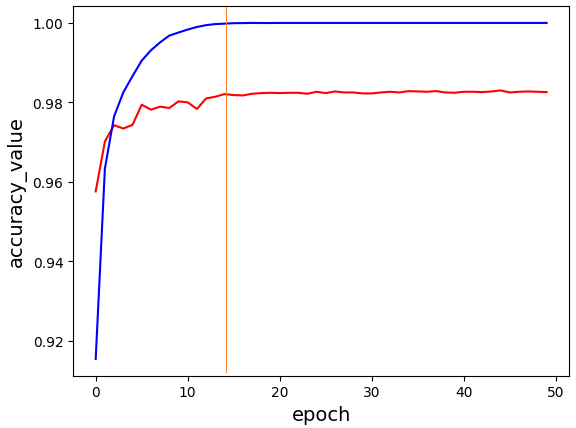
模型重新讀取並執行預測判斷
如何取回最佳模型? 以下範例程式:
model.load_weights("./ModelValAacc")
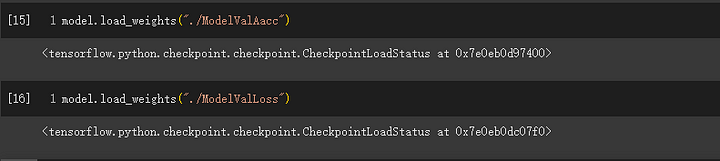
讀取剛剛所存的資料夾,成功後可以繼續執行模型的 perdict。
