歡迎回到我們的 30 天人臉技術探索之旅!我們已經知道要建立深度學習系統時一般來說我們需要訓練出自己的 Model,而要訓練出自己的 model 我們就需要有資料集,因此建立一個豐富且多樣的資料集對於訓練準確的視線檢測模型至關重要。當然如果網路上有得下載是最好,但有時候你可能需要自己收集自己的資料集(無論是 for 測試用或者自己的環境與網路上的資料相差太多),像是之前的 Face detection、Facail Landmark 等等我們可以直接請人(實驗室任勞任怨學弟妹或者善心學長姐)直接在照片框一個框(ex.使用Labelme)或者直接在上面點上關鍵點給 Facial landmark 訓練。那我們要如何標記 EyeGaze 呢?這可不像是一個可以簡單從 2D 照片上直接點出3D標記的 task 呀!今天,我們將深入探討如何有效地收集 Eye Gaze 資料集。
我們仔細想一下我們 EyeGaze 要收集甚麼資料?基本上包含以下兩者:
1.人眼部位照片 or 人臉照片(端看你設計的 EyeGaze 模型是喜要輸入何者?兩者比較可以參閱前兩天
2.EyeGaze 標記 (2D 點在螢幕上 or 3D視線方向
以上中的 1. 我們大概沒有任何問題,僅需要想好你的 EyeGaze 是設計要拿哪一種為輸入的就好,問題出現在2。
以 EyeGaze 標記的定義中分成兩種: 2D 與 3D 標記:
要收集 2D 標記,最常見的是收集受試者現在在看 平板 or 平面 上哪一點! 因此我們要做的事情其實是需要知道相機與平板上的點的關係即可,可以利用 camera calibration chessboard 等方法得到關係,但你可能會有疑問說如果是平板上的鏡頭怎麼看到平板上的點呀?我們可以利用鏡子得反射來解決這個點喔!邏輯上是放一個 chessboard 在鏡子上利用 extrinsic calibration 推估得到鏡子法向量,然後鏡頭對鏡子拍攝出觀測點的鏡像(ㄧ樣用 chessboard 或者 aruco 去做 extrinsic calibration 推估)的座標,然後這個座標去根據鏡子法向量鏡射得到原本位子!另外也可以不用知道鏡子得法向量,詳細做法可以參考這個
3D gaze vector可以由在 camera 座標系上的點剪去人眼或者人臉位置即可得知,觀測點坐標與 2D 依樣,人眼位置其實可以放一個chessboard板子在人眼前面去做 extrinsic calibration推估出來!
以下為 EyeGaze dataset 所需要的收集步驟:
1. 定義收集目標
在開始收集資料之前,我們需要明確我們的收集目標。這可能包括特定使用情境下的眼神行為,例如閱讀、觀看影片、操作介面等。確定收集目標將有助於更好地設計實驗和確保資料集的多樣性。另外我們也需要確定我們要在哪裡收集資料集(室內 or 室外)
2. 選擇合適的設備
眼神檢測通常需要使用眼動追蹤設備,這些設備能夠準確地記錄使用者的視線軌跡。一些常見的眼動追蹤設備包括:
屏幕型眼動儀: 這種設備通常放置在使用者面前的顯示器上,可以實時記錄使用者在螢幕上的注視點。
穿戴式眼動儀: 這類設備可以直接放在使用者的眼睛上,提供更自然的眼動數據,適用於一些特定場景,如行為研究。
軟件模擬: 在一些情況下,可以使用軟件模擬生成的眼動數據。這種方法的優勢在於成本低,但缺點是缺乏真實性。
3. 實驗設計
制定一個明確的實驗計劃是資料收集的關鍵。這包括:
任務設計: 根據收集目標,設計不同的任務,如閱讀、觀看影片、互動等。
實驗環境: 確保實驗環境的一致性,減少外部因素的干擾。良好的照明和適當的螢幕設置是至關重要的。
受試者選擇: 選擇受試者以確保資料的多樣性。考慮到年齡、性別、文化背景等因素。
4. 資料收集
在實施實驗計劃之後,開始進行資料收集。這包括:
實施眼動追蹤: 根據選定的設備和實驗設計,記錄使用者的眼動數據。
同步其他數據: 如果可能,同步記錄其他相關的數據,如視頻畫面、生理數據(心率、皮膚電導度等)。
5. 資料後處理
完成資料收集後,進行資料的後處理是必不可少的:
校準眼動數據: 校準眼動數據以確保準確性,這可能涉及到映射到特定螢幕坐標或虛擬空間。
去除雜訊: 清理任何可能的眼動數據雜訊,以確保模型訓練的穩定性。
Dataset 的收集我們主要可以分成兩種,一種是 Fixed-Head pose, 另一種 Non-Fixed head based:
上述中的 1. 在後處理人跟相機關係上較為簡單,因為人臉在環境中的位置一直保持不變(因此只需要考慮相機自己的變化即可) 而 2. 需要較複雜的工具來即時算出人臉位置或者直接固定相機在臉上(ex.眼下)
考量到我們主要希望是收集的資料照片為全臉影像因此較不希望收集到的照片有奇怪的裝置可能會影響到 Model 學習,因此我們主要不會考慮臉上會拍到相機的做法。
以下我們來介紹 Fixed-Head pose 中非常知名的 Dataset -- Columbia Gaze Data Set,為哥倫比亞大學在2013年提出的。他會用到的裝置如下圖: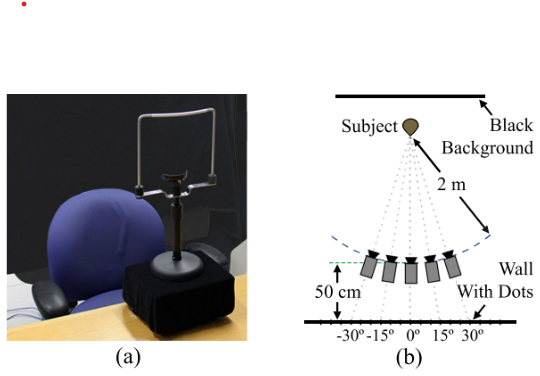
其中左邊為受試者坐的位置,上面有一個支架可以用來固定受試者(Subject)頭的位置。右邊為展示為作者當初讓受試者(Subject)坐在一個黑色的背景前然後固定頭的位置來看向牆上事先標記好的點(共有21個點)。考慮到這樣頭的角度變化程度不多,因此作者當初決定同時多擺一些5個鏡頭(分別用以收集 0度、+-15度、+-30度的頭)一起來拍受試者。最後作者一共拍攝了 56 位受試者,總共照片數有
21個點56位受試者5個鏡頭位置 = 5880 張照片
拍下來的照片如下圖:
這個方法真的非常穩定且好用,當然你看到這裡可能會想到:
1.既然角度可以變化,那像光線、年齡、人可以變化多一點嗎?
2.只有5台攝影機感覺太少,要不在更多一點?
3.那個臉前面的框框感覺還是太粗操,是否可以移掉但還是有固定頭?
那以上這樣確實還真有人想到! ETH 這間大學在 ECCV 2020 提出的 ETH-XGaze還就真的解決了這些訴求,他的裝置如下圖:
我們可以看到他一口氣提升至 18 台相機(甚至有兩台收集的照片可以做 stereo 3D Face reconstruction,有興趣可以參考這個),可參考下圖:
有4個 light box 可以改變光線,改成使用脖子後的裝置固定位置,以及找了上百人來收集!另外為了追求彈性,把她不固定點在牆上而是改用投影螢幕來畫點!收集的結果如下示例:
而這樣 ETH 他們一共收集了上百萬張照片,也是目前為止最大的 EyeGaze 資料集!
有效地收集 Eye Gaze 資料集是視線檢測技術研究的重要一環。透過謹慎的實驗設計和後處理,我們可以建立高質量的資料集,為眼神檢測模型的訓練提供堅實基礎。我們今天透過了介紹知名 Dataset 收集的方式大家理解了如何收集自己的資料集!歡迎明晚大家再次回來!
1.Labelme object detection 資料標註教學
2.Hansen, D. W., & Ji, Q. (2010). In the eye of the beholder: A survey of models for eyes and gaze. IEEE Transactions on Pattern Analysis and Machine Intelligence.
3.Bulling, A., & Gellersen, H. (2010). Towards gaze‐aware computers. Computer Science Review.
4.Smith, Brian A., et al. "Gaze locking: passive eye contact detection for human-object interaction." Proceedings of the 26th annual ACM symposium on User interface software and technology. 2013.
5.Zhang, Xucong, et al. "Eth-xgaze: A large scale dataset for gaze estimation under extreme head pose and gaze variation." Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part V 16. Springer International Publishing, 2020.
6.Stereo 3D reconstruction

