大家安安,雖然說已經介紹過 ETL 了,但我覺得可以和大家談談什麼是好的 ETL 流程,以及我們該如何建立一個好的 ETL 流程,當然好不好這件事有點主觀,我會以我自己的觀點作分析,介紹一些相對好的做法。
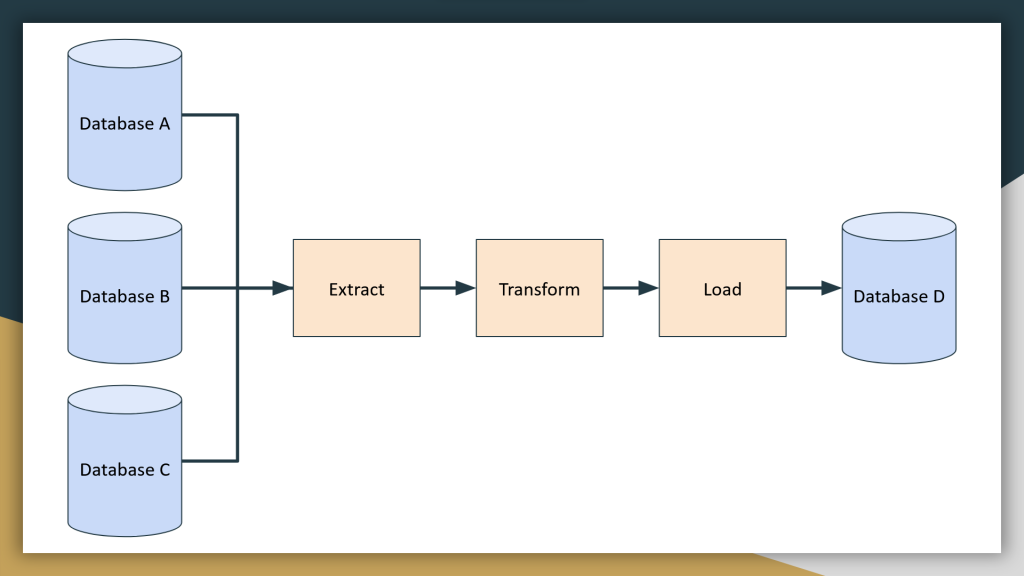
ETL (Extract, Transform, Load) 是一種資料處理過程,主要用於從各種資料源抽取資料 (Extract)、將資轉換為需要的格式 (Transform),然後載入到目標資料庫或資料倉儲 (Load)。
設計良好的 ETL 流程可以確保資料的準確性、完整性和一致性,並且可以有效地處理大量資料。
現在市面上其實有很多 ETL 工具可以直接使用,或許不用自己開發就可以搭建出很高效的 ETL 流程。
在設計 Data Pipeline/ETL 系統時,通常需要注意以下四點:
在 Data Pipeline 中會有很多支 ETL 程式,而開發一個新的 ETL 就和其他的程式開發一樣,會有固定且獨立的開發流程:
ETL 技術是 Data Pipeline 中最基本的小程式,可以幫助我們將來自不同來源的資料整合到資料倉儲中,並保證資料的品質、一致性和效能。
順帶一提,我們公司先前有使用過 Hevo 來建立 ETL 程式,我自己覺得蠻直覺的,這類的工具可以讓你的開發過程更簡化,簡化的部分在於環境的設定不用那麼複雜,只需要設定權限 token 就可以串好整個流程,也可以直接在網頁上進行資料清理的程式碼撰寫,很方便。
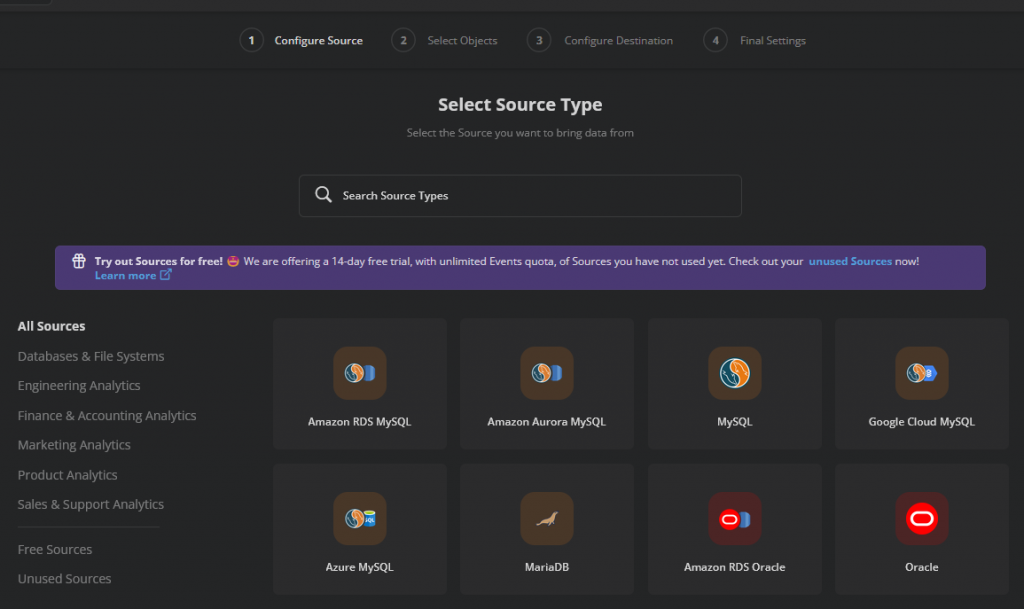
我可以在網頁內只用四個步驟就建立好一個 ETL 程式,很方便吧~~
(Configure Source, Select Objects, Configure Destination and Final Settings)
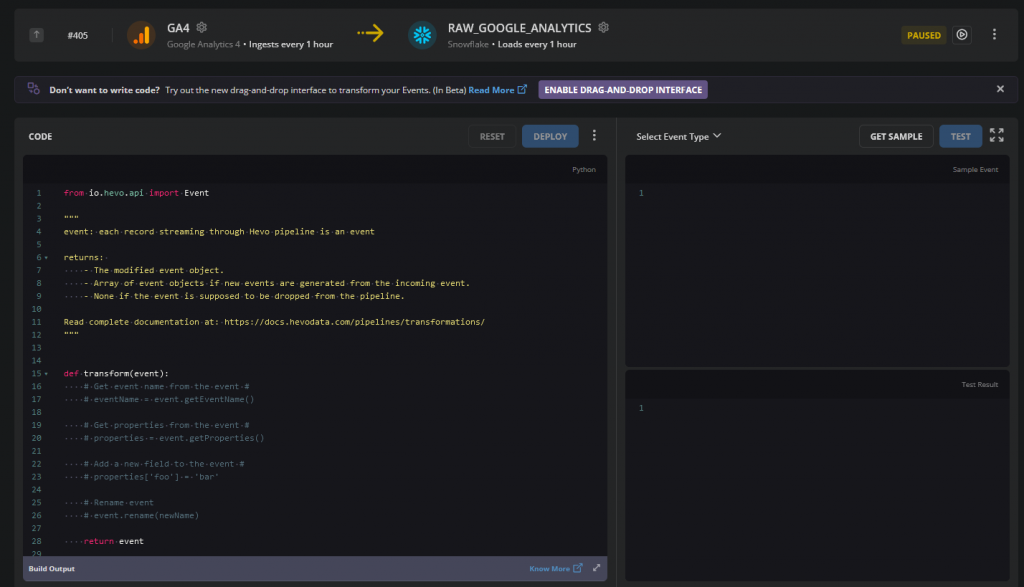
也可以在網頁中直接撰寫資料轉換與清理的程式碼 (Based on Python)
Hevo 也有提供免費仔額度,雖然免費版的功能和能連接到的資料源比較少,但我覺得很堪用!
我自己覺得比自己開發 ETL 還順手,市面上也有很多類似的工具,大家可以依照自己的喜好去選擇。
Bryan Yang - Data Pipeline 101(一) — 什麼是 Data Pipeline
Bryan Yang - Data Pipeline 101(四) — 管線系統設計與開發 — 功能面
Bryan Yang - Data Pipeline 101(八) — ETL Job 開發流程
Hevo
Hevo - Pipeline


 iThome鐵人賽
iThome鐵人賽