在此將分為兩個方面來分析:
①演算法準確度、穩定度的衡量
②依據特性來評估做選擇
模式錯誤的衡量
偏差Bias
- 即模式本身的精度,表示不正確的程度。
- 用於衡量模型擬合訓練資料的能力。
- 越大➜擬合能力越弱(偏移正確值的程度愈大),越小➜擬合能力越強(越接近真實值的程度)
方差Variance
- 即預測值的變化範圍與離散程度,表示不穩定的程度。
- 越大➜分部越分散
一個模型的誤差是兩者之合,常會有Trade off問題,有的模型會一方好一方壞(ex.深度學習)
偏差與方差示意圖:
左下方:Bias很大Variance很小
右上方:Variance很大Bias很小
右下方:兩者都很大
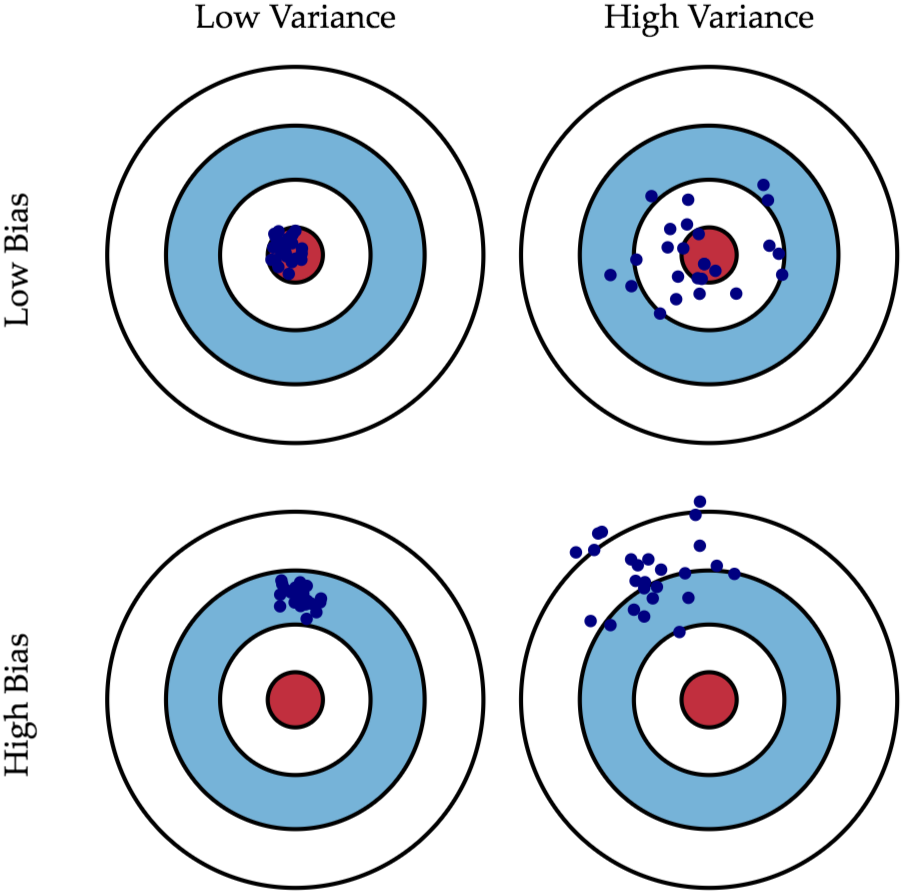
資料來源:https://jason-chen-1992.weebly.com/home/-bias-variance-tradeoff
過度擬合Overfitting
- 特殊模式其只能精確、緊密的匹配訓練的樣本,以至於訓練完後,對於實際真正的樣本無法找到一個通用的法則來預測這些外部的樣本而產生許多預測錯誤,準確度降低的情況。
- 問題在樣本小、太過追求完美,使用上非常複雜,包含許多細節的模式來匹配預測樣本內的特殊特徵。
- 例子:學生死記模擬考題目沒有真正了解本質,碰到非模擬考題目就無法作答情況。
- 原因:
①樣本過少,所需要的特徵又過多
②訓練樣本只為母體中一小部分的特殊樣本,卻被誤認為真正的母體資料跟這些小樣本是一樣的
③誤認為小樣本內的特殊非一般性特徵(又稱噪音)是母體正確的、通用的特徵
- 解決:重新清洗資料、增加訓練樣本數量、採用捨棄法方法、增大正規項係數、使用早停法、增大學習率、增加雜訊資料、剪板
- 這個在機器學習常發生且非常致命的錯誤!
- 預防:
①各種交叉驗證,不斷變換訓練的樣本與測試的樣本
②增加樣本多樣性與數量
③降低模式複雜度
擬合不足Underfitting
- 使用過於簡單模式(ex.僅用傳統線性迴歸)來預測太複雜的非線性真實情況,使模式無法用少數的特徵來分析、辨別具備大量特徵的真實資料,因此訓練完之後預測的錯誤率很高。
- 解決:增加其他特徵項、增加多項式特徵、可以增加模型的複雜程度、減少正規化係數
Bias:模式太簡單(Underfitting)帶來的估計不正確。
Variance:磨世態複雜彈性太大,帶來太大變異數與不穩定(Overfitting)。
參考來源:人工智慧:概念應用與管理 林東清


 iThome鐵人賽
iThome鐵人賽