今天我們要針對三個部份的最後一個部分 PostProcessing 來做說明
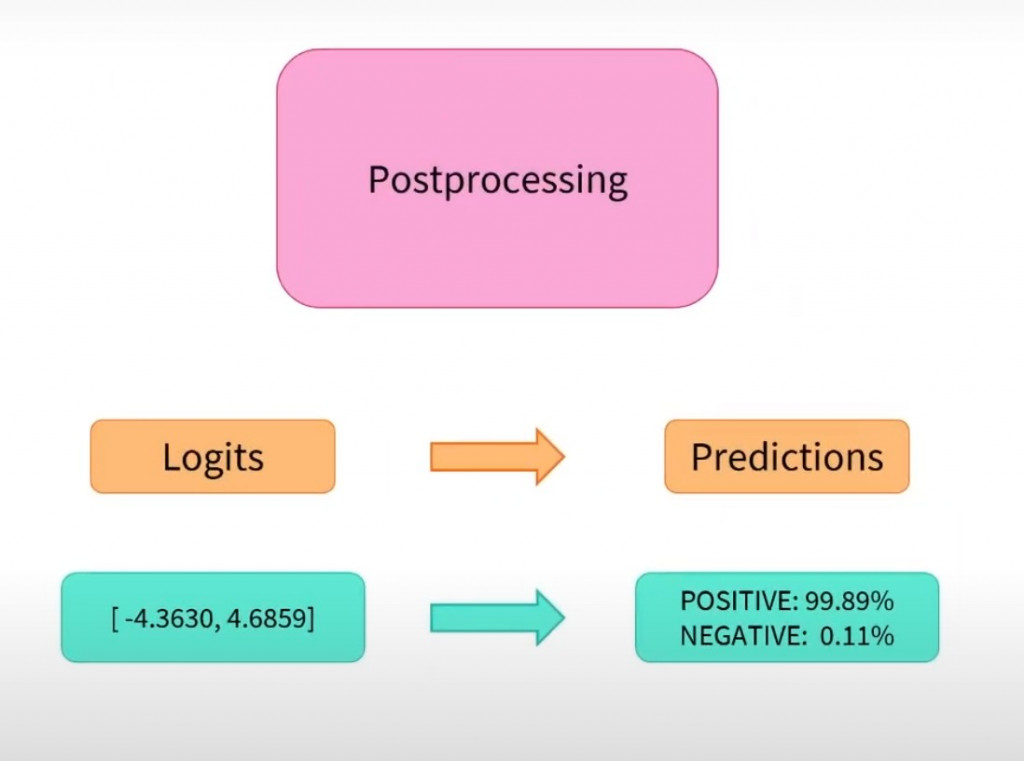
以上圖出自 Hugging Face 官方
PostProcessing這個動作事是用於對模型輸出進行一系列轉換和處理操作的入口,目的是使模型的輸出更加有用、易於理解並適合後續任務。
要補充一下,在昨天說到的 Model 的完整範例中,沒有說得很完整,因為使用 BertModel 或是 AutoModel,無法轉換為上圖中的 logits,所以來仔細說明一下。
我們使用另一個類 AutoModelForSequenceClassification 這個是一個通用文字分類模型,它能夠適用於多種文字分類任務,又或是我們如果要使用 BERT 相關的預訓練模型我們也可以直接使用 BertForSequenceClassification。
那我們就使用 BertForSequenceClassification 來當範例,一樣使用 day12那天得出的最後張量
{
'input_ids': tensor([
[101, 2769, 1962, 2682, 6206, 1139, 1343, 4381, 102, 0, 0, 0, 0, 0],
[101, 791, 1921, 1921, 3706, 1962, 4229, 8024, 679, 6900, 1394, 1139, 7271, 102]]),
'token_type_ids': tensor([
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]),
'attention_mask': tensor([
[1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])
}
from transformers import BertForSequenceClassification
final_input = (上方的張量)
model = BertForSequenceClassification.from_pretrained("bert-base-chinese")
outputs = model(**final_input)
print(outputs.logits)
輸出的結果
tensor([[-0.5755, 0.4357],
[-0.9901, 0.1685]], grad_fn=<AddmmBackward0>)
最後就是要將這個輸出結果轉換成機率。
import torch
import torch.nn.functional as F
# 將上面的output.logits存在final_logits
final_logits = outputs.logits
# 使用 softmax 函数将 logits 转换为概率分布
probabilities = F.softmax(final_logits, dim=-1)
print(probabilities)
輸出的結果
tensor([[0.2667, 0.7333],
[0.2389, 0.7611]], grad_fn=<SoftmaxBackward0>)
我們也可以讓他產生對應的標籤映射
label_map = model.config.id2label
print(label_map)
-> {0: 'LABEL_0', 1: 'LABEL_1'}
import torch
predicted_indices = torch.argmax(predicted_labels, dim=1)
print(predicted_indices)
-> tensor([0, 0])
predicted_labels = [label_map[label.item()] for label in predicted_indices]
print(predicted_labels)
-> ['LABEL_0', 'LABEL_0']

