在 HPA spec 中還有個參數可以設置 - behavior 。behavior 底下可設置 scaleDown & scaleUp 的規則。例如:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: my-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-deployment
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
behavior:
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
scaleUp:
stabilizationWindowSeconds: 0
policies:
- type: Percent
value: 100
periodSeconds: 15
- type: Pods
value: 4
periodSeconds: 15
selectPolicy: Max
上面的 behavior 是預設的數字,也就是沒有設置 behavior 預設會使用的數值。
搭配前一天的圖來看,大概在 3m ~ 3m15s 左右停止發送請求,平均 CPU 使用量在 3m15s 變成 38m。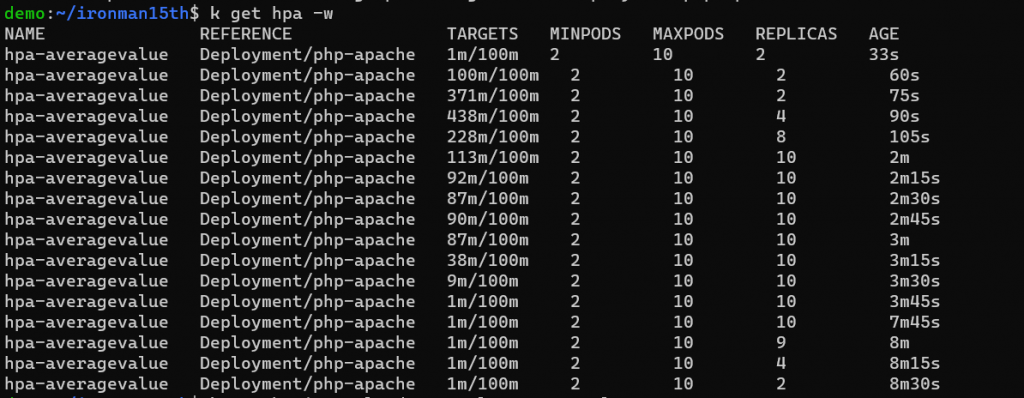
scaleDown 的部分 -
stabilizationWindowSeconds : 這個參數可以用來穩定 replicas 數量,因指標波動就會啟動 scale up / scale down,那這樣數字可能會在短時間內快速變化 (flapping / thrashing)。而這邊設置 stabilizationWindowSeconds = 300,則是指如果根據指標計算目標 pods 需要 scale down,系統會考慮 300 秒這段時間內所有的期望狀態,選擇這段時間內所需要的 replicas 數量最多的狀態當作目標 replicas 數量。而期望狀態是多久算一次呢?預設是 15 秒,由 kube-controller-manager 的 --horizontal-pod-autoscaler-sync-period 參數決定。policies 的部分是指在每個 periodSeconds (15s) 內,最多可以減少 100% 的 Pods,但還要符合最小的 replicas number,所以這邊在 stable window 中 - 過去 300s 中 - 若 desired number = 2 時,就會縮減 Pod 數量變成 2。但上圖還是出現了 9 & 4 這樣的數字,目前不負責任猜測應該是關閉 Pod 需要一些時間 ……
periodSeconds: 在定義的時間內,replica 變化的數量最多不會超過 percent or pods 定義的數量;限制單位時間內 scale up or scale down 的最多副本數量type = Percent → 百分比,也可以是 Podsvalue = 100 → 這邊是 100%,如果是 Pods 就是指在 periodSeconds 內最多只能有多少個 Pods 被砍掉。selectPolicy : scaleDown 沒有設,預設會是 Max,也就是會選擇最大數量改變的那個 policy,但以 scaleDown 這邊只有一種 Policy。也可以設置 Disables,在這邊就是將 scaleDown 功能關閉。scaleUp 的部分 -
stabilizationWindowSeconds : 預設是 0,如果需要擴展 Pods,就直接增加policies : 有兩個
selectPolicy : 設置是 Max,代表每次評估時會從上述的兩種 Policy 選擇最大數量改變的那個 Policy但是!目前官網上提供的 HPA algorithm 及 default behavior 的資訊與實測的結果對不太上。Pod 增加的數字小於 algorithm 計算出的數字,以 scaleUp policy 來看在 2 → 4 的這個階段並沒有選擇增加4 個 pods 這個 Policy。目前只在簡體中文的網頁中看到一個敘述 -
某个时间点开始metrics数据大幅增长,导致最后计算的副本数变化倍数很大,是否HPA控制器会一步扩容到位呢? 事实上HPA控制器为了避免副本倍增过快还加了个约束:单次倍增的倍数不能超过2倍,而如果原副本数小于2,则可以一次性扩容到4副本,注意这里的速率是代码写死不可用配置的。(这个也是HPA controller默认的扩缩容速率控制,autoscaling/v2beta2的HPA Behavior属性可以覆盖这里的全局默认速率)
(https://zhuanlan.zhihu.com/p/245208287)
但這邊又提了 behavior 可以覆蓋這個 default 規則 ……。
一時無法解釋決定在這邊先打住,至少在概念上理解了 behavior 設置會考慮什麼。
而一般情況下需要擴展的情況較為緊急,所以 stabilizationWindowSeconds 設為 0 可快速增加 Pods 數量以應付流量,而對於要減少 Pod 的情況則較為嚴格,來讓這個數量不要來回波動太大。
會以 HPA 的規則為主。不管是下面哪種情形,等 HPA 開始作用後就會根據 HPA 的規則去調整 Pod 數量。
第一種情況,設 deployment replicas = 1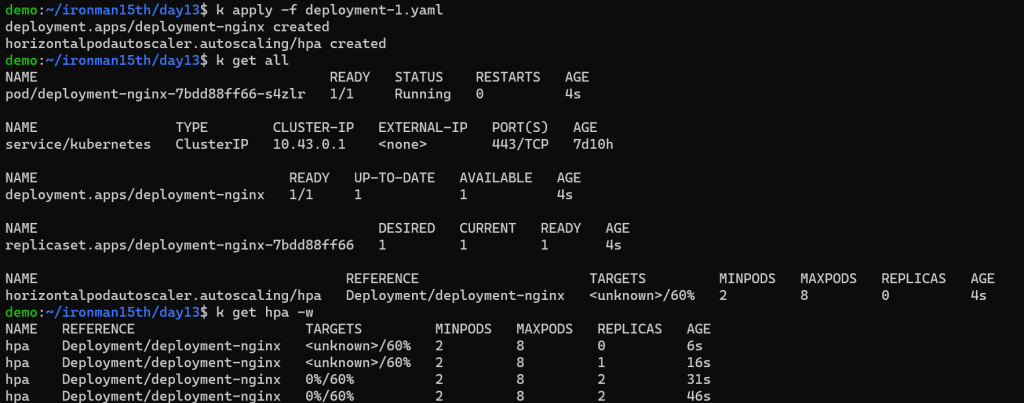
第二種情況,設 deployment replicas = 4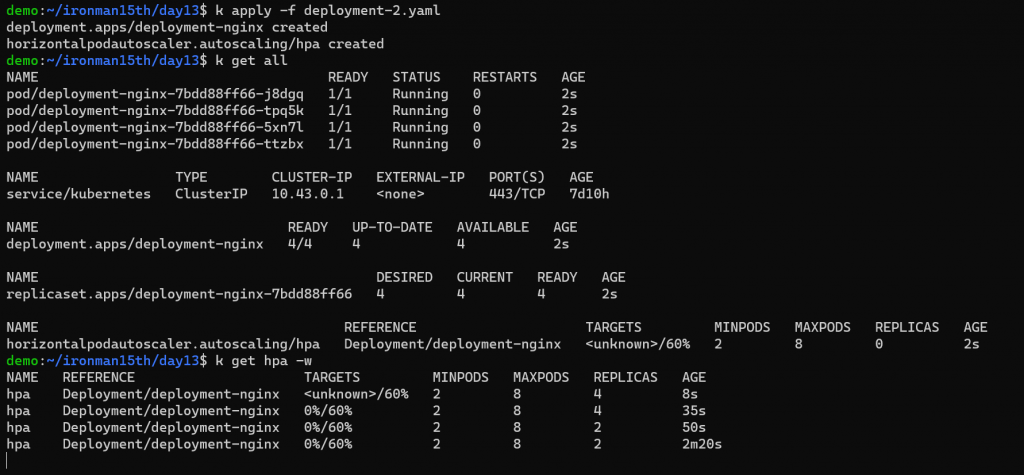
第三種情況,設 deployment replicas = 10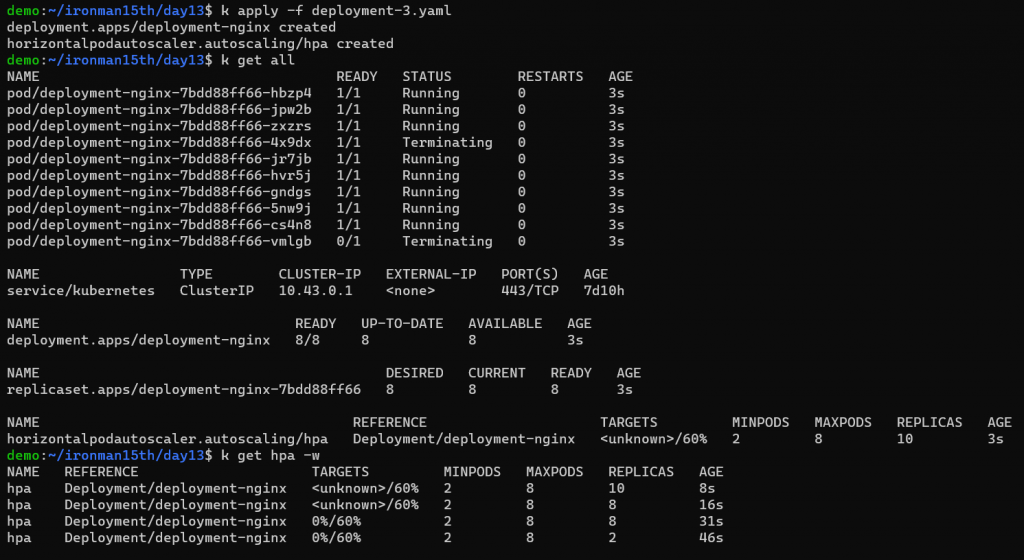
因 nginx 目前沒有流量過去,套用 HPA,Running Pods 會是最小的數量 = 2
如果指定 deployment replicas,在更新 Pod template 時 (例如 image 更新),kubernetes 會先想辦法讓 Pod 數量符合 deployment 中設的數字 (這邊也呼應上一個段落的觀察,會先套用 deployment replica 的數字才套用 HPA 的設定),那有可能短時間 Pod 數量會無法支撐服務的流量。
對於 behavior 的設置以及數量變化是怎麼計算這還是滿多疑問……現在先把問題留著QQ
之後會研究 KEDA,一個能支援多種指標,包括外部服務的事件來做自動擴展的工具。
Reference
https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commands#autoscale
https://kubernetes.io/docs/reference/kubernetes-api/workload-resources/horizontal-pod-autoscaler-v1/
https://kubernetes.io/docs/reference/kubernetes-api/workload-resources/horizontal-pod-autoscaler-v2/
https://zhuanlan.zhihu.com/p/245208287


 iThome鐵人賽
iThome鐵人賽