昨天我們講解了如何使用爬蟲,目的是為了後續我們可以使用自己所收集的數據,這樣一來才能讓自己做的模型可以實際使用,不然一直使用外部整理好的資料集有點太無聊了對吧! 下面先讓我們來準備資料處理,把昨天的爬蟲做延續。
在昨天爬蟲程式有些地方需要注意,我們下面分段說明
你可能會注意到在google圖片裡,下拉畫面就算有顯示更多也有滑到底的時候,而下載下來的圖片可能會覺得太少。這時你可以選擇改關鍵字例如人像換成人、人類等等,一樣能符合需求的,或者以其他網站來獲取以便資料量符合需求,而資料不值對模型可能造成多方面的影響,這些影響通常是負面的如
模型性能下降:資料不足導致模型無法學習足夠的特徵和模式,因此模型的性能可能會下降。
泛化能力差:當資料不足時,模型可能會過度擬合(overfitting)已有的資料,而無法有效地泛化到新的、未見過的資料,導致模型在實際應用中表現不佳,因為它無法處理各種不同的情況。
偏誤和失衡:如果爬蟲僅獲取了某些特定類別或主題的資料,模型可能會變得偏向這些類別或主題,而對其他類別或主題的預測能力較差,對不同類別的預測不平衡。
不確定性增加:當資料量不足時,模型對於預測的不確定性通常會增加,這表示模型的預測可能變得不太可靠,因為它缺乏足夠的資訊來進行確定性預測。
無法處理極端情況:某些模型需要足夠的極端情況(例如罕見事件或極端值)來學習如何處理這些情況。如果資料不足,模型可能無法正確處理這些極端情況,並可能對其反應不當。
解決資料不足的問題通常包括擴展訓練資料集、使用合成資料生成技術、選擇更適合的模型架構,以及採用正規化技術,以減少過度擬合的風險。
而除了資料數很重要外,將訓練集中不相關圖片篩選掉也是機器學習和深度學習任務中一個重要的步驟,因為這些不相關圖片可能會對模型的性能產生負面影響,下面我們列出幾點
資料質量的重要性:模型的性能很大程度上取決於所使用的訓練資料的品質,如果訓練集中包含許多不相關或無關的圖片,模型可能會學習到錯誤的特徵和模式,導致性能下降。
資料分布的不均衡:如果不相關的圖片在訓練集中佔據大多數,則模型可能會偏向於預測這些不相關類別,而忽略了真正有關的類別,導致模型的分類結果不平衡,並降低了其在實際應用中的效用。
訓練時間和資源的浪費:訓練機器學習模型需要大量的計算資源和時間,如果訓練集包含大量不相關圖片,則這將導致浪費計算資源和訓練時間,因為模型需要處理無用的資訊。
模型過度擬合的風險:過多的不相關資料可能會增加模型的過度擬合風險,模型可能會試圖學習訓練集中的所有噪聲,而不是真正的模式,這將導致其在新資料上的泛化能力下降。
而上面兩大點解決後還有一個問題,在爬蟲下載資料過程中檔案名稱可能沒有連續,有時會在過程下載出錯,或者程式不完全等,,或者在將不相關圖片去除後所留空,這時若是沒有先做處理則會對後續模型訓練造成麻煩,造成如
特徵提取:如果檔名和副檔名不同,模型在特徵提取方面可能會遇到挑戰。一些模型可能會依賴檔名或副檔名來識別檔案的類型或內容,當檔名和副檔名不匹配時,模型可能難以正確地識別資料。
模型訓練的複雜性:深度學習模型在處理不同類型的資料時可能需要更複雜的架構,如果您的資料包含多種不同的檔案類型,模型可能需要更多的層次來處理這些不同類型的資料,這可能導致更複雜和難以訓練的模型。
混淆和錯誤:檔名和副檔名不匹配可能導致混淆和錯誤。例如,如果一個文本檔案的檔名指示它是圖像檔案,模型可能會對其進行不正確的處理。
預處理需求:處理檔名和副檔名不同的資料可能需要額外的預處理步驟,以確保模型能夠正確理解資料。
檔案分類挑戰:如果您的目標是對資料進行分類或分群,檔名和副檔名不同可能會使分類變得更加複雜,需要學習如何區分不同的檔案類型,這可能需要更多的訓練資料和更複雜的模型。
檔名和副檔名不同的情況可能會增加模型處理資料的複雜性和挑戰性,在處理這種資料時需要仔細考慮預處理、模型選擇和訓練策略,以確保模型能夠有效地處理不同類型的檔案並獲得良好的性能。
小提醒:昨天的爬蟲資料只是範例,若拿來使用在爬新的資料時,以人圖片為例子,在你第一次下載完後要更改程式裡m的變數,改成最後檔名+1,不然他會把檔案覆蓋。
以昨天爬蟲為例的話,這裡我們只要將圖片名直接從新命名從1開始排就能解決!
一樣先引入函式庫
import os
import glob
os 模組是 Python 的內建模組之一,它提供了許多用於與操作系統相關的功能,如新增、刪除、重命名、移動檔案等等
glob 模組也是 Python 的標準模組之一,它的主要功能是列出滿足特定模式的檔案名稱。
allfiles = glob.glob('*.png') #原始圖片副檔名
for afile in allfiles:
os.rename(afile, 't_'+ afile)
首先
glob.glob(pattern) 此函數會返回所有匹配模式的檔案名稱的列表,其中 pattern 是包含萬用字元的字串(例子中的'*'字),也就是例子中會把結尾為'.png'檔案名稱回傳到allfiles裡。
再來 for 迴圈中則把所有剛記過的檔案全更改成 't_' + 原本檔名 ,如果原始檔名是 "image.png",則修改為 "t_image.png"。
allfiles = glob.glob('*.png')#二次圖片副檔名
count=1 #起始檔案名(數字)
for afile in allfiles:
new_filename = str(count) + '.png' #(檔案名稱與數字)
print (new_filename)
os.rename(afile, new_filename)
count += 1
print("Done")
再來這裡又使用 glob.glob 找到*以 "t_" 開頭的檔案。
最後以迴圈把標記的檔案全改成 計數器當前數 + '.png' 把所有檔案名稱完成更改
整理結果 (下載圖片來自google圖片搜尋)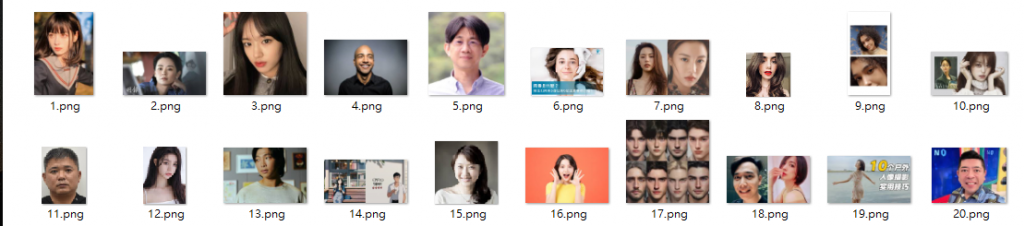
以上就是整體流程,你可以把最上方改成jpg就可以把jpg檔改成png,當然改副檔名之前要確定還能夠開啟檔案,免得沒解決麻煩反而製造更多問題。
總之上面例子可以把他更改成符合你需求的,主要動作都是先找特徵,之後掐頭去尾之類動作再利用for迴圈來完成檔案名稱的整理。
以上就是今天內容~明天開始又會回到模型部分,昨天加今天的程式來把之後要使用的訓練集準備好,找兩種類別並整理好檔案以便明天訓練模型,最後祝大家中秋節快樂~

