今天我們要針對三個部份的第二個部分 Model 來做說明
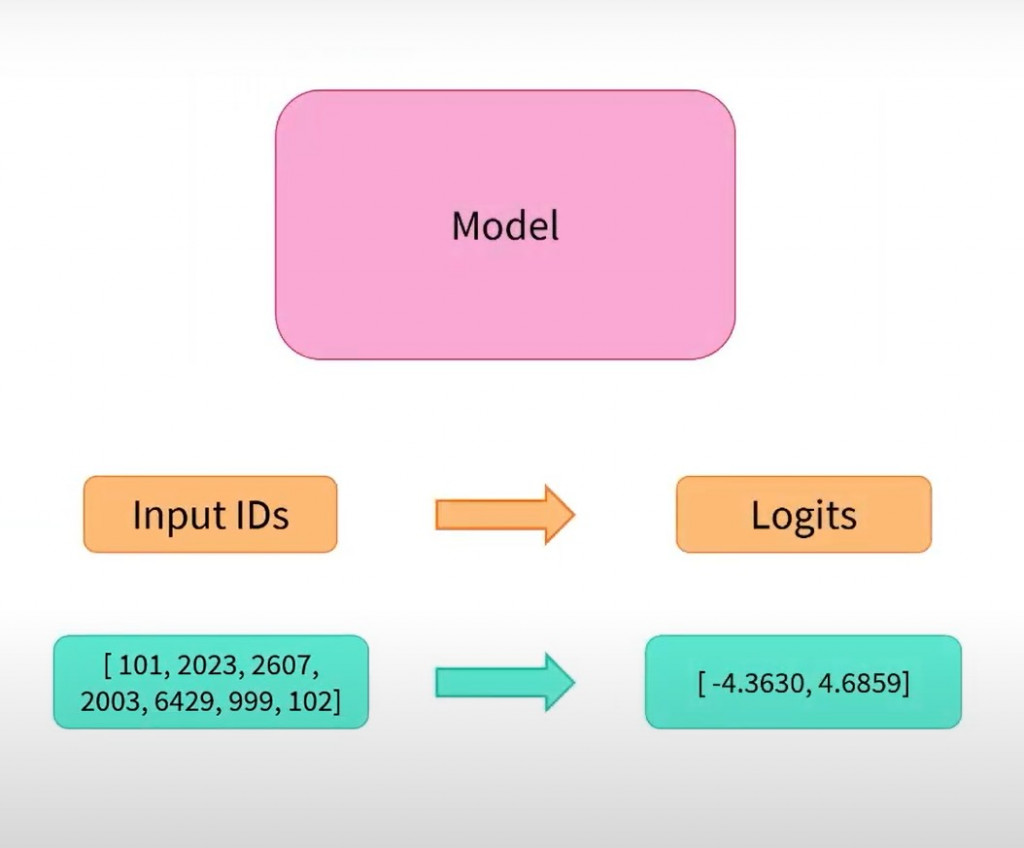
以上圖出自 Hugging Face 官方
我們要了解如何建立和使用模型,和 Tokenizer 有點類似的是有 AutoTokenizer 類別,那也有 AutoModel 這個類別,當我們想實例化任何的預訓練模型,我們可以直接使用它,它會根據給定的模型標識自動選擇適合的模型結構,然後用這個結構來建立模型實例。
然而,如果知道我們想要使用的模型類型,我們可以直接使用定義架構的類別。接下來我們就使用 BERT 模型,類別會使用 BertModel。
初始化BERT模型需要做的第一件事是載入配置物件
from transformers import BertConfig, BertModel
model_name = "bert-base-cased"
# Building the config
bert_config = BertConfig.from_pretrained(model_name)
print(bert_config)
來看一下 bert_config 長什麼樣子,以下是它完整的內容
BertConfig {
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"classifier_dropout": null,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"position_embedding_type": "absolute",
"transformers_version": "4.33.2",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 28996
}
講解相對重要的配置參數
hidden_size:定義了每個隱藏層的維度,決定了模型的表示能力。一般情況下,其值為 768 或 1024,它會影響模型的效能和計算成本。
num_attention_heads:它用來控制模型在處理輸入文本時的注意力機制頭的數量。注意力機制允許模型在處理文本時同時關注不同位置的信息,類似於人的注意力可以在看一幅畫時同時關注多個區域。通常,其值為12。
num_hidden_layers:它決定了模型的深度,也就是模型內部的層數。這個參數指定了BERT模型中包含多少個隱藏層。增加值可以增強模型的表示能力,但同時增加模型的運算資源需求。通常,其值也為12。
intermediate_size:定義了BERT模型中間層的維度。此層通常比較大,用於捕捉更複雜的特徵。通常,其值為3072。
attention_probs_dropout_prob和hidden_dropout_prob:分別指定了注意力和隱藏層的dropout機率。它們用於防止模型過度擬和(在訓練資料上表現太好,但在新資料上表現較差)。通常,其值為0.1。
initializer_range:權重初始化的範圍。這個參數影響了模型的訓練收斂速度和性能。通常,其值為0.02。
使用載入的設定資訊bert_config建立了一個BERT模型實例
# Building the model from the config
model = BertModel(bert_config)
跟 tokenizer 的保存方法一樣,使用 save_pretrained() 的方法
model.save_pretrained("directory_on_my_computer")
這時候在資料夾底下就會看到兩個檔案
directory_on_my_computer
├── config.json
└── pytorch_model.bin
昨天最後得出的張量
{
'input_ids': tensor([
[101, 2769, 1962, 2682, 6206, 1139, 1343, 4381, 102, 0, 0, 0, 0, 0],
[101, 791, 1921, 1921, 3706, 1962, 4229, 8024, 679, 6900, 1394, 1139, 7271, 102]]),
'token_type_ids': tensor([
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]),
'attention_mask': tensor([
[1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])
}
from transformers import BertModel
checkpoint = 'bert-base-chinese'
final_input = (上方的張量)
model = BertModel.from_pretrained(checkpoint)
output = model(**final_input)
來看看模型最後一層的隱藏狀態的形狀
print(outputs.last_hidden_state.shape)
# output
torch.Size([2, 14, 768])

