前面介紹了 Deployment,能夠讓我們決定要用多少個 Pods 來跑我們的服務,但這邊 Deployment 設定的 replicas 是固定的。如果流量低的時候我們可能不需要這麼多 Pods,又或是尖峰時刻可能要多開幾個 Pods。Deployment 可以透過手動的方式來改變 replicas 的數量,但有沒有更方便的方式來做自動擴展呢?
HorizontalPodAutoscaler 可以幫忙做到這件事!
先來看 HorizontalPodAutoscaler (HPA) spec -
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: hpa-utilization
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60
相對應的指令:
kubectl autoscale deployment php-apache --cpu-percent=60 --min=2 --max=10
這邊的 apiVersion 是 autoscaling/v2,v2 比起 v1 多支援了不同種的 metrics,使用上要確認一下使用的 kubernetes version 是支援哪個 api 版本。
其中 scaleTargetRef 是指這個 HPA target 是哪個 object。HPA 可以用在 ReplicaSet、Deployment、StatefulSet 這類的 object 做水平擴展,但 DaemonSet 不適用。DaemonSet 的特性後續的篇數會介紹。
再來是 minReplicas & maxReplicas,根據 target metrics 對數量做調整,最小的 replica 數量跟最大的 replica 數量。
metrics 就是最重要的部分,要用什麼樣的指標來決定是否擴展或是縮減。這邊 metrics 的 type 是 Resource,指的是 pod 使用的 CPU 或是 memory。target 種類有 Utilization 、Value、AvaerageValue ,搭配底下的參數 averageUtilization、value、averageValue 去設定數字。不過我一時找不到使用 Value 的例子,實測 apply yaml 也出現錯誤。所以這篇就只會放 Utilization & AvaerageValue 的例子。
metrics 除了 resource 以外,也支援別的指標。例如 ContainerResource,假設你的應用程式中有其他輔助的 container,在擴展時你不希望把其他 sidecar container 的資源運用也考慮進來,可以指定要針對哪個 container 做 resource metrics 計算。其他還有 external、object 可使用。
先照官網的例子來實作看看。
這邊會先使用 deployment & service 建立一個 php-apache 的 app,然後使用 script 去連續訪問這個 app,模擬流量變高的情形。Apply HPA 設定到這個 deployment 後,能觀察到 Pod 自動擴展的過程。
步驟 1 - 建立 deployment & service
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: registry.k8s.io/hpa-example
ports:
- containerPort: 80
resources:
limits:
cpu: 500m
requests:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
spec:
ports:
- port: 80
selector:
run: php-apache
步驟 2 - 套用 cpu averageUtilization 訂為 60% 的 HPA
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: hpa-utilization
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60
這時可以用 kubectl get 觀察一下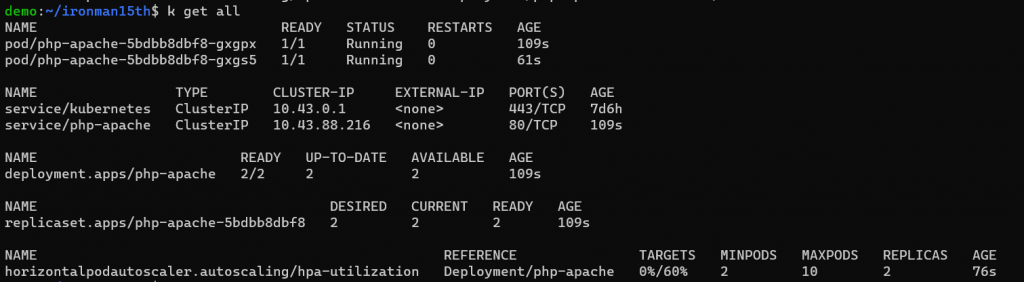
在 deployment 中如果沒有設置 replicas,預設會是 1,不過使用 hpa 控制 deployment 的話會建議就不要在 deployment 設 replicas。這邊會套用 hpa 設定的最小 replica 數量,pod 數量為 2。目前沒有流量,可以看到 hpa Targets 目前是 0%。
步驟 3 - 製造些流量。開啟新的 terminal,用以下的指令建立另一個 Pod,每隔 0.01 秒就向 php-apache 這個 service 發請求。
kubectl run -i --tty load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
這個指令是建立一個用 busybox 為 image 的 Pod (container),啟動一個互動式的 terminal ,執行後面 while sleep 0.01; do wget -q -O- http://php-apache; done 的指令。如果這個 Pod 終止就 remove。
這時畫面上應該會有 OK! 的回應 -
步驟 4 - 用另一個 terminal 以指令 kubectl get hpa -w 觀察 resource 使用量及 Pod 數量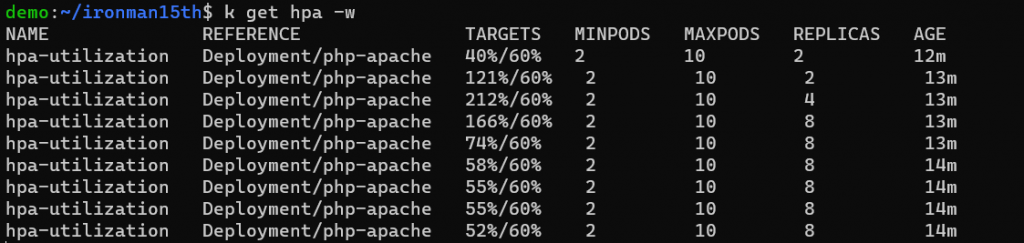
(可用 hpa 當作 horizontalpodautoscalers 的縮寫)
可以看到 pods 變多了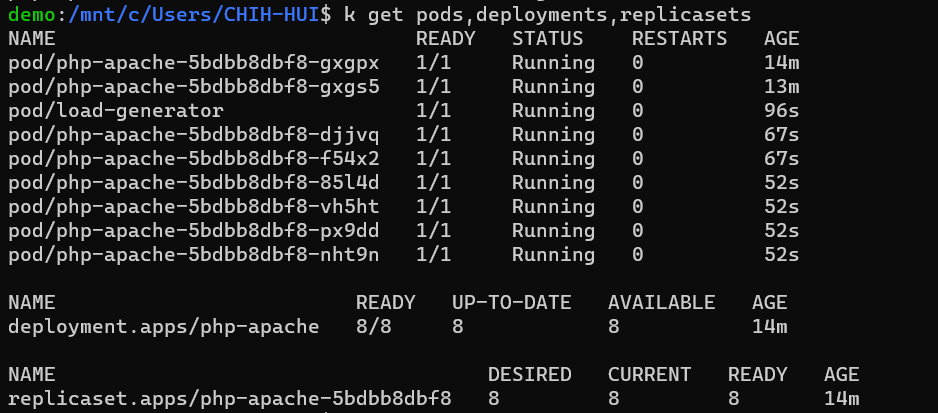
觀察一陣子可以發現如果是這個速率的請求,大概 8 個 pods 就能把 average cpu utilization 壓在 60% 以下。如果將 busybox 那個 pod 關掉,再放一陣子就能觀察到 pod 數量慢慢減少。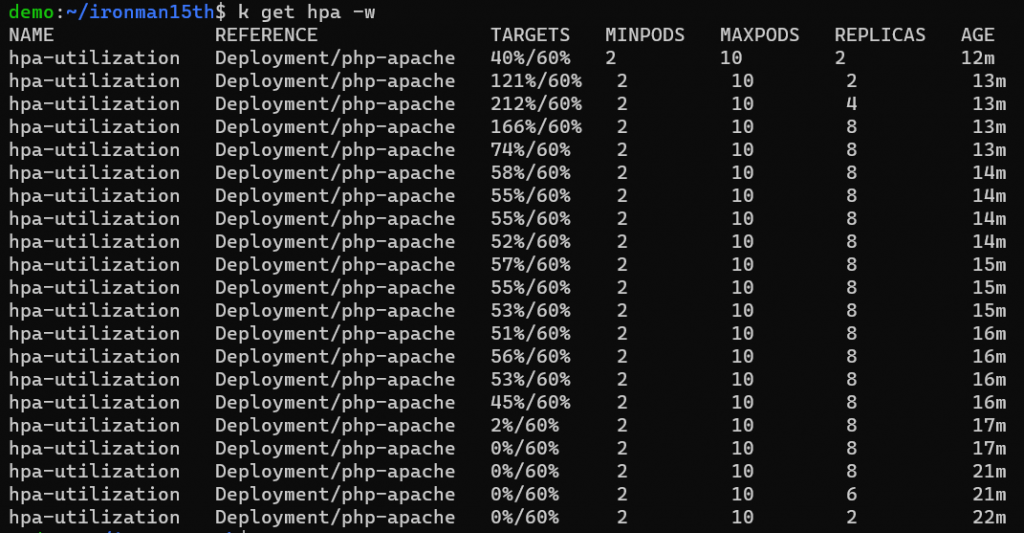
不過這個 averageUtilization 是指什麼?指定 60%,又是什麼東西的 60%?
官網上有介紹 HPA 的 algorithm 是怎麼算的 →
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
以 avaergeUtilization 來說
每個 Pod 會有 CPU 使用的數字,則平均使用量會類似下面的計算:
Container 1 uses 120m cpu ; request 200m cpu
Container 2 uses 160m cpu ; request 200m cpu
⇒ avaergeUtilization: (120+160) / (200+200) = 70%
目前平均 CPU utilization = 70%,超過 target 60%了。套用公式計算:
2 * ( 70% / 60% ) 無條件進位 = 3 → desired replicas = 3
所有目標的 Pod 的 CPU 使用量會跟 request 去做比較,計算出平均使用率。HPA 的計算再使用這個平均使用率來計算是否要增加或減少 replicas。
另外在 apiVersion v2 當中可以設定 scaleUp & scaleDown 的 behavior 來指定 Pod 變化的行為,例如固定時間內可以改變多少個 pod,會在下一篇提到。
而如果 target type 是AvaerageValue ,spec 會寫成這樣 -
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: hpa-averagevalue
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: AverageValue
averageValue: 0.1 # 100m
使用指令觀察會看到 Target 的部分換成了 100m。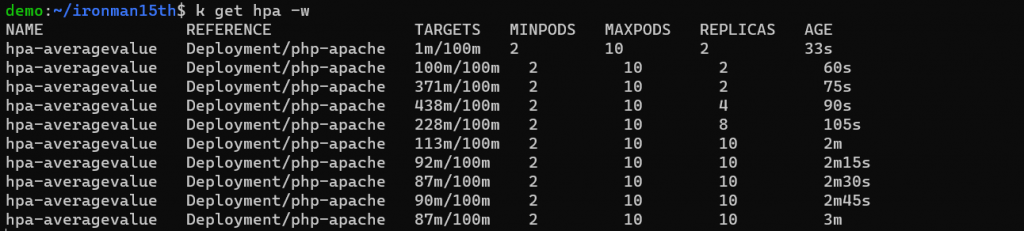
計算上就比較好理解了,實際的 metrics 就會是所有 Pod CPU 使用量的平均數。
最後的最後,HPA 可以設置不只一種 metrics 來做擴展,例如下方例子:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
- type: Pods
pods:
metric:
name: packets-per-second
target:
type: AverageValue
averageValue: 1k
- type: Object
object:
metric:
name: requests-per-second
describedObject:
apiVersion: networking.k8s.io/v1
kind: Ingress
name: main-route
target:
type: Value
value: 10k
如果使用了多種指標,在需要擴展的時候,在計算每個 metrics 需要的 replica 後,HPA 會選擇最大的 replica number,來保證每一組條件都達到。也就是 HPA 會保證平均來說每個 Pod 使用 requested PU 的 50%、每秒能處理 1000 個封包、在 main-route 這個 Ingress 導向流量的 Pod 每秒能夠處理 10000 個請求。
HPA 內容好多 🥴 控制要擴展多少 Pod 或縮減多少 Pod 有好多面向可調配。明天預計提的內容:
behavior)Reference
https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commands#autoscale
https://kubernetes.io/docs/reference/kubernetes-api/workload-resources/horizontal-pod-autoscaler-v1/
https://kubernetes.io/docs/reference/kubernetes-api/workload-resources/horizontal-pod-autoscaler-v2/


 iThome鐵人賽
iThome鐵人賽