之前有介紹過,在nn.Linear線性層中,輸入的圖片會攤平成 1D 的向量,並與權重進行矩陣相乘,模型輸出張量的值代表:針對該輸入圖片,求出所有像素的加權總合。
在便是物體的任務中,位置鄰近的像素可能較有關聯,較遠的像素則相對關聯較少,以下圖兔子為例,與兔子距離較遠像素(可能是小草或背景),與兔子的關聯性較低,因此我們可以拋棄處理圖片中所有像素的做法,指求像素與其隔壁鄰居加權的總和。

因此就有了卷積(convolution)的作法,如果要理解細節很推薦看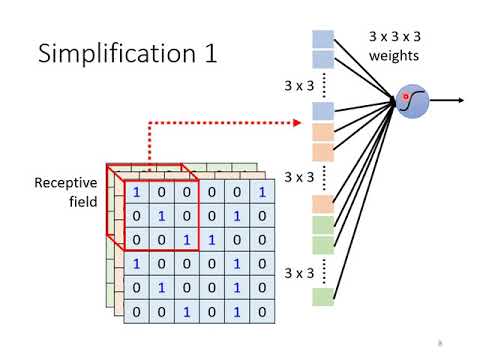
大致上的流程是會用一個卷積核,不斷的滑動去算出每個區域的值,如下圖:
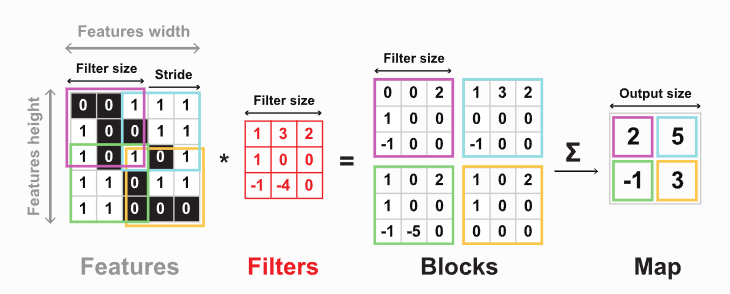
使用卷積會有以下好處
特徵提取:卷積操作能夠自動從輸入數據中提取特徵。通過卷積核(也稱為濾波器)的運算,神經網絡能夠識別圖像、聲音和文本等各種類型的特徵,從而使模型能夠學習到有用的表示形式。
參數共享:卷積操作使用相同的卷積核在不同位置進行運算,這意味著模型需要學習的參數數量較少。這種共享參數的特性有助於減少過擬合風險,提高模型的泛化能力。
空間不變性:卷積操作具有空間不變性,這意味著模型能夠識別物體或特徵的位置不變性。這對於處理圖像或其他具有平移不變性的數據非常有用,因為物體在圖像中的位置可能會變化,但仍然應該能夠識別它們。
局部感知:卷積核僅關注輸入數據的局部區域,這有助於模型更好地捕捉局部特徵。這對於識別圖像中的細微細節或文本中的局部語義非常重要。
運算效率:卷積操作可以通過高度優化的庫和硬件加速來實現,因此在實際應用中具有良好的運算效率。這使得卷積神經網絡能夠處理大規模數據集和實時應用。
torch.nn模組提供了 1D、2D、3D 卷積的函數,分別為:
nn.Conv1d:用於時序相關的資料。
nn.Conv2d:用於圖片。
nn.Conv3d:用於3D圖或是影片。
因此我們選擇了nn.Conv2d來分類貓與兔子的圖片,透過以下程式碼更容易理解作法,首先我們先引入要使用到的模組
import torch
import torch.nn as nn
from torchvision import datasets, transforms
建立資料集後取出第一張圖片,細節可以參考 Day 11 建立貓貓和兔兔的資料集
train_path = './cat-vs-rabbit/train-cat-rabbit'
# 正規化是機器學習常用的資料前處理,將資料範圍變成[0,1]之間
normalize=transforms.Normalize(mean=[.5,.5,.5],std=[.5,.5,.5])
transform=transforms.Compose([
transforms.RandomCrop(224), # 隨機裁減
transforms.RandomHorizontalFlip(), # 圖像水平翻轉
transforms.ToTensor(), # 轉成 tensor 格式
normalize
])
train_dataset = datasets.ImageFolder(train_path, transform = transform)
img, label = train_dataset[0]
使用nn.Conv2d來建立卷積層(官方連結),由於我們是 RGB 圖片,in_channels=3,out_channel可以自己設定,此處設為16,kernel_size 表示卷積核的大小,stride代表一次要走多像素,這邊設定 (1, 1) 表示每次向右邊平移一個像素,走到底之後往下移動一個像素,再從最左邊開始走。


# nn.Conv2d 能接受的輸入的 shape 為 BxCxHxW,B 代表批次大小
# 我們只讀取一張圖片,所以加入批次軸
conv = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=(1, 1))
output = conv(img.unsqueeze(0))
print(img.unsqueeze(0).shape, output.shape)
因為我們是以 kernel 中心點滑動每一個像素,Pytorch 在移動卷積核不會超過圖片的大小,因此垂直和水平會少算一個位置,導致輸出的圖片會變小。

如果要讓輸入與輸出保持一樣大小,可以將 padding 設定成 (1, 1),這樣 Pytorch 會幫我們在圖片邊邊補上數值 0,範例如下圖:
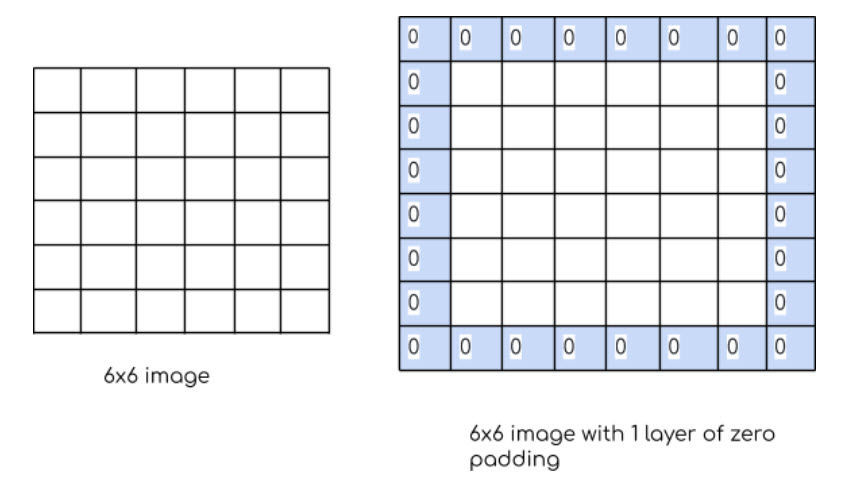
conv = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=(1, 1), padding=1)
output = conv(img.unsqueeze(0))
print(img.unsqueeze(0).shape, output.shape)
可以看到輸入和輸出同樣大小了:

今天介紹卷積是如何運作,透過卷積的特徵提取、參數共享、空間不變性、局部感知、運算效率來更有效率的處理圖片問題,明天會介紹通常放在卷積後面的架構,pooling (池化)。

