Pedro Domingos的演算法分類: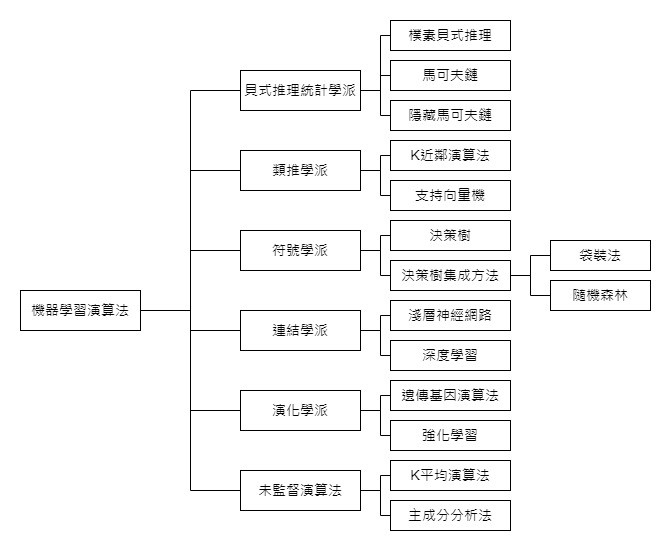
精簡樣本去執行分群:K平均演算法K-Means➞樣本的Clustering
精簡特徵值去執行降低維度:主成分分析法Principle Component Analysis,簡稱PCA➞特徵的Cluster
概念:透過K個集群中心點,不斷更新位置與重新分群的方式,來區分不同集群。
步驟:
➊隨機將樣本分為K群(ex.K=4)
➋隨機選擇2個中心點(a1,b1) (質心)
➌重新計算兩群質心的正確位置(a2,b2)
➍各自移動a1➝a2、b1➝b2
➎重新計算所有樣本與a1,a2距離並同時重新分配樣本到所屬的集群
優點:速度快、易收斂,參數設計只需考慮K值
缺點:比較適和數值型、噪音敏感的問題、質心設立的問題、K值設立的問題
應用:分群(ex.消費者採購行為分群)、推薦系統、異常值偵測
集群Cluster:一種不需人為干涉的非監督學習法,精簡資料的方法,依據其屬性相似性,機器將相似度高的聚集。
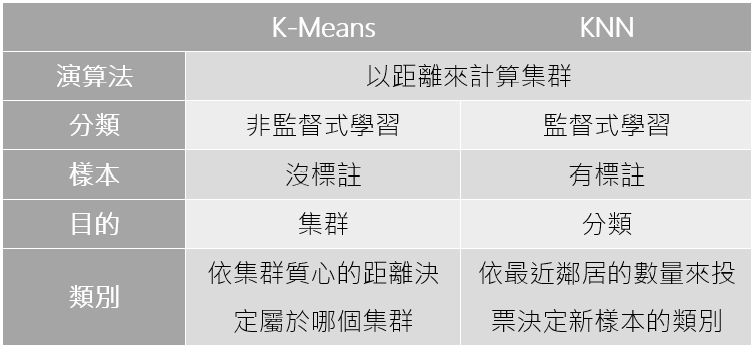
參考來源:人工智慧:概念應用與管理 林東清


 iThome鐵人賽
iThome鐵人賽