在我們的上一篇文章中,我們提到了Langchain不僅提供了向量資料庫的語義相似度查詢功能,還為我們設計了一個通用的檢索器界面。這可能讓你產生一個疑問:既然已經有了語義相似度查詢,為何還需要一個專門的通用檢索器界面?
這個設計實際上是為了提供更多的靈活性和適應性。語義相似度查詢雖然強大,但它可能不適用於所有情境。通過提供一個通用的檢索器界面,我們可以根據不同的需求和應用場景,選擇更適合的檢索方法。這樣不僅能讓我們更有效地找到所需的資訊,也能更全面地利用Langchain的功能。
又,為何語義相似度搜尋可能不夠呢?我們可以這樣來理解:語義嵌入(Semantic Embedding)是一種將文字或段落中豐富的意義壓縮到有限維度空間的技術。這樣做的目的是為了更容易地找到與查詢問題相似或相關的答案。然而,這種壓縮過程往往會導致一些原始資訊的損失,尤其是當原始文本非常龐大時。
那麼,如何在這些已經有一定程度的資訊損失的資料中,找到最合適、最有用的資料呢?這就是我們為什麼要設計一個通用的檢索器界面的原因。通過這個界面,我們可以根據不同的應用場景,選擇最適合我們需求的檢索方法。
接下來,我們將介紹一些比較基礎,但同時也非常實用的預設檢索類別。

在文本搜尋的世界裡,向量資料庫檢索器可以說是一個基礎但非常實用的工具。它主要利用我們選定的向量資料庫來進行預設的相似度搜尋。在使用 as_retriever 函數之前,我們需要先建立一個實際的向量資料庫(vector store)實例。以下是一個簡單的示範:
from langchain.document_loaders import SRTLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
# 取得影片內容
loader = SRTLoader(
'/content/ironman2023/srt_files/晴美公寓酒店 Jolley Hotel,有家的溫馨感,地點極好,走下來就是美食一大堆~帶爹娘到台北住一晚!【黛西開房間 Vlog #7】 - YouTube - Chinese (Taiwan).srt'
)
docs = loader.load()
# 建立 TextSplitter
recursive_text_splitter = RecursiveCharacterTextSplitter(
# separator調整為空白優先,這樣我們的 overlap 才會正常運作
separators=[" ", "\n"],
chunk_size = 100,
chunk_overlap = 0,
length_function = len,
)
recursive_splitted_texts = recursive_text_splitter.create_documents([docs[0].page_content])
# 建立簡單的 vector db
embedding = OpenAIEmbeddings()
vectordb = Chroma.from_documents(documents=recursive_splitted_texts, embedding=embedding)
一旦我們有了向量資料庫的實例,就可以使用 as_retriever 函數來獲得該資料庫的內建相似度搜尋檢索器:
retriever_vector = vectordb.as_retriever()
docs_vector_store = retriever_vector.get_relevant_documents("這影片介紹了哪些美食?")
pretty_print_docs(docs_vector_store)
--- 以下是檢索取得的文件內容 ---
Document 1:
中式西式都有 不過種類不多 但我覺得最驚艷的啊 是有現榨的柳橙汁 還有現榨的蔬果汁 非常新鮮 好喝 因為地點關係 生活機能非常好 晴光夜市裡面超多美食小吃的 而且都很便宜、銅板價 臭豆腐、滷味
----------------------------------------------------------------------------------------------------
Document 2:
那這次介紹就到這邊 我們下次見,拜拜!
----------------------------------------------------------------------------------------------------
Document 3:
所以只好拿出平板來"治治"他一下 穿越過舒服的客廳 有一區工作區,還有一區是小廚房區 這邊有電熱水壺 洗手台 茶包、咖啡、餅乾、洋芋片 電磁爐跟微波爐 鍋碗瓢盆也都有 那就來看看冰箱裏面有什麼
----------------------------------------------------------------------------------------------------
Document 4:
按著、按著都覺得好消除疲勞啊 今天在晴美公寓酒店住了三天兩夜 因為都在陪家人 所以沒有太多時間來錄影 那更詳細的資訊 我都已經寫在部落格文章中了 有興趣的可以點到下方資訊參考哦 圓山大飯店
除了基本的相似度搜尋功能,Chroma 還提供了一個更先進的搜尋演算法:最大邊際相關檢索(Maximum Marginal Relevance Retrieval,簡稱 MMR)。那麼,MMR 到底是什麼,我們為什麼需要它?
我們假設一個情境,當你在網上搜尋某個產品的評價。你可能會發現,搜尋結果有時候可能設計的太多過於完美,大多都是類似的評價,比如「好產品」或「很好的產品」。然而,這樣的結果其實嚴格說來也有部分瑕疵,因為它並沒有提供任何不同角度或新的資訊。而這就是 MMR 在試著解決的地方:它能讓你獲得更多樣化,但仍然相關的資訊。
MMR 的運作方式相當獨特。首先,它會像一般的搜尋引擎那樣,找出一系列與你的搜尋詞相關的結果。然後,MMR 會對這些結果進行重新評估,並挑選出既相關又多樣化的項目。舉例來說,它可能會選出「好產品」和「安裝簡單」,而不是兩次都選「好產品」。
簡而言之,MMR 就像一個更加智慧的多樣性選擇器。它不僅會找出最相關的資訊,還會確保這些資訊具有多樣性。這樣你就能從多個角度了解一個主題,而不是僅僅看到重複或相似的資訊。
使用 MMR,你最終會得到一個更全面、更有用的搜尋結果列表。這就是我們需要 MMR 的原因。
如果你使用 LangChain,你可以很容易地在 Chroma DB 中使用 MMR。以下是相關的程式碼:
retriever_mmr = vectordb.as_retriever(search_type="mmr")
docs_mmr = retriever_mmr.get_relevant_documents("這影片介紹了哪些美食?")
pretty_print_docs(docs_mmr)
--- 以下是檢索出來的文件內容 ---
Document 1:
中式西式都有 不過種類不多 但我覺得最驚艷的啊 是有現榨的柳橙汁 還有現榨的蔬果汁 非常新鮮 好喝 因為地點關係 生活機能非常好 晴光夜市裡面超多美食小吃的 而且都很便宜、銅板價 臭豆腐、滷味
----------------------------------------------------------------------------------------------------
Document 2:
那這次介紹就到這邊 我們下次見,拜拜!
----------------------------------------------------------------------------------------------------
Document 3:
所以只好拿出平板來"治治"他一下 穿越過舒服的客廳 有一區工作區,還有一區是小廚房區 這邊有電熱水壺 洗手台 茶包、咖啡、餅乾、洋芋片 電磁爐跟微波爐 鍋碗瓢盆也都有 那就來看看冰箱裏面有什麼
----------------------------------------------------------------------------------------------------
Document 4:
按著、按著都覺得好消除疲勞啊 今天在晴美公寓酒店住了三天兩夜 因為都在陪家人 所以沒有太多時間來錄影 那更詳細的資訊 我都已經寫在部落格文章中了 有興趣的可以點到下方資訊參考哦 圓山大飯店
這樣的檢索結果不僅多樣化,還非常相關,能讓你更全面地了解主題。這就是 MMR 的功能所在。希望這樣的說明與示範能幫助你更好地理解和使用 MMR 檢索!

除了先前介紹過的 MMR 演算法,LangChain 還有另一個強大的檢索器,名為「多查詢檢索器」(MultiQueryRetriever)。這個檢索器的主要特點是,它能透過語言模型生成多個與原查詢相似的問題,從而更全面地找出相關的答案。
簡單來說,多查詢檢索器會先用一個語言模型(llm)生成多個與原查詢相似的問題。然後,這些新生成的問題會被用來進行檢索,以便找出更多相關的答案。這樣的機制讓我們能更全面地了解某一主題。
首先,我們需要準備一個語言模型(llm)和一個基礎檢索器。以下是相關的程式碼:
from langchain.chat_models import ChatOpenAI
from langchain.retrievers.multi_query import MultiQueryRetriever
question = "這影片介紹了哪些美食?"
llm = ChatOpenAI(temperature=0)
retriever_multi_query = MultiQueryRetriever.from_llm(
retriever=vectordb.as_retriever(), llm=llm
)
接著,我們可以開啟檢索器的日誌功能,以便更詳細地了解其運作機制:
# Set logging for the queries
import logging
logging.basicConfig()
logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO)
docs_multi_query = retriever_multi_query.get_relevant_documents(query=question)
pretty_print_docs(docs_multi_query)
您可以看到,透過語言模型,我們生成了多個相似的查詢問題:
INFO:langchain.retrievers.multi_query:Generated queries: ['這部影片有哪些美食介紹?', '這個影片裡有哪些美食被介紹到?', '這部影片中有哪些美食被提及?']
然後,MultiQueryRetriever 會根據這些問題找出相關的答案。這樣,我們就能得到一個更全面和多樣的搜尋結果。
Document 1:
中式西式都有 不過種類不多 但我覺得最驚艷的啊 是有現榨的柳橙汁 還有現榨的蔬果汁 非常新鮮 好喝 因為地點關係 生活機能非常好 晴光夜市裡面超多美食小吃的 而且都很便宜、銅板價 臭豆腐、滷味
----------------------------------------------------------------------------------------------------
Document 2:
那這次介紹就到這邊 我們下次見,拜拜!
----------------------------------------------------------------------------------------------------
Document 3:
按著、按著都覺得好消除疲勞啊 今天在晴美公寓酒店住了三天兩夜 因為都在陪家人 所以沒有太多時間來錄影 那更詳細的資訊 我都已經寫在部落格文章中了 有興趣的可以點到下方資訊參考哦 圓山大飯店
----------------------------------------------------------------------------------------------------
Document 4:
所以只好拿出平板來"治治"他一下 穿越過舒服的客廳 有一區工作區,還有一區是小廚房區 這邊有電熱水壺 洗手台 茶包、咖啡、餅乾、洋芋片 電磁爐跟微波爐 鍋碗瓢盆也都有 那就來看看冰箱裏面有什麼
----------------------------------------------------------------------------------------------------
Document 5:
鹹酥雞通通都有 皮薄餡多 一顆15元,還OK 一個25塊 原味的最好吃 買回來給侄子吃 他一直拿在手上都不想放掉了 雖然很貴,但是很好吃 附近還有很多腳底按摩店 非常適合帶長輩一起去按摩
多查詢檢索器不僅能讓我們得到更多相關的答案,還能從不同的角度了解一個主題。這樣的功能讓它成為一個非常實用和強大的檢索工具。如果你也想讓你的搜尋結果更全面和多樣,那麼多查詢檢索器絕對值得一試。

當我們在搜尋資訊的時候,有時會發現真正需要的答案僅僅是一個龐大文本中的一小部分。這時,上下文壓縮檢索器(Contextual Compression Retriever)就派上了用場。這個檢索器是專門為了解決這種問題而設計的,它運用一種特殊的「壓縮機制」來將搜尋到的文本縮減,只留下最核心的答案。
這個壓縮機制的其中一種實做原理是透過語言模型來實現。舉例來說,語言模型會先參考用戶的問題和搜尋到的答案,然後對這些資訊進行簡化或摘要。這樣一來,不僅能更精確地捕捉到問題的核心,還能只提供最相關的資訊。
這個方法有兩大優點。首先,它能節省後續語言模型需要處理的數據量(也就是所謂的token數),這對於資源有限的情況非常有用。其次,它能提高搜尋結果的精確度,讓你不必浪費時間過濾一堆不太相關的資訊。
至於如何使用上下文壓縮檢索器,你需要做的是提供一個基礎的檢索器和一個壓縮器。具體的程式碼實現也相對簡單,只需幾行程式碼即可完成設定,如下:
from langchain.llms import OpenAI
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
llm = OpenAI(temperature=0)
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(base_compressor=compressor, base_retriever=retriever_vector)
compressed_docs = compression_retriever.get_relevant_documents("這影片介紹了哪些美食?")
pretty_print_docs(compressed_docs)
你會發現,經過壓縮後的文本會更為精簡,只包含最核心的答案。例如:
Document 1:
中式西式都有 不過種類不多 有現榨的柳橙汁 還有現榨的蔬果汁 臭豆腐、滷味
----------------------------------------------------------------------------------------------------
Document 2:
"餅乾、洋芋片"
綜合以上,上下文壓縮檢索器不僅解決了資訊過多的問題,還通過語言模型的壓縮原理,使得搜尋結果更為精確和高效。這樣的工具無疑是資訊檢索領域中一個值得關注的創新。
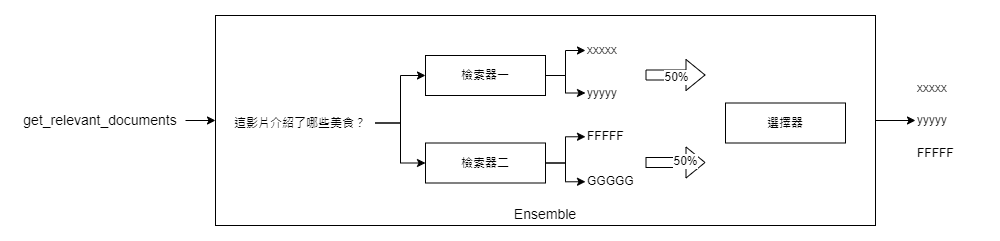
在資訊檢索的世界裡,有時候一種檢索器(Retriever)並不能滿足我們多樣化的需求。這時,集成檢索器(Ensemble Retriever)就派上用場了。它的主要作用是整合多種不同的檢索演算法,以提供更全面和精確的搜尋結果。
想像一下,如果你手上有兩種強大但各有特長的檢索演算法,你會怎麼做?一個常見的解決方案就是使用「混合搜尋」,也就是將稀疏檢索器(例如 BM25)和密集檢索器(例如嵌入相似性)組合在一起。這兩種檢索器各有所長:BM25 擅長根據關鍵字找到相關文件,而密集檢索器則擅長根據語義相似性進行搜尋。因此,將這兩者結合通常會產生更全面和精確的搜尋結果。
實際操作也相當簡單。首先,你需要初始化你選擇的檢索器,例如 BM25 和某種密集檢索器(在本例中是 Chroma)。然後,你可以使用這些檢索器作為參數,並指定它們各自的權重,來初始化一個集成檢索器。以下是相關的程式碼:
# 初始化 BMW5 檢索器以及 chromar retriever
bm25_retriever = BM25Retriever.from_documents(recursive_splitted_texts)
bm25_retriever.k = 2
chroma_retriever = vectordb.as_retriever(search_kwargs={"k": 2})
# 初始化集成檢索器
ensemble_retriever = EnsembleRetriever(retrievers=[bm25_retriever, chroma_retriever], weights=[0.5, 0.5])
我們可以各自比較一下,使用的兩個檢索器以及集成檢索器的檢索結果,首先是 bm25 檢索器的結果:
bm25_retriever.get_relevant_documents("這影片介紹了哪些美食?")
--- 以下是輸出內容 ---
[Document(page_content='那這次介紹就到這邊 我們下次見,拜拜!', metadata={}),
Document(page_content='按著、按著都覺得好消除疲勞啊 今天在晴美公寓酒店住了三天兩夜 因為都在陪家人 所以沒有太多時間來錄影 那更詳細的資訊 我都已經寫在部落格文章中了 有興趣的可以點到下方資訊參考哦 圓山大飯店', metadata={})]
接下來是 chroma 檢索器的部分:
chroma_retriever.get_relevant_documents("這影片介紹了哪些美食?")
--- 以下是輸出內容 ---
[Document(page_content='中式西式都有 不過種類不多 但我覺得最驚艷的啊 是有現榨的柳橙汁 還有現榨的蔬果汁 非常新鮮 好喝 因為地點關係 生活機能非常好 晴光夜市裡面超多美食小吃的 而且都很便宜、銅板價 臭豆腐、滷味', metadata={}),
Document(page_content='那這次介紹就到這邊 我們下次見,拜拜!', metadata={})]
最後是集成的檢索結果:
docs = ensemble_retriever.get_relevant_documents("這影片介紹了哪些美食?")
pretty_print_docs(docs)
--- 以下是輸出內容 ---
Document 1:
那這次介紹就到這邊 我們下次見,拜拜!
----------------------------------------------------------------------------------------------------
Document 2:
中式西式都有 不過種類不多 但我覺得最驚艷的啊 是有現榨的柳橙汁 還有現榨的蔬果汁 非常新鮮 好喝 因為地點關係 生活機能非常好 晴光夜市裡面超多美食小吃的 而且都很便宜、銅板價 臭豆腐、滷味
----------------------------------------------------------------------------------------------------
Document 3:
按著、按著都覺得好消除疲勞啊 今天在晴美公寓酒店住了三天兩夜 因為都在陪家人 所以沒有太多時間來錄影 那更詳細的資訊 我都已經寫在部落格文章中了 有興趣的可以點到下方資訊參考哦 圓山大飯店
從上述的例子中,我們可以清楚地看到集成檢索器的優勢。單獨使用 BM25 或 Chroma 檢索器時,它們各自會返回與查詢最相關的文件。但當我們結合這兩種檢索器時,集成檢索器能夠綜合考慮兩者的優點,提供更全面的搜尋結果。
此外,集成檢索器的另一個優點是它的靈活性。你可以根據實際需求調整各個檢索器的權重,以達到最佳的搜尋效果。例如,如果你認為語義相似性更重要,你可以給予密集檢索器更高的權重;反之,如果你認為關鍵字匹配更為關鍵,則可以增加 BM25 的權重。
總之,集成檢索器為我們提供了一個強大而靈活的工具,能夠整合多種檢索演算法,以滿足各種不同的搜尋需求。
LangChain 的多種檢索器都具有其獨特的優點和應用場景。從基礎的向量資料庫檢索器到先進的集成檢索器,每一種都為我們提供了不同的搜尋策略和方法。希望透過這篇文章,你能夠更好地理解和運用這些檢索器,從而提高你的搜尋效率和品質。
本文的程式碼您可以參考這裏: D23. LangChain 專案實做 - 各類檢索器介紹.ipynb

