在前幾篇文章中,我們已經和大家分享了如何讀取和轉換資料,以及如何進行文本嵌入。今天,我們將進一步探討如何利用 LangChain 快速建立自己的問答機器人。
在我們動手實作問答機器人之前,讓我們先來了解一下 LangChain 的一個重要組件:Retriever。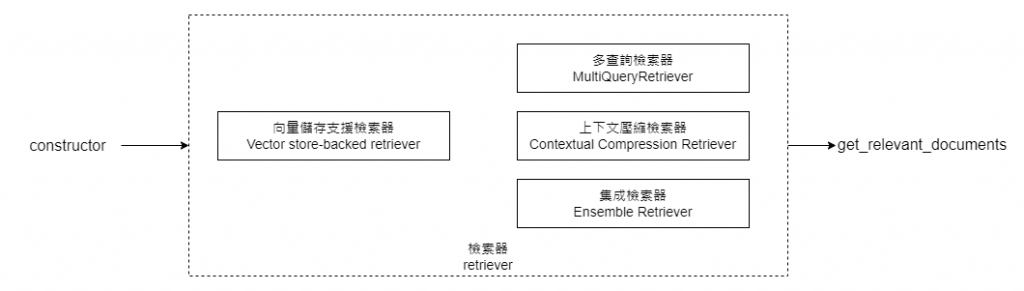
我們之前已經介紹過,LangChain 提供了一個向量資料庫,用於進行向量相似度的搜索。除了這個 "vector store",LangChain 還提供了一個更加通用的檢索類別,稱為 "Retriever"。這個檢索類別不需要儲存文本,其核心功能是 get_relevant_documents,以及它的非同步版本 aget_relevant_documents。
通過上面的 Retriever 示意圖圖,我們可以預見 LangChain 支持的多種 Retriever 類型,例如 MultiQueryRetriever 和 Ensemble Retriever 等。這些 Retriever 的目的和功能將在下一篇文章中詳細解釋。
至於今天,我們則將重點放在理解 Retriever 的基本概念,以及如何使用 LangChain 提供的一個封裝好的檢索工具—VectorstoreIndexCreator—來實作您的第一個問答機器人。
在實際應用中,我們經常需要根據自己公司或產品的特定資料,為使用者提供一個聊天機器人作為問答工具。今天,我們將模擬這種情境,並使用 YouTube 字幕以及 SRTLoader 文件讀取器來簡化資料準備過程。
首先,我們需要使用 LangChain 提供的資料讀取器來取得影片的字幕內容。以下是相關的 Python 程式碼:
from langchain.document_loaders import SRTLoader
# 取得影片內容
loader = SRTLoader(
'/content/ironman2023/srt_files/晴美公寓酒店 Jolley Hotel,有家的溫馨感,地點極好,走下來就是美食一大堆~帶爹娘到台北住一晚!【黛西開房間 Vlog #7】 - YouTube - Chinese (Taiwan).srt'
)
接下來,您會發現,使用 LangChain 框架來建立一個基礎的問答機器人實際上非常直觀和簡單。只需一行程式碼,如下:
from langchain.indexes import VectorstoreIndexCreator
index = VectorstoreIndexCreator().from_loaders([loader])
然後,我們可以進行一些實驗,看看這個問答機器人的回答效果:
query = "這影片是在說什麼?"
index.query(query)
--- 回覆結果 ---
'這影片是在介紹台北晴美公寓酒店的兩房一廳單人房房間,以及附近的美食小吃和腳底按摩店。'
再試一個問題:
query = "他介紹了哪些美食?"
index.query(query)
--- 回覆結果 ---
'他介紹了臭豆腐、滷味、鹹酥雞和原味的鹹酥雞。'
最後一個問題:
query = "有提到哪間腳底按摩店嗎?"
index.query(query)
--- 回覆結果 ---
'沒有提到哪間腳底按摩店。'
綜觀以上的程式碼和問答實例,您可能會覺得驚訝:就這麼簡單?確實,使用 LangChain 框架,您只需幾行程式碼就能建立一個功能完善的問答機器人。但更值得一提的是,以上的展示中是因為LangChain 幫我們封裝了許多複雜的細節和底層原理,在接下來的部分,我們將深入探討它內部是如何封裝以及我們如何客制這些封裝內容。
要完整實作一個前文所示的問答機器人,其實大部分所需的細節和必要知識已經在先前的文章中進行了詳盡的介紹。現在,我們來整理一下,以便更清晰地了解如何將這些元素組合在一起。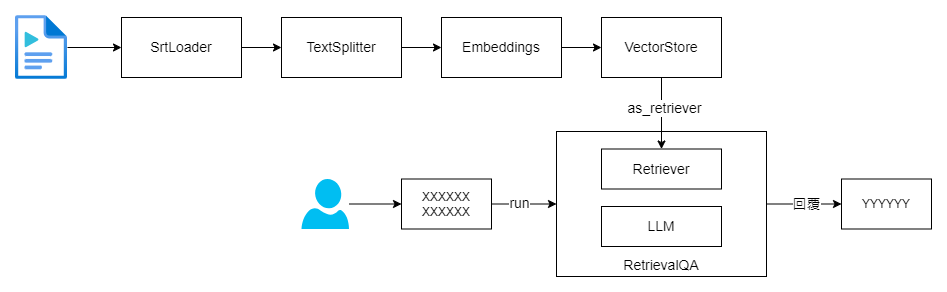
首先,我們需要準備背景資料。文檔讀取器(Document Loader)的部分已經在前面章節中說明。有了這個讀取器,接下來我們需要一個文本分割器,也就是 TextSplitter。
docs = loader.load()
print(f'docs: {docs}')
from langchain.text_splitter import RecursiveCharacterTextSplitter
recursive_text_splitter = RecursiveCharacterTextSplitter(
# separator調整為空白優先,這樣我們的 overlap 才會正常運作
separators=[" ", "\n"],
chunk_size = 300,
chunk_overlap = 30,
length_function = len,
)
recursive_splitted_texts = recursive_text_splitter.create_documents([docs[0].page_content])
print(f'len of recursive_splitted_texts: {len(recursive_splitted_texts)}')
for (idx, t) in enumerate(recursive_splitted_texts[:3]):
print(f'Doc {idx} - text len: {len(t.page_content)}, page_content: {t.page_content}')
這個文本分割器讓我們能更有效地控制文本大小,以符合語言模型的處理能力。
接著,我們需要準備文本嵌入模型和向量資料庫。這次,我們將使用向量資料庫的 as_retriever 方法來獲得通用的檢索器界面。
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
# 文本嵌入模型
embeddings = OpenAIEmbeddings()
# 建立向量資料庫
db = Chroma.from_documents(recursive_splitted_texts, embeddings)
# 取得以向量資料庫的搜尋演算法為主的檢索器
retriever = db.as_retriever()
最後,我們使用 LangChain 的 RetrievalQA 來自動生成用戶問題的回答。
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=retriever)
query = "這影片是在說什麼?"
qa.run(query)
--- 以下是實際的回應結果 ---
這影片講述黛西入住台北晴美公寓酒店的經驗,特別提到酒店裡的生活機能良好,附近的晴光夜市有很多美食小吃,以及腳底按摩店,非常適合帶長輩一起去按摩消除疲勞。
您可能也注意到,我們在建立 RetrievalQA 時指定了 chain_type 參數。這個參數有其特殊的意義,但由於本文主要目的是讓大家可以快速看到檢索器(Retriever)的使用方式,我們將在後續文章中詳細解釋。
有了以上的所有組件,我們可以更深入地了解 LangChain 如何以單行程式碼實現問答機器人。
customized_index_creator = VectorstoreIndexCreator(
vectorstore_cls=Chroma,
embedding=embeddings,
text_splitter=recursive_text_splitter
)
customized_index = customized_index_creator.from_loaders([loader])
這個客製化的問答機器人會有以下的回應:
query = "這影片是在說什麼?"
customized_index.query(query)
--- 以下是實際輸出結果 ---
這影片是在介紹台北晴美公寓酒店的單人房房間,以及附近的美食小吃和腳底按摩店。
完整的程式碼可在這裡找到:D22. LangChain 專案實做 - 問答機器人.ipynb
希望大家喜歡本文的內容!就像我第一次接觸這些知識時一樣,您也會對其簡單而強大的特性感到驚訝。而當您深入了解後,會發現它背後有更多深遠的涵義。

