機器將人類的自然語言由聲音的音波訊號轉換成相對應的語言與語句的過程。
架構:
①音訊Sound Signal:人類能聽到的聲音頻率。
②基本頻率Fundamental Frequency:一個訊號在1秒內所能產生的週期個數。
③聲波Sound Wave:由振動元的振動所產生的空氣振動,形成空氣一鬆一緊、一緊一鬆的壓力波Pressure Wave。
④聲波的數位化:為了讓機器能瞭解連續性的類比訊號,必須將類比轉換成數據化Analog to Digital。
其中步驟:
Step1.將連續類比的聲波轉換成電壓訊號Voltage Signal,接下來為了行程數據,就要將此訊號作時間(橫軸)與幅度(縱軸)的離散化。
Step2.橫軸的時間離散化
Step3.縱軸幅度的離散化
在一段音框內抽取包括音量、音高、音色等數位式向量的特徵。
音框Frame:音訊所切割而成的小段音訊。
音量Volume:音訊的強度,以音訊的震幅大小來表示。
音高Pitch:以每秒出現的基本周期數來代表。
音色Timbre:音高+音量,在一段音框內不同的頻率與不同頻率上的強度分配,此組合稱之為頻譜。
模式:
1.梅爾倒頻係數Mel-Frequency Cepstral Coefficients(MFCC):一個可以用來代表短期音訊的頻譜。
2.時頻譜Spectrogram:用來表達聲音頻譜。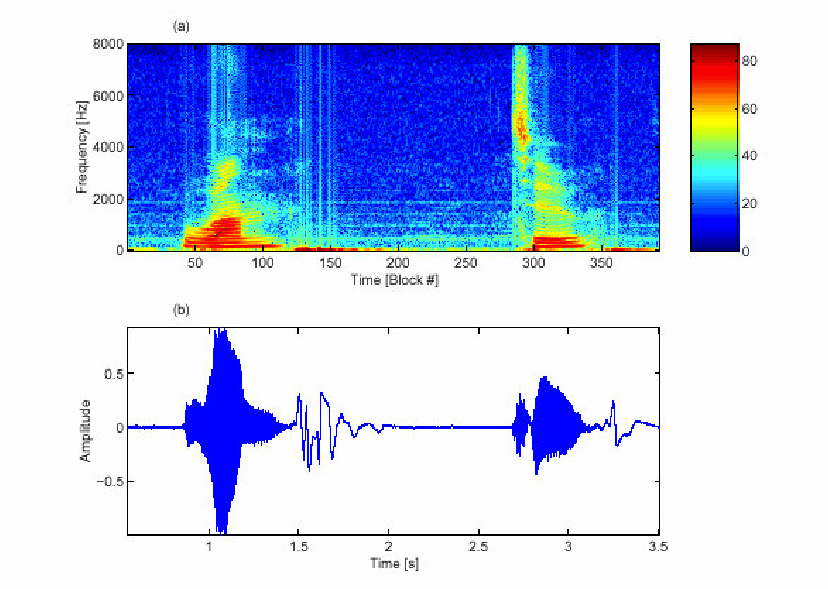
應用:
1.自然語言的互動溝通
2.音樂的辨識、搜尋與生成
3.醫療相關的音訊判斷
4.事件相關音訊的判斷
5.機器預防維修溪觀的判斷
6.環境相關的音訊判斷
架構流程圖: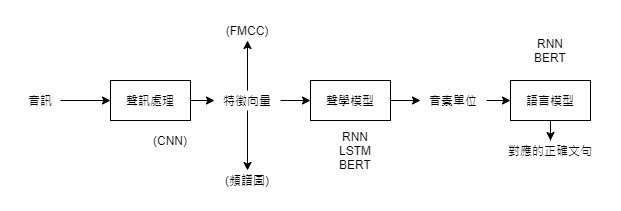 '
'
①聲訊處理:將聲音訊號所轉換成的特徵向量轉至到聲學模型。
②聲學模型Acoustic Model:將特徵向量轉換成音素序列Phonetic。
③語言模型Language Model:接受音素的輸入後,再將音素轉換成單字系列,經分析整合輸出合理的詞句。
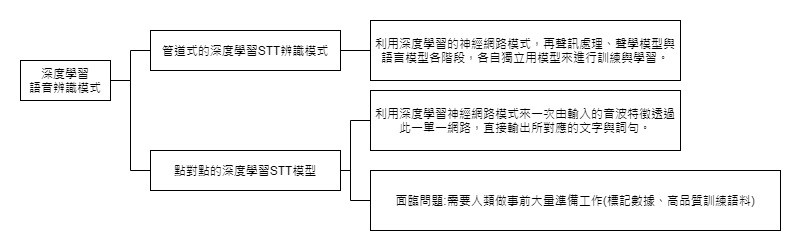
參考來源:人工智慧:概念應用與管理 林東清


 iThome鐵人賽
iThome鐵人賽