通常可以分為二元分類(Binary Classification)和多類別分類(Multiclass Classification)兩大類
邏輯回歸(Logistic Regression):用於二分類或多分類問題,通過將線性回歸模型應用於邏輯函數中,將輸入映射到概率值。
支持向量機(Support Vector Machines,SVM):用於二分類或多分類問題,通過找到最佳的超平面或決策邊界,將不同類別的數據點分開。
決策樹(Decision Trees):通過基於特徵的條件進行分割,構建一棵樹形結構,用於分類或回歸。
隨機森林(Random Forests):通過結合多個決策樹進行投票或平均,提高分類或回歸的準確性和穩定性。
KNN近鄰算法(K-Nearest Neighbors,KNN):根據鄰近的K個樣本的標籤進行分類,其中K是一個超參數。
朴素貝葉斯(Naive Bayes):基於貝葉斯定理和特徵之間的獨立性假設,計算不同類別的概率並進行分類。
卷積神經網絡(Convolutional Neural Networks,CNN):用於圖像分類和處理,通過卷積和池化層進行特徵提取和學習。
循環神經網絡(Recurrent Neural Networks,RNN):用於序列數據的分類,具有記憶單元可以處理時序信息。
梯度提升樹(Gradient Boosting Trees):通過逐步擬合殘差,結合多個弱學習器來提高分類或回歸的準確性。
多層感知器(Multilayer Perceptron,MLP):一種基於神經網絡的分類器,包含多個隱藏層和非線性激活函數。
Step1:計算距離(歐氏距離)
距離越小代表性質越相近 (理想值為 0)。
Step2:選取距離較近的 K 個鄰居
Step3:跟哪個群的相似值較多就歸類在哪
# (一) 引入模組
from sklearn.neighbors import KNeighborsClassifier
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn import metrics
# (二) 資料準備
'''
預測的目標(y值),以及用來預測的特徵(X值)
花萼及花瓣的長度及寬度當作特徵(X值),來預測鳶尾花的種類(y值)。
房子的坪數、地區、屋齡、樓高等等的資訊,這些就是所謂的特徵(X值),房價就是目標(y值)
'''
iris = datasets.load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=1)
# (三)模型建立
'''
n_neighbors : K
weights: 'uniform' / 'distance' / 其他
algorithm: 'auto' / 'brute' / 'kd_tree' / 'ball_tree'
p: 1→曼哈頓距離 / 2→歐基里德距離 / 其他: 明氏距離
'''
clf = KNeighborsClassifier(
n_neighbors=3, p=2, weights='distance', algorithm='brute')
clf.fit(X_train, y_train)
# (四)預測
clf.predict(X_test)
# (五)準確度評估
clf.score(X_test, y_test)
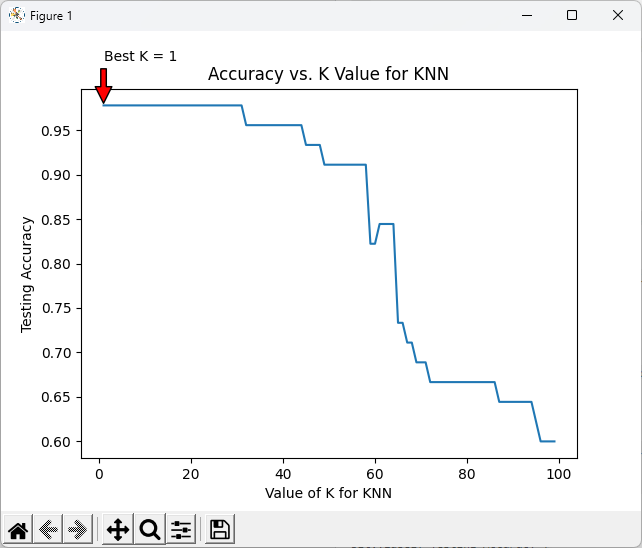
# (六)如何找尋適合的K值
accuracy = []
for k in range(1, 100):
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
accuracy.append(metrics.accuracy_score(y_test, y_pred))
k_range = range(1, 100)
plt.plot(k_range, accuracy)
# 找到最佳K值
best_k = np.argmax(accuracy) + 1 # 因为索引从0开始,所以要加1
best_accuracy = max(accuracy)
# 在图上添加注释
plt.annotate(f'Best K = {best_k}', xy=(best_k, best_accuracy), xytext=(best_k, best_accuracy + 0.05),
arrowprops=dict(facecolor='red', shrink=0.05),)
plt.xlabel('Value of K for KNN')
plt.ylabel('Testing Accuracy')
plt.title('Accuracy vs. K Value for KNN')
plt.show()


 iThome鐵人賽
iThome鐵人賽