資料量不足使模型訓練時能夠看到的特徵也很有限,導致訓練成效不佳。
目前的人工智慧還沒有什麼創造力,沒有推理、推論能力,若沒有大量資料,沒經過大量訓練,很難去準確預測新資料的特徵。
模型訓練的資料量越大,預測準確度越好。
在機器學習中,訓練用的數據集中的資料不一定都是符合正確目標、特徵的資料,這些離群資料讓模型去了解預測目標的特點、結構,導致訓練的模型預測準確率下降
因此訓練用的數據集應該經過適當的處理,將離群的資料去除,或是做額外的處理,讓模型能夠順利訓練。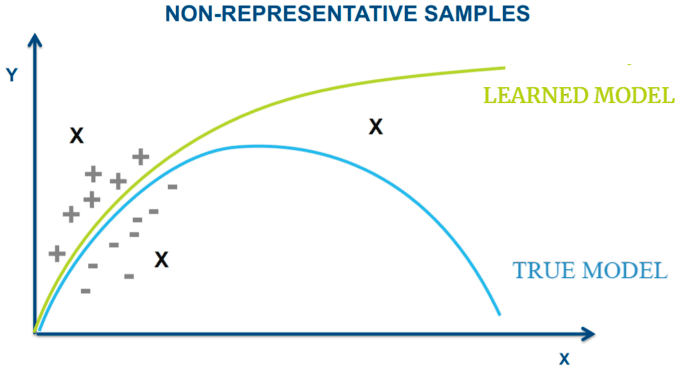
圖片來源: 連結
指的就是低品質的數據,像是有錯誤、雜訊Noise(指資料中不規則,隨機的變化)、屬性有缺失等等。解決方法可以直接去除、將雜訊過濾、修復錯誤,或是填補缺失值等等。
在整個數據集中,會有許多與我們的預測目標無關的特徵,過多的無用特徵會對模型的訓練產生負面影響, 解決的方法有特徵選擇(Feature Selection)和特徵工程(Feature Engineering),比如說前面幾篇的文章中有提到的降維方法。


 iThome鐵人賽
iThome鐵人賽