Stable Audio是Stability AI開發的第一個用於AI創作音樂的產品。與MusicLM以及MusicGen相似,使用者可以通過輸入prompt來讓Stable Audio創作音樂。
Stability AI早期靠著生成模型Stable Diffusion的工具提供使用者利用AI產生圖像,使用者只要輸入關鍵字後,等待幾秒鐘即可獲得AI圖片,且Stable Diffusion將它的所有程式碼完全免費開源,這代表著所有人都可以依照自身的使用需求來運行Stable Diffusion的程式碼,更可以藉此開發出相關的獨立AI作圖應用。
在繪畫領域獲得成功後Stability AI在2023年推出了Stable Audio讓使用者可以透過它們的模型生成品質可達44.1 kHz的高質量音樂,等同於一般CD的音樂品質。
與前面介紹過的其他Audio Music Generator相比,Stable Audio不但提供非常高品質的音樂,而音樂的本身也是有足夠的音樂水準,其成功可歸功於它背後強大的Audio訓練資料。我們不只一次提及過,在機器學習/深度學習的領域裡,除了模型的訓練以外,最重要的即為訓練用的數據。
Stable Audion所使用的Audio訓練資料,來源是商用音樂資料庫AudioSparx,其不但提供超過19500小時的高品質Audio音樂資料,更提供已經將聲部分軌過的原始檔案,有了這些完整且高品質的訓練數據後,Stable Audio的成功是完全可預期的。
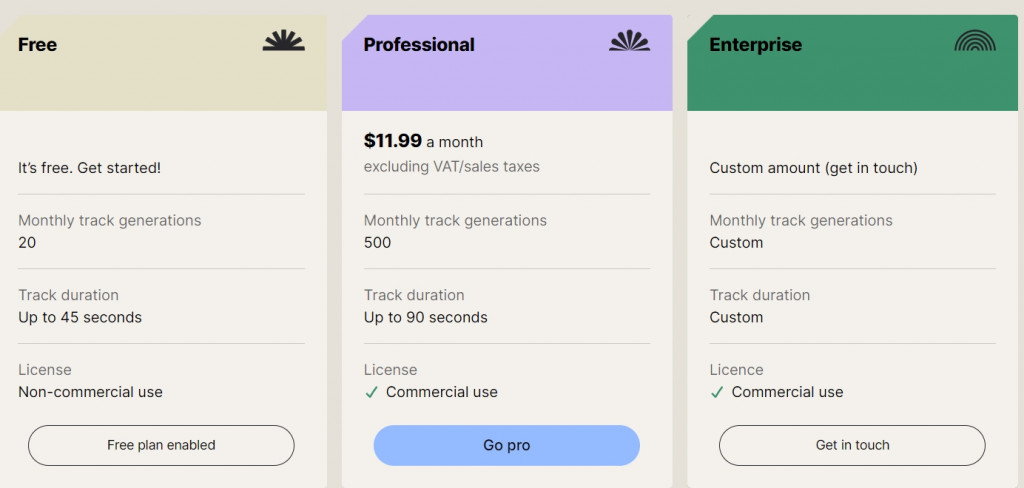
目前Stable Audio提供用戶有限量的免費使用該模型生成,用戶可以輸入關鍵字並且指定音樂長度來做控制:
免費用戶每月可免費生成20次,不可商用寫音樂長度最高支援到到45秒鐘;
Pro付費版則可生成500次最長音樂長度為90秒的音樂,生成的音樂可自由作為商業用途;
企業用戶則可以自行與Stable Audio洽談客製化事宜。