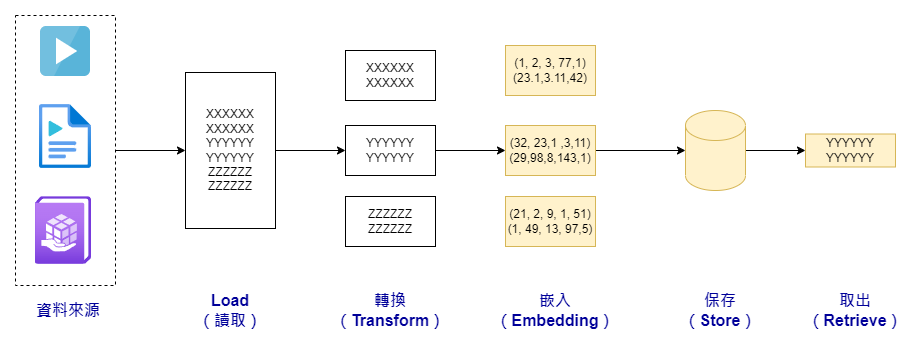
在這篇文章中,我們將延續前一天的主題,探討 RAG(Retrieval Augmented Generation,檢索增強生成)的概念。我們先回顧一下,前一天我們已經學習了如何使用 LangChain 的 Loader 來讀取外部資料。我們也簡單介紹了 TextSplitter 的幾個重要功能,並初步嘗試了資料轉換的基本步驟。今天,我們將進一步探討如何進行文本嵌入。
文本嵌入是一種讓電腦更「聰明」地理解文字的方法。簡單來說,它就是把文字或詞彙轉換成一串數字,這樣電腦就能更輕鬆地處理它們。
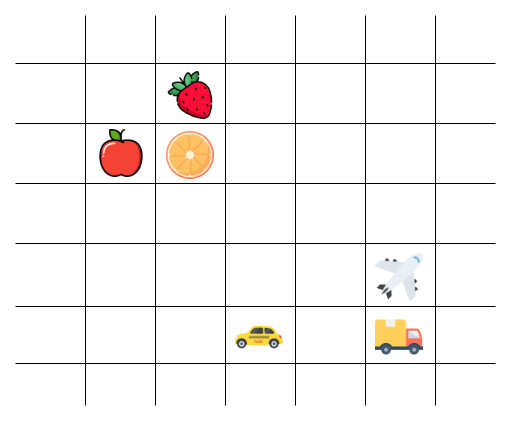
讓我們用一個簡單的例子來解釋。假設我們有蘋果、橘子、草莓、汽車、貨車和飛機這六個概念。在文本嵌入的世界裡,這些詞會被轉換成一串數字(也就是數字向量),然後被放在一個虛擬的「空間」裡。
在這個虛擬空間中,有幾個有趣的現象:
在 LangChain 框架中,提供了多種文本嵌入的選項,包括 OpenAI、Cohere 和 Hugging Face 等。今天,我們將使用 OpenAI 的嵌入模型作為示範,讓大家更快地掌握文本嵌入的基本概念和技巧。
首先,讓我們看一個簡單的文本嵌入運算範例:
from langchain.embeddings import OpenAIEmbeddings
# 建立模型案例
embeddings_model = OpenAIEmbeddings()
# 執行文本嵌入運算
embeddings = embeddings_model.embed_documents(
['我週末喜歡吃炸雞',
'壽司是我的最愛之一',
'義大利麵很適合約會',
'電玩比賽吸引了眾多觀眾',
'電腦遊戲是我的娛樂方式',
'任天堂出品了經典遊戲']
)
# 輸出結果
len(embeddings), len(embeddings[0])
--- 輸出結果 ---
(6, 1536)
這個範例使用了 embed_documents 方法來對一批文本進行嵌入運算。每個嵌入向量都有 1536 個維度,這些維度共同捕捉了文本的語義訊息。
除了 embed_documents,LangChain 還提供了 embed_query 方法,專門用於查詢嵌入:
embedded_query = embeddings_model.embed_query("有什麼適合約會吃的?")
embedded_query[:5]
--- 實際輸出 ---
[0.01010190811893419,
-0.022349237047134797,
0.012181518879596755,
-0.01181297962718288,
-0.00992421921819086]
LangChain 還提供了嵌入快取功能,稱為 CacheBackedEmbeddings。這個功能有兩大優點:提高速度和節省成本。你可以選擇短期(使用記憶體)或長期(使用檔案)的儲存方式。
使用記憶體作為快取媒介是最簡單和最快的方式,但請注意,這種方式的數據只會在當前的執行階段中存在。一旦程式結束,數據就會消失。
from langchain.storage import InMemoryStore
from langchain.embeddings import CacheBackedEmbeddings
# 記憶體儲存庫
mem_store = InMemoryStore()
# 建立使用快取機制的嵌入器
cached_embedder_memory = CacheBackedEmbeddings.from_bytes_store(
embeddings_model, mem_store, namespace=embeddings_model.model
)
embeddings_memory = cached_embedder_memory.embed_documents(['我週末喜歡吃炸雞',
'壽司是我的最愛之一',
'義大利麵很適合約會',
'電玩比賽吸引了眾多觀眾',
'電腦遊戲是我的娛樂方式',
'任天堂出品了經典遊戲'])
如果你希望長期儲存嵌入數據,可以使用檔案作為儲存媒介,而使用檔案快取的方式,只要我們使用 LocalFileStore 來建立檔案儲存體後,傳入 CacheBackedEmbeddings 內即可:
from langchain.storage import LocalFileStore
from langchain.embeddings import OpenAIEmbeddings, CacheBackedEmbeddings
fs = LocalFileStore("./cache/")
cached_embedder_file = CacheBackedEmbeddings.from_bytes_store(
embeddings_model, fs, namespace=embeddings_model.model
)
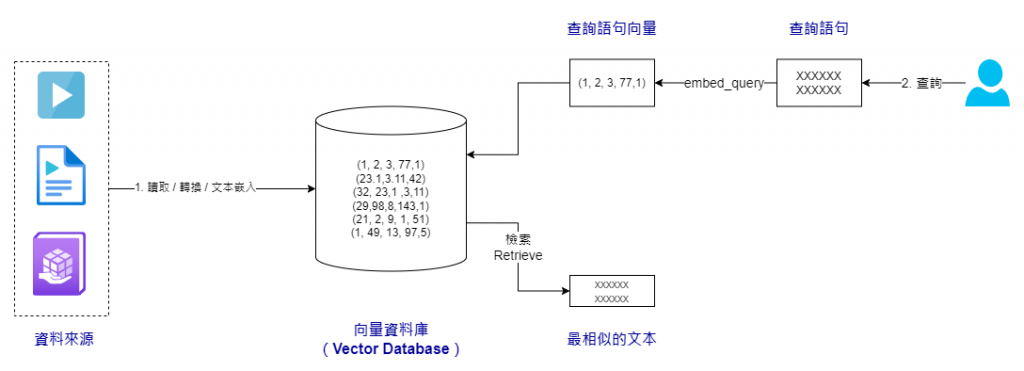
另一種常用的儲存非結構化資料的方法是先對其進行嵌入運算,然後將嵌入後的結果保存到向量資料庫中。通過向量資料庫的強大功能,我們不僅能夠對這些嵌入資料進行長期保存,還可以利用資料庫的原生查詢功能來找出與我們的查詢語句最為相似的嵌入向量。
LangChain 支持多種向量資料庫,包括 Chroma、FAISS 和 Lance 等。今天,我們將使用 Chroma 作為示範。
在今天的示範中,我們將展示一個實際應用場景。假設我們已經預先準備了六篇文本作為背景資料庫。我們會使用 Chroma 的 from_texts 方法來對這些文本進行嵌入運算,並建立一個向量資料庫。接著,我們會模擬一個使用者問題,比如說「有什麼適合約會吃的?」。然後,我們會使用 similarity_search 方法來檢索與該問題最相似的文本,最後再使用語言模型來生成我們的回覆。
檢索與搜尋的程式碼如下:
from langchain.vectorstores import Chroma
# 嵌入運算以及建立檢索
db = Chroma.from_texts(['我週末喜歡吃炸雞',
'壽司是我的最愛之一',
'義大利麵很適合約會',
'電玩比賽吸引了眾多觀眾',
'電腦遊戲是我的娛樂方式',
'任天堂出品了經典遊戲'], OpenAIEmbeddings())
# 搜尋
query = "有什麼適合約會吃的?"
docs_searched = db.similarity_search(query)
print(docs_searched)
--- 以下是搜尋到的文本內容 ---
[Document(page_content='義大利麵很適合約會', metadata={}), Document(page_content='義大利麵很適合約會', metadata={}), Document(page_content='壽司是我的最愛之一', metadata={}), Document(page_content='壽司是我的最愛之一', metadata={})]
接下來,我們會設計一個生成回應的提示模板:
from langchain.prompts import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
template="""你是一個使用者的助理,請依照他個人的喜好回答他的問題。
個人喜好: {background_context}
"""
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
human_template = "{user_question}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
最後,我們將展示如何使用這個簡單的檢索增強生成(RAG)框架來生成回應:
user_question = "有什麼適合約會吃的?"
docs_searched = db.similarity_search(user_question)
response = chat_model(chat_prompt.format_messages(background_context=docs_searched, user_question=user_question))
print(response)
綜合考慮我們的背景資料和使用者問題,生成的回應可能會是這樣:
content='根據你的個人喜好,我建議你可以選擇義大利麵或壽司作為約會的餐點。這兩種食物都很受歡迎,而且有著浪漫的氛圍。你可以選擇一家氛圍舒適的義大利麵餐廳或壽司店,享受美食和愉快的時光。祝你約會愉快!' additional_kwargs={} example=False
這個示範雖然簡單,但它展示了如何將語言模型與外部資料和環境整合在一起。這是一個非常實用的技巧,你可以思考如何將它應用到你的日常工作中。
實際的程式碼可以在這裡找到:D21. LangChain 專案實做 - 文本嵌入與向量資料庫.ipynb。一旦你對如何改進你的工作流程有了一些想法,不妨來這裡進行實驗。

