今天我們要來介紹 EyeGaze 資料的處理資料以及如何訓練自己的 EyeGaze model,稍後我們會上傳晚整的成是在這個連結上給大家參考!
一般訓練時舞們都會做 data normalization,那 EyeGaze 也不例外,但他強調的是大家的臉回到同一個位置以及同一個 headpose,這樣會有助於模型學習,較早可見於這一篇
而為什麼一定要做 data normalization,我們可以參考下圖(圖片ref):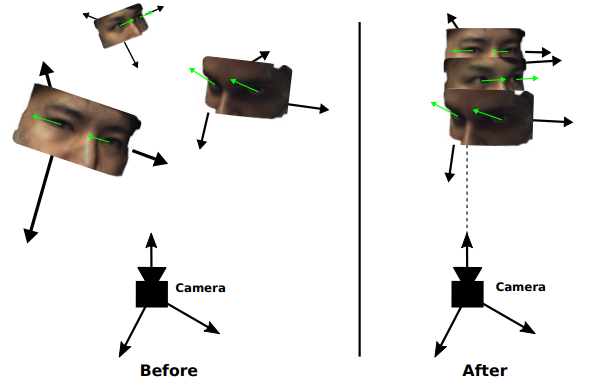
我們可以看到上圖中左邊為一般照片所看到的畫面,此時每個人的Headpose 角度是不一樣的,因此我們的 model 需要更多的樣本才能學會這些差異,那如果我們把他們都移動至相同 Headpose 跟 position 呢? 是不是看起來就比較容易去讓模型比較呢?實務上等同:
我們去預測相較於人臉 EyeGaze 為多少,然後再把 Gaze 根據 Headpose 再做回覆得到真實的 EyeGaze
EyeGaze Normalization 的過程可參考下圖(下圖為一種知名的 Normalize 法):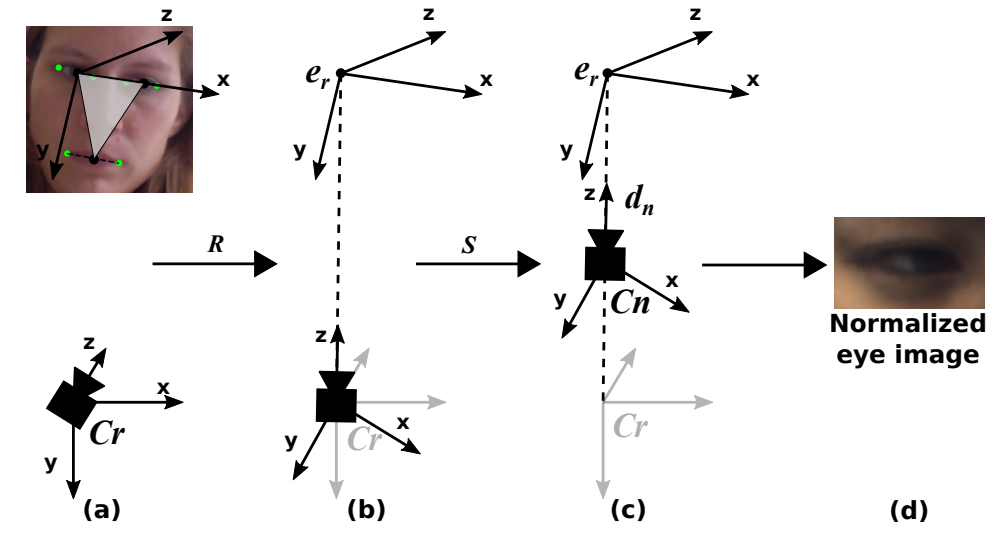
Step.A 我們先算出相較於相機的 Headpose 為多少,這裡以 X, y, Z 來表示 Headpose 資訊( x 為畫面左眼(受試者右眼)中心至右眼中心連線方向,y為兩眼與嘴吧連線成為的三角形平面上垂直於這 x 的方向,z 為垂直這個三角形的方向,並以畫面左眼(受試者右眼)為原點
Step.B 然後我們旋轉相機自己的 x 方向與受試者 x 方向一致,將 z 對準受試者的畫面左眼(受試者右眼)
Step.C 進行縮放,模擬出相同距離拍攝出來的人臉(考量大小以及變形問題
Step.D 成功拿到 Normalize 後的 Gaze 與照片啦~
首先,我們需要準備 EyeGaze 資料集。在這個例子中,我們使用 MPIIFaceGaze 資料集,官方已經把他做了 Normalized 了,對於我們來說就可以直接用!他的資料格式為:
1.normalized face images (448*448 pixels size)
2.2D gaze angle vectors(覺得太奇怪,其實 2D vector 足以表達 3D,你考慮一下 vector 長度是固定的 unit vector 即可!
所以請確保你已經下載並組織好資料集的目錄結構我們就可以來使用。那他原始的為 .mat 格式,可自行轉換成想要的格式喔(我自己通常為求方便觀看我通常轉成 label 是 .csv,image是 .png這樣)!
import os
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
import pandas as pd
# 自定義 EyeGaze 資料集
class EyeGazeDataset(Dataset):
def __init__(self, csv_file, root_dir, transform=None):
self.annotations = pd.read_csv(csv_file)
self.root_dir = root_dir
self.transform = transform
def __len__(self):
return len(self.annotations)
def __getitem__(self, idx):
img_path = os.path.join(self.root_dir, self.annotations.iloc[idx, 0])
image = Image.open(img_path)
eyegaze = self.annotations.iloc[idx, 1:].values
eyegaze = eyegaze.astype('float').reshape(-1, 2)
sample = {'image': image, 'eyegaze': eyegaze}
if self.transform:
sample = self.transform(sample)
return sample
# 資料集路徑及標準化轉換
csv_file = 'path_to_csv_file.csv'
root_dir = 'path_to_dataset_directory'
transform = transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor()])
eye_gaze_dataset = EyeGazeDataset(csv_file=csv_file, root_dir=root_dir, transform=transform)
# 資料集的迭代器
dataloader = DataLoader(eye_gaze_dataset, batch_size=32, shuffle=True)
在上述程式碼中,我們簡單定義了一個 EyeGazeDataset 類別,它繼承自 PyTorch 的 Dataset。我們透過這個類別來讀取資料集,並使用 transforms 進行影像的標準化轉換。
接下來,我們將建立眼神檢測模型。在這個例子中,我們使用一個簡單的卷積神經網路 (CNN)。
import torch.nn as nn
import torch.optim as optim
# 定義眼神檢測模型
class EyeGazeModel(nn.Module):
def __init__(self):
super(EyeGazeModel, self).__init__()
# 定義模型結構,這裡使用簡單的 CNN
# 只要確定你的 model 可以讀進 224*224 大小的 image,並且輸出 2D gaze 即可
def forward(self, x):
# 定義前向傳播過程
# 初始化模型、損失函數和優化器
model = EyeGazeModel()
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
在這個例子中,我們只是定義了模型的外殼,實際的模型結構和前向傳播過程大家可以自行拿一個簡單的 CNN 模型(只要滿足 code 中描述即可)即可,那我們就不在這裡贅述。
接下來,我們將模型進行訓練。
# 訓練模型
num_epochs = 10
for epoch in range(num_epochs):
for batch in dataloader:
images, eyegaze = batch['image'], batch['eyegaze']
outputs = model(images)
loss = criterion(outputs, eyegaze)
# 反向傳播和優化
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item()}')
最後,我們可以使用訓練好的模型進行眼神檢測的測試。
# 測試模型
model.eval()
with torch.no_grad():
for batch in dataloader:
images, eyegaze = batch['image'], batch['eyegaze']
outputs = model(images)
# 進行後續處理,如可視化、評估等
1.Sugano, Yusuke, Yasuyuki Matsushita, and Yoichi Sato. "Learning-by-synthesis for appearance-based 3d gaze estimation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2014.
2.Zhang, Xucong, Yusuke Sugano, and Andreas Bulling. "Revisiting data normalization for appearance-based gaze estimation." Proceedings of the 2018 ACM symposium on eye tracking research & applications. 2018.
3.Zhang, X., Sugano, Y., Fritz, M., & Bulling, A. (2017). MPIIGaze: Real-World Dataset and Deep Appearance-Based Gaze Estimation. IEEE Transactions on Pattern Analysis and Machine Intelligence.

