在前面的文章裡,我們稍微偏離了原先設定的專案實作路線。這主要是因為,我們認為在沒有完整介紹外部資料的讀取、文本處理、文本嵌入及向量資料庫等議題之前,很難讓讀者完全掌握其核心概念。現在,當我們已經為大家建立了這些基礎知識,我們將回到主題,探索如何利用LangChain的各種功能來實作。
我們的目標是建立一個系統:當使用者提供他們的學習情境意圖後,系統會從這些訊息中,進行一系列的操作,從檢索相似語料庫、資料轉換、到資料提取,最終生成我們所需的教材格式。
我們希望生成的教材格式如下:
例句:
We are planning to eat out dinner most evenings unless there's nothing open then we might be going to the grocery store to just try and find like a salad or something.
我們計劃大部分晚上外出用餐,除非沒有開放的地方,那麼我們可能會去雜貨店尋找像沙拉之類的東西。文法介紹: 此例句中包含了以下文法要點:...
[文法要點細節]
希望透過這篇文章,大家可以更深入地了解如何結合各種技術,生成有價值的學習教材。
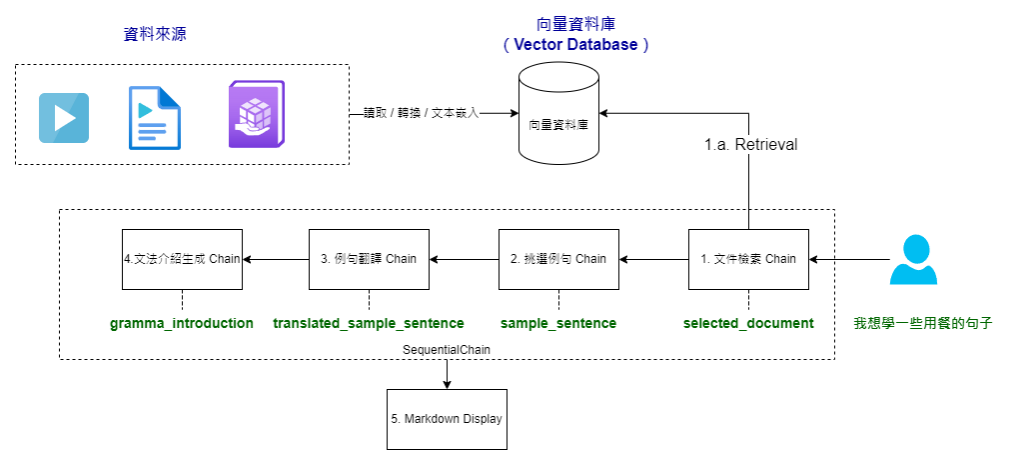
我們整個的生成流程會從使用者的輸入做為起點,例如,當使用者輸入:“我想學一些用餐的句子”,我們的系統會開始動作。一旦我們收到使用者的需求,系統會將這個輸入傳遞給專門生成例句教學內容的 SequentialChain。
這個 Chain 的工作流程如下:
當 SequentialChain 完成所有這些步驟後,我們可以從其輸出中獲取生成教學內容所需的所有資料。最後,這些資料會交給格式化程序進行整理,以便呈現給使用者。
這就是我們的「例句學習」教材生成流程的大致概念。接下來,我們會深入探討每一步的具體程式片段。
在我們深入生成程式碼之前,首先要確保我們有適當的資料來源。為此,我將使用一個測試用的字幕檔案,並透過文本分割器(TextSplitter)將其細分成多個小段文本。
選擇合適的分割 token 數量在此過程中是至關重要的。這是因為它會直接影響到後續生成的結果品質。舉例來說,如果分割得太細,你可能得到的段落會缺乏完整性,使得整體文意不夠清晰。相反地,如果分割得太粗,不僅後續的處理會需要更多的資源,檢索到的文本也可能與你的初衷大相逕庭。目前,我們選擇分割大小主要是基於「嘗試與錯誤」的方法,透過多次的實驗並根據結果來進行人工選擇。如果你有興趣親自體驗不同分割大小的效果,我們在文末提供了相關的程式碼連結供你參考。
完成上述步驟後,我們將這些文本轉化為向量資料庫。以下是相關的程式碼:
from langchain.document_loaders import SRTLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 取得影片內容
loader = SRTLoader(
'/content/ironman2023/srt_files/ROAD TRIP SNACKS_ BREAKFAST & LUNCH IDEAS _ Easy & Essential _ Road tripping during a pandemic!! - YouTube - English.srt'
)
docs = loader.load()
print(f'docs: {docs}')
# 分割文本
recursive_text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1000,
chunk_overlap = 100,
length_function = len,
)
recursive_splitted_texts = recursive_text_splitter.create_documents([docs[0].page_content])
print(f'len of recursive_splitted_texts: {len(recursive_splitted_texts)}')
# 下方是建立向量資料庫的部分
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
db_chroma = Chroma.from_documents(recursive_splitted_texts, OpenAIEmbeddings())
retriever_chroma = db_chroma.as_retriever()
這段程式碼的目的是為了確保我們在後續的步驟中能夠更精確且有效地進行文本檢索和處理。
往往我們在設計生成流程時,其實就像是編寫一部劇本。首先,你需要確定你想要的最終效果是什麼,然後再為中間的過程設計每一個角色及其職責,最後再將它們串聯起來。
另外在設計提示時,也經常會再穿插一些階段的測試項目來驗證我們片段工作的正確性。
現在,讓我們來看看完成後的這些角色和他們的任務。
首先,我們有一個「文本檢索」的角色。它的主要職責是根據使用者的意圖,從資料庫中找出最相似的語料。這次,我們選擇使用 TransformChain 結合 MultiQueryRetriever。選擇 TransformChain 的原因是,這個任務主要是一個簡單的轉換動作,不涉及語言模型的使用,所以我們可以直接使用它來呼叫指定的檢索方法。而 MultiQueryRetriever 的選擇則是基於我們希望能透過語言模型生成其他相似的查詢,以擴大我們的檢索範圍。以下是相關的程式碼:
from langchain.chains import TransformChain
from langchain.retrievers.multi_query import MultiQueryRetriever
retriever_multi_query = MultiQueryRetriever.from_llm(
retriever=retriever_chroma, llm=llm_chat
)
# 轉換程序
def document_selection_func(inputs: dict) -> dict:
user_input = inputs["user_input"]
docs_multi_query = retriever_multi_query.get_relevant_documents(query=user_input)
return {
"selected_document": docs_multi_query[0].page_content
}
document_selection_chain = TransformChain(
input_variables=["user_input"], output_variables=["selected_document"], transform=document_selection_func
)
這段程式碼確保我們能夠根據使用者的輸入,有效地從資料庫中檢索相關的文本。
測試狀況:
# 測試
document_selection_test_result = document_selection_chain.run({
'user_input': question
})
print(document_selection_test_result)
--- 以下為輸出結果 ---
really dinner related just because we are planning to eat out dinner most
evenings unless there's nothing open then we might be going to the grocery
store to just try and find like a salad or something
... 中間省略 ...
that's just how it is so we will have some snacks that probably aren't the
best for us however we are always looking for items
在這一步中,我們將挑選出一個精彩的例句。我們使用上一步得到的文本作為挑選例句的來源,並直接利用語言模型隨機選取一句。雖然這裡還有很多細節可以進一步優化和完善,但我們的目的是提供一個簡單而完整的範例,讓大家能夠清楚地看到如何將所學的知識整合起來,完成一個完整的任務。因此,我們這次不會進行過於複雜的設計。
# 提取精彩例句
from langchain.prompts.chat import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
SystemMessagePromptTemplate
)
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
def get_similar_sentences_chain():
template_system = """你是一個例句挑選器,
你的工作是從影片內容中,依照使用者的需求,挑選一句例句出來。
影片內容:{selected_document}
你只需要輸出例句,不需其他任何文字,也不需要任何標記的引號等。
"""
system_message_prompt = SystemMessagePromptTemplate.from_template(template_system)
template_human = """使用者需求: {user_input}"""
human_message_prompt = HumanMessagePromptTemplate.from_template(template_human)
chat_prompt_template = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
chain = LLMChain(llm=llm_chat, prompt=chat_prompt_template, output_key="sample_sentence", verbose=verbose)
return chain
similar_sentence_chain = get_similar_sentences_chain()
這段程式碼將幫助我們在後續的 SequentialChain 的執行中更有效地從文本中挑選出適合的例句。
測試狀況:
# 測試
similar_sentence_test_result = similar_sentence_chain.run({
'user_input': question,
'selected_document': document_selection_test_result
})
print(similar_sentence_test_result)
--- 以下為輸出結果 ---
we are planning to eat out dinner most evenings unless there's nothing open then we might be going to the grocery store to just try and find like a salad or something
在這部分,我們的目標是翻譯所選取的例句。利用語言模型,我們可以將先前步驟中得到的例句進行翻譯。想法很簡單:我們已有一句精選的例句,下一步就是將其翻譯成使用者所希望的語言。
將翻譯工作獨立成一個專門的 Chain 步驟有其優勢。這種方式使我們的提示設計更為簡潔。當你嘗試在一個提示中整合所有語言處理功能時,你可能會發現需要花很多時間微調這些提示。因此,當時間有限時,將任務分解成較小的提示單元可以更快速地開發。但這種方法的代價是可能需要更多的時間來多次呼叫語言模型。在實際應用中,這些都是我們需要權衡的考慮因素。
# sample sentence translate chain
def get_sample_sentence_translate_chain():
template_system = """你是一個專業的翻譯,請將下方例句翻譯為 {user_lang}。
例句:{sample_sentence}
"""
system_message_prompt = SystemMessagePromptTemplate.from_template(template_system)
chat_prompt_template = ChatPromptTemplate.from_messages([system_message_prompt])
chain = LLMChain(
llm=llm_chat,
prompt=chat_prompt_template,
output_key="translated_sample_sentence",
verbose=verbose)
return chain
sample_sentece_translate_chain = get_sample_sentence_translate_chain()
這段程式碼確保我們選取的例句可以被準確地翻譯,這樣可以為使用者提供更佳的學習體驗。以下是實際的測試案例:
# 測試
translate_test_result = sample_sentece_translate_chain.run({
'user_lang': user_lang,
'sample_sentence': similar_sentence_test_result
})
print(translate_test_result)
--- 實際的輸出結果 ---
我們計劃大部分晚上外出用餐,除非沒有開放的地方,那麼我們可能會去雜貨店尋找像沙拉之類的東西
當我們談到文法介紹的生成,有一點我想特別與大家分享。當你想要生成的學習材料需要支援多種語言環境時,例如你的使用者可能使用不同的語言,我們可以充分利用 OpenAI 的多語言模型功能。這意味著在提示設計時,我們可以明確指定目標翻譯語言。
這也是為什麼 OpenAI 這類的語言模型如此受到歡迎,它使我們的設計模式發生了巨大的變革。許多過去需要透過繁瑣的程式邏輯逐步設計的流程,現在我們可以直接使用自然語言來完成。
# 文法介紹提示設計
def get_gramma_intro_chain():
template_system = """你是一個專業的外語老師,你正在教一個以 {user_lang} 為母語的學生 {learning_lang}。
接下來我會提供給你一個教學例句,請說明這個例句中的文法。
教學例句: {sample_sentence}
"""
system_message_prompt = SystemMessagePromptTemplate.from_template(template_system)
chat_prompt_template = ChatPromptTemplate.from_messages([system_message_prompt])
chain = LLMChain(
llm=llm_chat,
prompt=chat_prompt_template,
output_key="gramma_introduction",
verbose=verbose)
return chain
gramma_intro_chain = get_gramma_intro_chain()
我們特意生成了中英文兩個版本的文法說明。對於非常重視多語言支援的朋友,可以仔細比較兩者的生成內容。首先,讓我們看看中文版本:
# 測試
gramma_intro_test_result = gramma_intro_chain.run({
'user_lang': user_lang,
'learning_lang': learning_lang,
'sample_sentence': similar_sentence_test_result
})
print(gramma_intro_test_result)
--- 以下是輸出的內容 ---
這個例句中有幾個文法要點:
1. "we are planning to eat out dinner most evenings":這裡使用了現在進行式(present continuous tense)來表示將來的計劃。"are planning"表示現在進行的動作,"to eat out dinner"表示計劃中的動作。
2. "unless there's nothing open":這裡使用了條件句(conditional sentence)。"unless"表示除非的條件,"there's nothing open"表示沒有任何開放的地方。
3. "then we might be going to the grocery store":這裡使用了情態動詞(modal verb)"might"來表示可能性。"might be going"表示可能會去的動作。
4. "to just try and find like a salad or something":這裡使用了不定式(infinitive)來表示目的。"to try and find"表示試圖尋找的目的,"like a salad or something"表示尋找的對象。
總結起來,這個例句中使用了現在進行式、條件句、情態動詞和不定式等文法結構。
接著,讓我們看看英文版本:
# 測試英文
gramma_intro_test_result_en = gramma_intro_chain.run({
'user_lang': '英文',
'learning_lang': learning_lang,
'sample_sentence': similar_sentence_test_result
})
print(gramma_intro_test_result_en)
--- 以下是輸出的內容 ---
In this sentence, there are several grammar points to explain:
1. Verb tense: The verb "are planning" is in the present continuous tense, indicating an action that is planned for the future.
2. Infinitive phrase: "to eat out dinner" is an infinitive phrase that functions as the purpose or intention of the planning.
3. Adverb of frequency: "most evenings" indicates that the action of eating out dinner is planned for the majority of evenings.
... 中間省略 ...
Overall, this sentence demonstrates the use of verb tense, infinitive phrases, adverbs of frequency, conditional clauses, modal verbs, and gerund phrases.
透過這樣的設計,我們可以確保所選的例句不是只有翻譯而已,在文法上也有教育意義,這對於學習者來說是非常有幫助的。
在前面的章節中,我們已經設計了各種不同的「劇本」。現在,我們將使用 SequentialChain 來將這些劇本順序地串接起來,形成一個完整的任務流程。
from langchain.chains import SequentialChain
sequential_chain_teach_caption = SequentialChain(
chains=[document_selection_chain, similar_sentence_chain, sample_sentece_translate_chain, gramma_intro_chain],
input_variables=["user_input", "user_lang", "learning_lang"],
output_variables=["selected_document", "sample_sentence", "translated_sample_sentence", "gramma_introduction"],
verbose=True)
當我們完成了任務流程的設計後,接下來的目標是將結果呈現得更加友善和易讀。這裡,我們將使用 Markdown 語法來格式化輸出結果。
# 將 chain_result_teach_caption 以 Markdown 輸出
from IPython.display import display, Markdown
def format_result(chain_result):
# 定義一個 Markdown 語法的內容
markdown_content = f"""# 精彩例句介紹
例句:
{chain_result['sample_sentence']}
{chain_result['translated_sample_sentence']}
文法介紹: {chain_result['gramma_introduction']}
"""
# 使用 IPython.display.Markdown 函數來渲染 Markdown 內容
display(Markdown(markdown_content))
以下是觸發整個任務流程並格式化輸出結果的程式碼:
# 案例一
chain_result_teach_caption = sequential_chain_teach_caption({
"user_input": question,
"user_lang": user_lang,
"learning_lang": learning_lang
})
format_result(chain_result_teach_caption)
最後,這就是我們得到的教材結果:
總結,我們已經完成了一個完整的教材生成流程。
如果你對此有興趣,歡迎點擊以下連結,開啟我們為你準備的 Colab 程式碼,自行進行實驗:D24. LangChain 專案實做 - 「例句學習」教材生成.ipynb。


 iThome鐵人賽
iThome鐵人賽