不知道各位烤肉有沒有吃飽飽,昨天吃飽飽今天來稍微動動腦,前兩天我們練習了如何使用爬蟲來獲取我們所需圖片與檔案的整理,今天我們將使用我們選擇好的圖片來做模型訓練,而在模型訓練後再來學習如何儲存權重,下面我們先稍微講儲存權重與模型。
使用torch.save來儲存整個模型時,它將保存模型的完整結構和所有權重,包括卷積層、全連接層、激勵函數等。
用途:這可以完全恢復模型,包括其架構,並在需要時繼續訓練。
用途:僅保存和讀取訓練過程中的權重以便後續使用,可以節省儲存空間,並且更靈活,可以將權重應用於不同的模型結構中。
也就是說當你只儲存權重,在下一次要使用時你需要先重新定義模型才能使用。
以上就是儲存模型與權重的簡短說明,下面讓我們進入實作。
我們使用自己所建立的資料及來做測試,我的訓練集是以下圖方式放置
images/train/ 0放一種 1放一種
import os
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader, random_split
from PIL import Image
import torch.nn.functional as F
import matplotlib.pyplot as plt
from tqdm import tqdm # 顯示進度條
class Setdata(Dataset):
def __init__(self, path, transform):
# 初始化資料的地方
self.x, self.y = [], []
for classes in os.listdir(path):
file_path = os.path.join(path, classes)
for file_name in os.listdir(file_path):
img_laspath = os.path.join(file_path, file_name)
datas = transform(Image.open(img_laspath).convert("RGB"))
self.x.append(datas)
self.y.append(int(classes))
self.y = torch.tensor(self.y)
def __getitem__(self, index):
# 每次訓練時會通過__getitem__取得我們需要訓練的資料
return self.x[index], self.y[index]
def __len__(self):
# 判斷資料的大小
return len(self.x)
這段程式碼定義了一個自定義的資料集類別Setdata,繼承自PyTorch的Dataset類別,用於載入圖像資料集。下面讓我們來了解這個類別的主要功能:
class Setdata(Dataset):: 這行程式碼定義了一個名為Setdata的類別,並指定它繼承自Dataset類別,這是PyTorch中用於處理資料集的基本類別。
def __init__(self, path, transform):: 這是Setdata類別的建構子(constructor)函數,它在創建Setdata類別的實例時會被呼叫,使用方式
path: 表示圖像資料所在的路徑。transform: 表示圖像資料的轉換函數,用於將圖像轉換為模型可處理的格式。在建構子函數中的程式碼執行以下操作:
self.x和self.y,它們將用於儲存圖像數據和對應的標籤。os.listdir(path)列舉指定路徑path下的所有資料夾,每個資料夾代表一個類別(class)。os.listdir列舉該資料夾下的所有檔案,每個檔案代表一個圖像樣本。os.path.join函數組合路徑,將資料夾路徑和檔案名稱組合成完整的圖像路徑。Image.open函數讀取圖像,並使用.convert("RGB")轉換成RGB色彩空間(確保圖像為三通道的彩色圖像)。self.x串列中。self.y串列中。self.y串列轉換為PyTorch的張量(tensor)形式,以便後續在深度學習模型中使用。總之Setdata類別的主要功能是載入圖像資料,並將圖像資料轉換為PyTorch模型可以處理的格式,同時保留了圖像對應的類別標籤。
class CNN(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 16, 3)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, 3)
self.fc1 = nn.Linear(32 * 30 * 30, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 2)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(x.size(0), -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
這部分定義了一個卷積神經網路(CNN)模型,
super().__init__(): 這一行程式碼呼叫了父類別nn.Module的建構子,確保繼承自nn.Module的初始化工作得以執行。
接下來的程式碼定義了模型的各個層:
self.conv1 = nn.Conv2d(3, 16, 3): 這是第一個卷積層,它使用nn.Conv2d類別創建,接受的參數包括輸入通道數(3,因為一般的彩色圖像有RGB三個通道)、輸出通道數(16,這代表了卷積核的數量)、卷積核的大小(3x3)。self.pool = nn.MaxPool2d(2, 2): 這是最大池化層,用於減少圖像的尺寸,它的功能是將每2x2區域中的最大值保留下來,並將其作為新的特徵值。self.conv2 = nn.Conv2d(16, 32, 3): 這是第二個卷積層,輸入通道數為前一層的輸出通道數(16),輸出通道數為32。self.fc1 = nn.Linear(32 * 30 * 30, 120): 這是第一個全連接層,它將卷積層的輸出展平為一維張量,並將其輸出到具有120個神經元的全連接層。self.fc2 = nn.Linear(120, 84): 這是第二個全連接層,接收來自前一層的120個特徵,並將其輸出到具有84個神經元的全連接層。self.fc3 = nn.Linear(84, 2): 這是最後一個全連接層,用於二元分類任務,它將84個特徵輸出到2個神經元,分別代表兩個類別。當然你可以自己選擇當中各層要怎麼設定,調整出一個適合自己目標的模型。
def train(train_loader, test_loader, model, optimizer, criterion):
# 訓練模型的函數
epochs = 20
loss_record = {'train': [], 'test': []}
for epoch in range(epochs):
train_acc = 0
train_loss = 0
train = tqdm(train_loader)
model.train()
for cnt, (data, label) in enumerate(train, 1):
data, label = data.to(device), label.to(device)
outputs = model(data)
loss = criterion(outputs, label)
_, predict_label = torch.max(outputs, 1)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
train_acc += (predict_label == label).sum()
train.set_description(f'train Epoch {epoch}')
train.set_postfix({'loss': float(train_loss) / len(train_dataset), 'acc': float(train_acc) / len(train_dataset)})
print(train_loss)
print(epoch)
loss_record['train'].append(train_loss)
model.eval()
test = tqdm(test_loader)
test_acc = 0
test_loss = 0
for cnt, (data, label) in enumerate(test, 1):
data, label = data.to(device), label.to(device)
outputs = model(data)
losst = criterion(outputs, label)
_, predict_label = torch.max(outputs, 1)
test_loss += losst.item()
test_acc += (predict_label == label).sum()
test.set_description(f'test Epoch {epoch}')
test.set_postfix({'loss': float(test_loss) / len(test_dataset)}, {'acc': float(test_acc) / len(test_dataset)})
loss_record['test'].append(test_loss)
print(test_loss)
# 只儲存權重
torch.save(model.state_dict(), 'model_weights.pth')
show_training_loss(loss_record)
在這裡,epochs被設置為20,表示模型將進行20個完整的訓練週期。
訓練模式:使用model.train()將模型切換到訓練模式。這對於啟用模型的訓練相關功能,例如Dropout和Batch Normalization等,非常重要。
計算損失:對於每個訓練批次,使用模型進行前向傳播,計算輸出的預測值,然後使用損失函數(在這裡是交叉熵損失)計算預測值與實際標籤之間的損失。
反向傳播和優化:使用損失計算梯度,然後使用優化器(在這裡是SGD優化器)來調整模型的權重。這部分包括以下程式碼:
optimizer.zero_grad(): 清除之前的梯度,以確保新的梯度能夠正確計算。loss.backward(): 倒傳播梯度,計算損失相對於模型參數的梯度。optimizer.step(): 使用優化器來更新模型的權重。監控訓練進度:使用tqdm庫,顯示訓練的進度條,包括每個epoch的訓練損失和準確度。這有助於實時監控模型的性能。
測試模式和測試數據:在每個epoch結束時,將模型切換到測試模式(model.eval())並使用測試數據進行模型性能的測試。
測試模式才不會去更動到訓練好的權重
儲存權重:在訓練結束時,使用torch.save()函數將模型的權重儲存到文件'model_weights.pth'中。
顯示訓練損失:最後使用show_training_loss函數,將訓練和測試損失繪製成圖表,以幫助可視化模型的訓練過程。
def show_training_loss(loss_record):
test_loss, train_loss = [i for i in loss_record.values()]
plt.plot(test_loss)
plt.plot(train_loss)
plt.title('Result')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['test', 'train
'], loc='upper left')
plt.show()
我們這次把繪製圖形另外定義一個函數,然後在模型訓練完後再呼叫函數把我們的圖畫出來。
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(), # 轉換成張量
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 正規化
])
# 載入資料集
dataset = Setdata(r'images/train', transform)
# 定義訓練集和測試集的比例(這裡設為80%訓練,20%測試)
train_ratio = 0.8
test_ratio = 1 - train_ratio
# 計算訓練集和測試集的數量
total_samples = len(dataset)
train_size = int(train_ratio * total_samples)
test_size = total_samples - train_size
# 使用random_split函數拆分資料集
train_dataset, test_dataset = random_split(dataset, [train_size, test_size])
# 創建訓練集和測試集的資料加載器
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True, num_workers=0)
test_loader = DataLoader(test_dataset, batch_size=128, shuffle=False, num_workers=0)
一般來說訓練擊與測試集常見的比例是 70% 訓練集和 30% 測試集,或者 80% 訓練集和 20% 測試集。而這個比例並不是固定的,它可以根據情況進行調整,如果數據集很大,那麼可以分配更多的數據給訓練集,如 90% 訓練集和 10% 測試集。
# 設定設備
device = torch.device("cpu")
# 創建模型
model = CNN().to(device)
# 定義損失函數和優化器
criterion = nn.CrossEntropyLoss()
optimizer =ㄊoptim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# 訓練模型
train(train_loader, test_loader, model, optimizer, criterion)
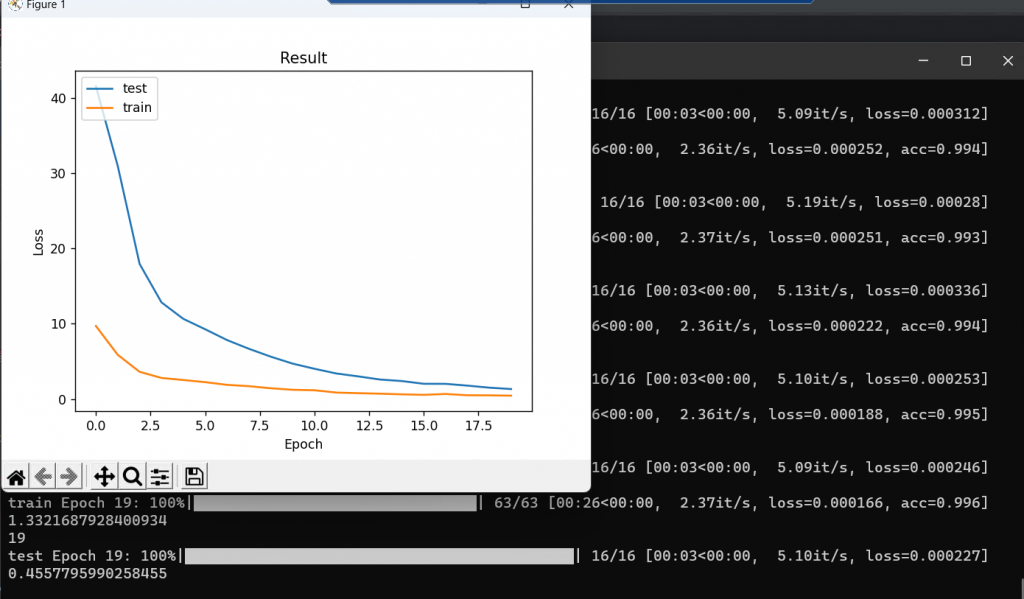
這裡訓練圖是訓練20次的LOSS圖,這裡所使用的總圖片數大約在5200與4800,下面我們來看看320:350的訓練LOSS圖
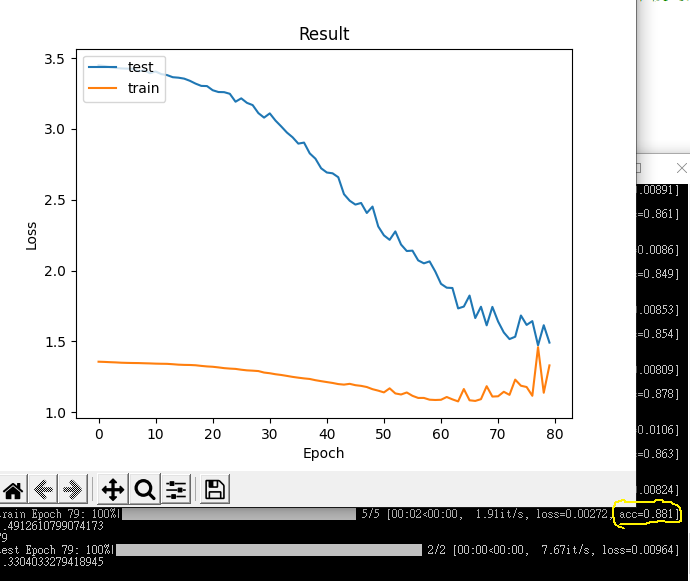
看兩種區別,在320:350模型為了讓LOSS值收斂足足訓練了近80才達成,而即使是這樣準確率也還是比不上數據量大訓練少的模型,也證明了資料數的重要。
以上就是今天內容,大部分都是程式碼,明天我們將會來學讀取權重與最近講的內容延伸,各位明天見!

